简介Introduction
作者:孙老师
说明:本课程为孙老师的
Python的基础教程讲义,主要面向10岁以上的学生群体,课程的设计参考了电子学会的Python考级的设定,内有大量的计算机和编程的基础。帮助有意向去参与考级的学生能顺利通过每一级考试。 如果你是一名大学生,或者你已经掌握了其它编程语言,想学习Python,那么本课程并不适合你。
引言
1. 什么是编程
编程的就是让计算机代码解决某个问题,对某个计算体系规定一定的运算方式,使计算体系按照该计算方式运行,并最终得到相应结果的过程。通俗地去理解,就是用某种计算机程序设计语言编写一个程序让计算机帮助我们完成某件工作、达到某种目的或解决某个问题。当程序员们把程序有机地结合到一起之后,再做一些深度的加工,就形成了我们常说的软件。
在互联网技术高速发展的今天,由计算机编写的程序或者软件已经和我们的生活方方面面有了很大的关系,对社会的发展起到很大的推动作用。比如,为了帮助人们更加快速地处理工作中的文档,Microsoft公司开发了Office办公软件;为了娱乐,很多游戏公司开发了各种各样的游戏软件,像大家比较熟悉的王者荣耀、吃鸡等;又或是为了满足远程的沟通需求,QQ、微信、钉钉等等不同的通讯软件也被开发了出来......
2. 计算机编程语言
计算机编程语言是程序设计的最重要的工具,它是指计算机能够接受和处理的、具有一定语法规则的语言。从计算机诞生,计算机语言经历了机器语言、汇编语言和高级语言几个阶段。
机器语言
机器语言指令是一种二进制代码,由操作码和操作数两部分组成,是机器能直接识别的程序语言或指令代码,无需经过翻译,每一操作码在计算机内部都有相应的电路来完成它,或指不经翻译即可为机器直接理解和接受的程序语言或指令代码。
它大概的样子如下(纯粹由孙老师胡乱编写的,理解意思即可)
1011100111010001011010101001011010100001010001000101011001010101010
0111000101001001011101100101101010101010101010010101010100101001101
1011110101111110101000001101010101011000000001110101011001011011101
0000111111100010100010001111010010001110110000110101000101011001001
汇编语言
汇编语言, 即第二代计算机语言,属于低级语言,用一些容易理解和记忆的缩写单词来代替一些特定的指令,例如:用ADD代表加法操作指令,SUB代表减法操作指令,MOV代表变量传递等等。然而计算机的硬件并不认识字母符号,这时候就需要一个专门的程序把这些字符变成计算机能够识别的二进制数或机器语言。但是由于各个机器的指令集是不同的,所以汇编语言要和特定的机器指令集一一对应对能正常运行。
下列是一段汇编语言的例子:
MOV AX, X
MOV BX, OFFSET X
MOV CX, 9
L1: INC BX
INC BX
CMP AX, [BX]
JAE L2
XCHG AX, [BX]
L2: LOOP L1
MOV Y, AX
高级语言
高级语言是独立于机器的一种面向过程或者面向对象的计算机编程语言, 语法结构参照了数学语言而设计的, 读起来近似于日常的会话。 比如要把两个变量的值相加,用高级语言的表达为 var1 + var2。 所以高级语言比低级语言更具有可读性, 更容易被理解。
目前常见的高级语言有: C语言、 C++、 VB、 C#、 Java、 Python、 Go lang、 Delphi, PHP等等。
下列是一段高级语言的例子(Python):
_lenght = float(input("Please input the lenght of Square:"))
_width = float(input("Please input the width of Square:"))
_area = _length * _width
print("The area of the Square is %.2f" %_area)
高级语言并不能直接被机器执行,而要经过一系列的编译或者解释的过程,转换成机器能够直接理解的机器语言之后,才能被运行。
引言
1. 什么是编程
编程的就是让计算机代码解决某个问题,对某个计算体系规定一定的运算方式,使计算体系按照该计算方式运行,并最终得到相应结果的过程。通俗地去理解,就是用某种计算机程序设计语言编写一个程序让计算机帮助我们完成某件工作、达到某种目的或解决某个问题。当程序员们把程序有机地结合到一起之后,再做一些深度的加工,就形成了我们常说的软件。
在互联网技术高速发展的今天,由计算机编写的程序或者软件已经和我们的生活方方面面有了很大的关系,对社会的发展起到很大的推动作用。比如,为了帮助人们更加快速地处理工作中的文档,Microsoft公司开发了Office办公软件;为了娱乐,很多游戏公司开发了各种各样的游戏软件,像大家比较熟悉的王者荣耀、吃鸡等;又或是为了满足远程的沟通需求,QQ、微信、钉钉等等不同的通讯软件也被开发了出来......
2. 计算机编程语言
计算机编程语言是程序设计的最重要的工具,它是指计算机能够接受和处理的、具有一定语法规则的语言。从计算机诞生,计算机语言经历了机器语言、汇编语言和高级语言几个阶段。
机器语言
机器语言指令是一种二进制代码,由操作码和操作数两部分组成,是机器能直接识别的程序语言或指令代码,无需经过翻译,每一操作码在计算机内部都有相应的电路来完成它,或指不经翻译即可为机器直接理解和接受的程序语言或指令代码。
它大概的样子如下(纯粹由孙老师胡乱编写的,理解意思即可)
1011100111010001011010101001011010100001010001000101011001010101010
0111000101001001011101100101101010101010101010010101010100101001101
1011110101111110101000001101010101011000000001110101011001011011101
0000111111100010100010001111010010001110110000110101000101011001001
汇编语言
汇编语言, 即第二代计算机语言,属于低级语言,用一些容易理解和记忆的缩写单词来代替一些特定的指令,例如:用ADD代表加法操作指令,SUB代表减法操作指令,MOV代表变量传递等等。然而计算机的硬件并不认识字母符号,这时候就需要一个专门的程序把这些字符变成计算机能够识别的二进制数或机器语言。但是由于各个机器的指令集是不同的,所以汇编语言要和特定的机器指令集一一对应对能正常运行。
下列是一段汇编语言的例子:
MOV AX, X
MOV BX, OFFSET X
MOV CX, 9
L1: INC BX
INC BX
CMP AX, [BX]
JAE L2
XCHG AX, [BX]
L2: LOOP L1
MOV Y, AX
高级语言
高级语言是独立于机器的一种面向过程或者面向对象的计算机编程语言, 语法结构参照了数学语言而设计的, 读起来近似于日常的会话。 比如要把两个变量的值相加,用高级语言的表达为 var1 + var2。 所以高级语言比低级语言更具有可读性, 更容易被理解。
目前常见的高级语言有: C语言、 C++、 VB、 C#、 Java、 Python、 Go lang、 Delphi, PHP等等。
下列是一段高级语言的例子(Python):
_lenght = float(input("Please input the lenght of Square:"))
_width = float(input("Please input the width of Square:"))
_area = _length * _width
print("The area of the Square is %.2f" %_area)
高级语言并不能直接被机器执行,而要经过一系列的编译或者解释的过程,转换成机器能够直接理解的机器语言之后,才能被运行。
Python简介
Python由荷兰数学和计算机科学研究学会的吉多·范罗苏姆于1990年代初设计,作为一门叫做ABC语言的替代品; 是一门简单,易学, 开源的高级语言。
- 学习难度低,不需要太高的基础
- 解释型语言,可移植性高,不需要考虑机器的差异
- 代码规范性高,可读性强
- 面向对象语言,函数式编程
- 可粘合其它语言开发的系统,被称作“胶水语言”
- 生态圈强大,可应用的领域有软件开发、后端开发、数据科学、人工智能、机器学习、数据采集等
在正式学习之前, 给各位同学提几个建议
- 学习过程中,尽量用英语表达各种输出
- 多做练习
- 不要怕犯错,学会理解解释器抛出的各种异常信息
- 遇到问题时,先自己想办法找解决方案
安装Python
在开始学习Python编程之前,首先要在自己的计算机上安装Python的解释器环境。 Python的解释器有好多种,如IDLE、 VS Code、 Pycharm, Jupyter NoteBook等等。这里我们选择使用官方提供的解释器IDLE做为我们学习Python的环境。
Windows系统
Python的官方网站为python.org, 在登录之后,点击Download,并选择Windows。
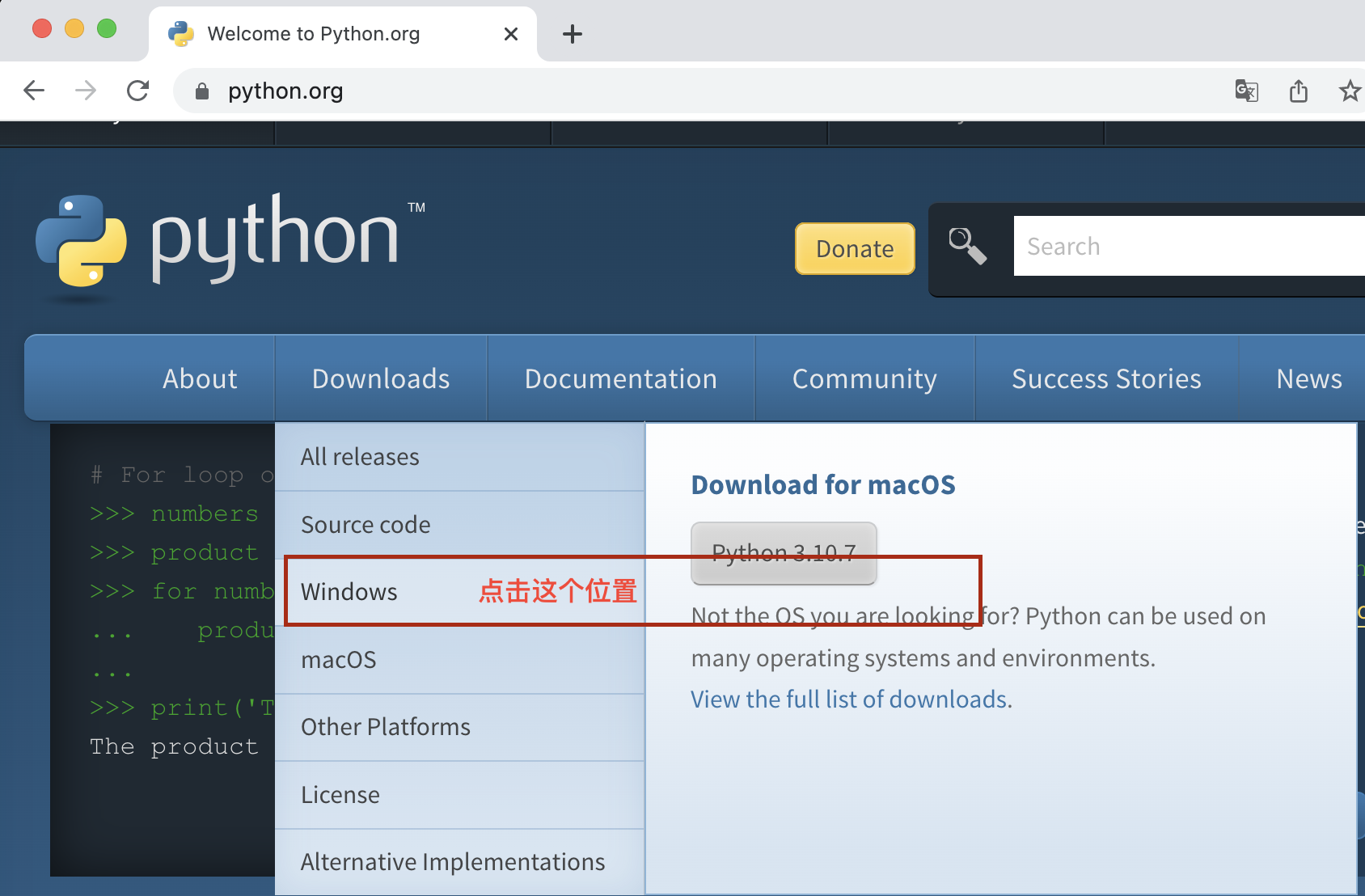
这里我们选择Python3.x版本, 因为2.0版本已经不再更新维护,未来3.0版才是主流版本。
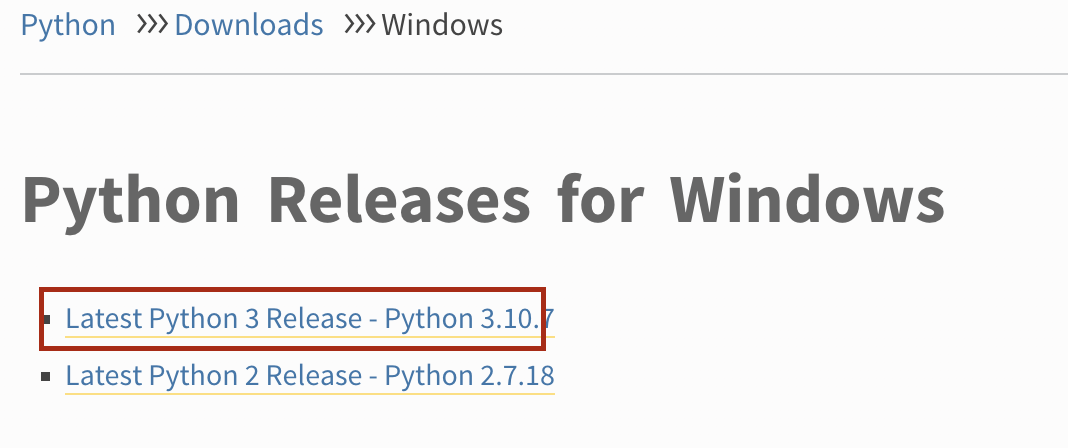
点击进入下一个页面之后,找到Files部分, 根据自己系统的版本选择32-bit还是64位的安装包。
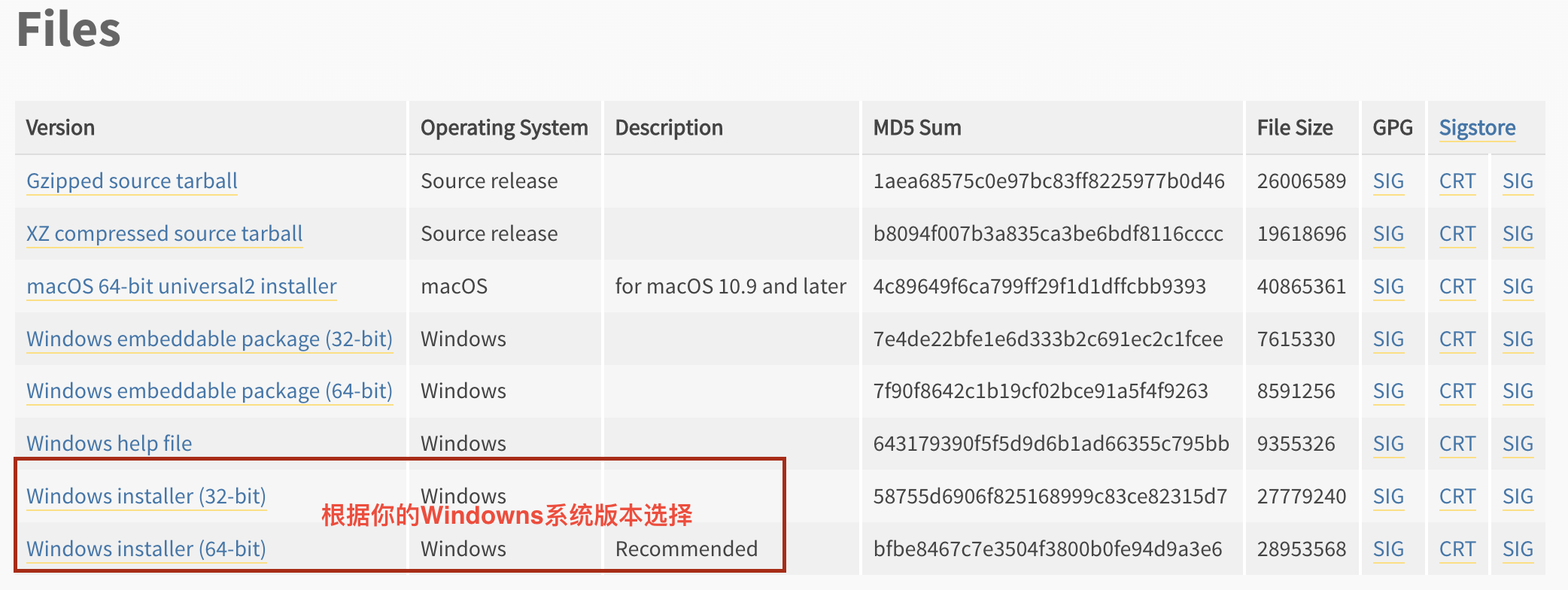
这里也提供了两个安装包的下载链接,可以点击下载:
如何查看自己计算机系统版本是32位还是64位?
在计算机桌面下方的工具栏中点击开始菜单,在Windows系统文件夹下找到控制面板,并打开:在控制面板里,依次点击【系统和安全】->【系统】,就能打开系统信息面板查看自己系统的信息。
下载好Python的编译器安装文件之后,双击打开Python环境的安装向导,选择自定义安装,切记一定要勾选“Add Python 3.X to PATH”,否则需要手动添加环境变量,会比较麻烦。
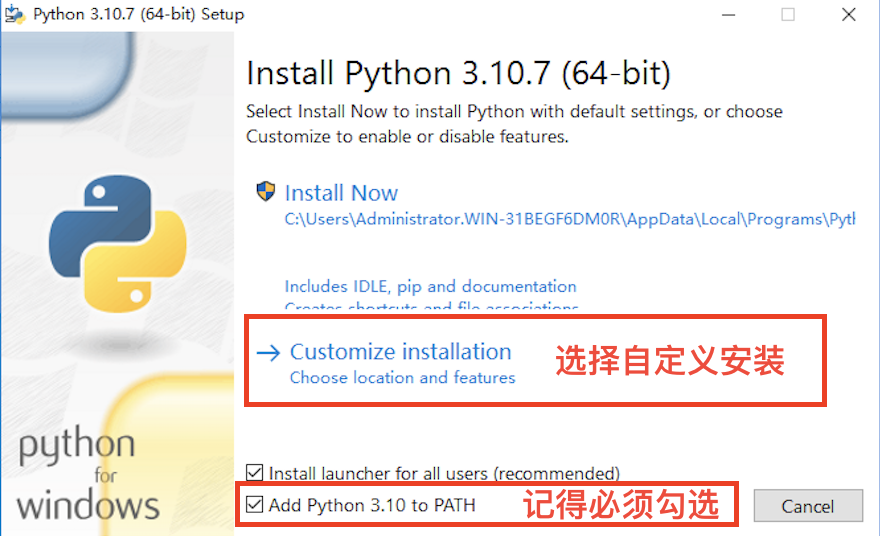
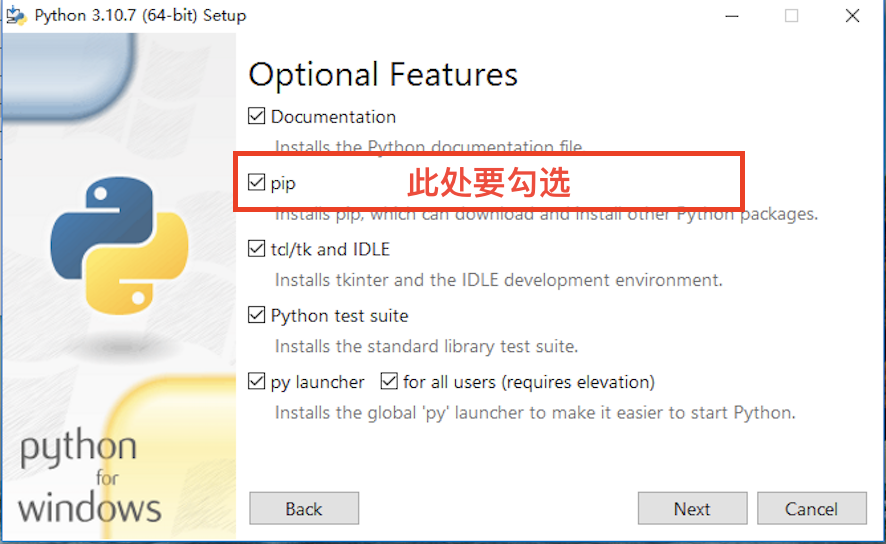
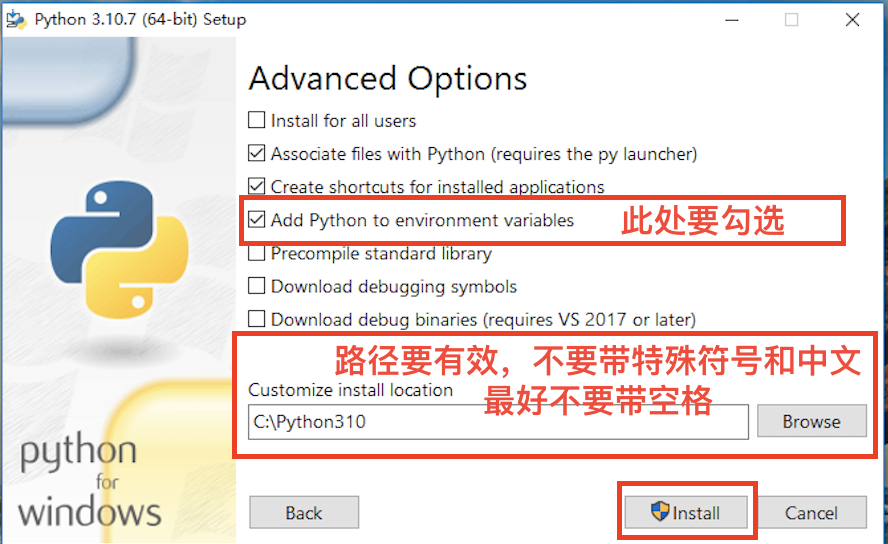
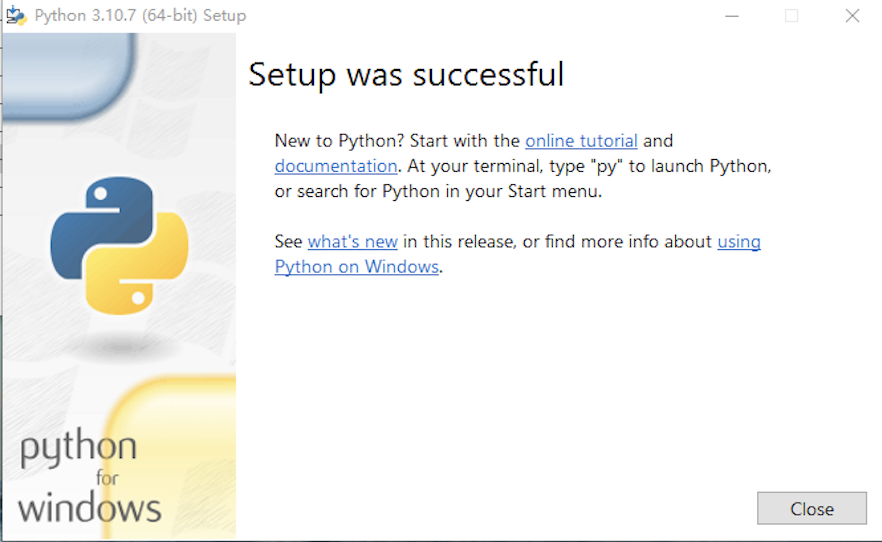
安装完成之后,打开Windows的命令提示符或者PowerShell, 输入python -V或者python --version,如果返回了Python解释器的版本,例如“Python 3.10.7”, 说明安装已经成功。
MacOS环境
MacOS系统是自带Python 2版本的,但是我们需要学习的是Python 3版本,可以参考上面的方法,在官方的下载页面找到对应的版本下载,并安装即可。
需要注意的是,在MacOS的终端直接执行python,调用的是Python 2版本的解释器。想要调用Python 3,必须输入python3。
第一个Python程序: hello, world
上一章节,我们了解了Python的特性和生态,也学会了如何在自己的计算机上安装Python的官方解释器。接下来我们正式开启Python编程的学习。
但:
所有的代码编写必须都要用英文输入法!!!
所有的代码编写必须都要用英文输入法!!!
所有的代码编写必须都要用英文输入法!!!
重要的事情说三遍;除了字符串的内容,所有的编程语言必须用英文输入法编写代码,包括包围在字符串左右两边的引号(单引号和双引号)。
IDLE
我们要使用的集成开发环境是官方提供的IDLE,在正式学习之后,要知道该怎么打开它。
点击 【开始】 菜单,找到安装的 【Python 3.x】 文件夹,点击 【IDLE】 打开它:
如下图,我们可以看到这个简单甚至简陋的Python自带的IDLE的界面;它会在本教程伴随我们一直到最后。
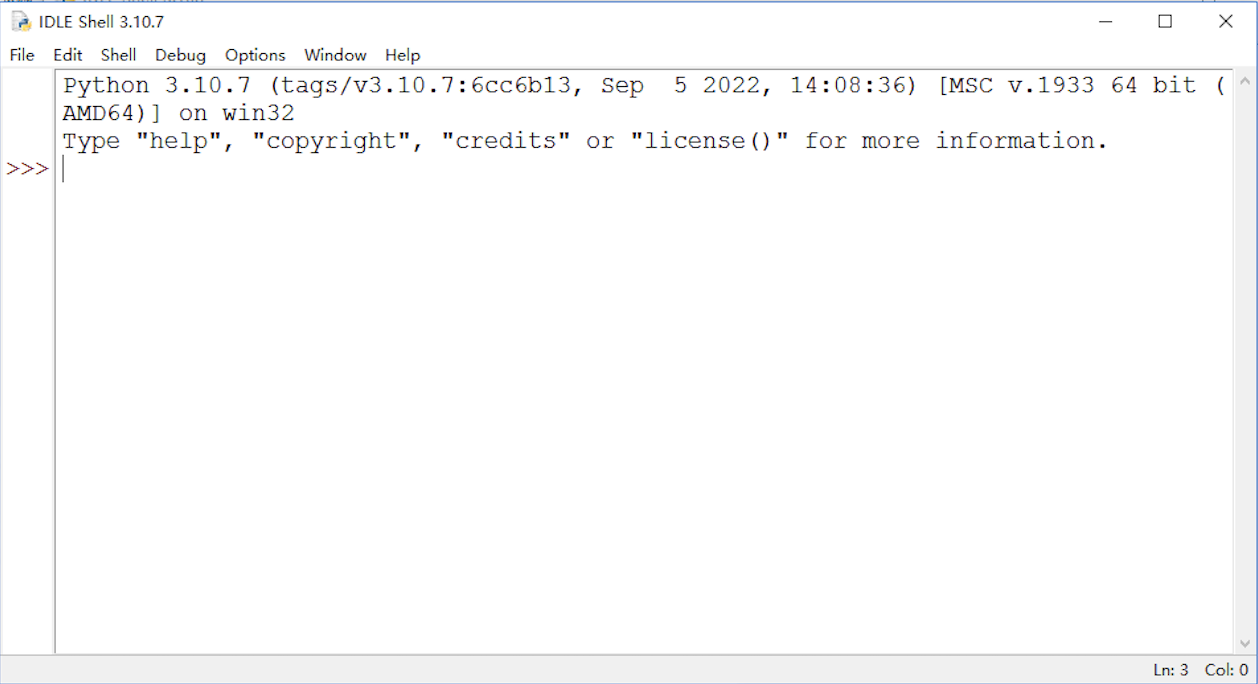
从IDLE的界面,我们可以看到Python的版本信息以及当前的运行环境信息,同时也有一些提示命令。
在上述信息的下方,我们看到>>>这样的符号,这个是Python语句输入的提示符,它的后面会有一光标在不停地闪烁,表示我们在该位置可以输入命令或者代码。
hello, world
几乎在学习所有编程语言的最初,都会让我们先学会写一个简单的程序输出hello, world这样一句话,因为这段代码是伟大的丹尼斯·里奇(C语言之父,和肯·汤普森一起开发了Unix操作系统)和布莱恩·柯尼汉(awk语言的发明者)在他们的不朽著作The C Programming Language 中写的第一段代码。Python也并不例外,但是在Python中,不需要像有些语言那样先构造一个复杂的语法结构,我们只需要下面一行代码就可以实现:
print("hello, world")
IDLE给我们提供了两种编程环境,帮助我们去学习Python语言,它们分别是交互式环境和文本编辑环境,我们下面结合这两种编程环境的介绍,来完成我们在Python中的第一个程序。
交互式环境
交互式环境的意思就是,我们输入了一行代码,敲击回车键之后,代码会马上被执行, 如果执行的代码有结果生成,那么这个结果会直接显示在窗口里。
我们打开IDLE之后所看到的界面就是一个交互式环境,我们可以在输入提示符之后,输入代码再回车(#后面的内容不需要输入):
>>>print("hello, world") #输入完成后敲回车
#下面一行为输出的结果
hello, world
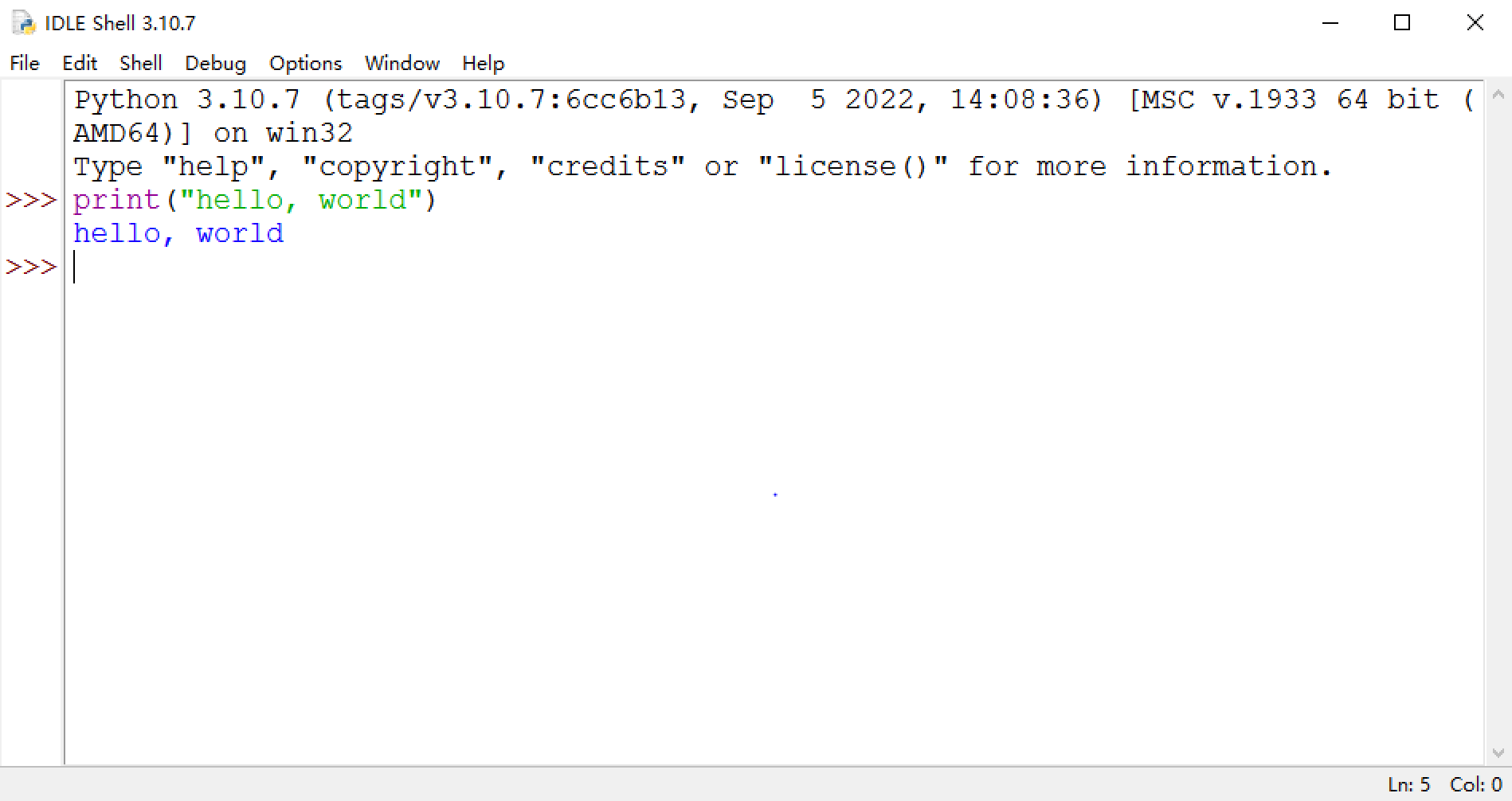
这里需要注意的是,我们只能在最后一个输入提示符>>>之后输入代码,即使在这之前有很多个>>>并没有我们输入的内容,就算是把光标移过去也是不可以的。
交互式环境的编程有很大的局限性,因为他每次只能写一行代码,或者是一个代码块,当我们要写的程序行数很多的时候就会很麻烦,一旦写的代码有错误,不能回去修改,只能重写。但是交互式编程并不是不可取的,它能够快速把代码执行的结果反馈出来,在这一点上是很便利的。
文本编辑环境
文本编程是指在文本编程器中编写代码并保存成文件之后,通过编程器编译成可执行的程序文件,或者通过解释器直接执行该程序文件的一种编程方式,文本编程也可以被叫作脚本式编程或者文件式编程,这种编程方式要求代码必须编写成一个纯文本文件,不能含有除了代码之外的任何信息。所以它对编辑文本的工具软件是有要求的,比如Windows系统中自带的记事本就可以进行代码的编写,然而写字板或者Office套件中的Word就不可以,因为这两种软件保存的文件中包含了其它除代码之外的内容。
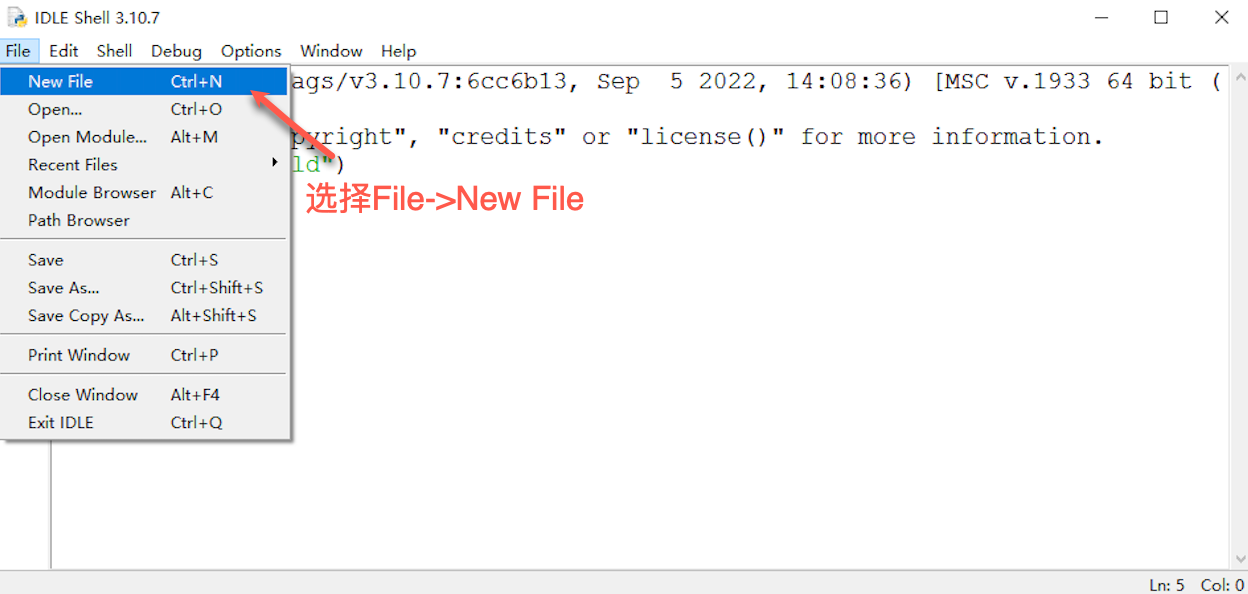
IDLE中同样提供了这样的文本编辑环境,可以根据下列步骤进行操作:
-
在IDLE的菜单栏中,选择 【File】, 然后点击 【New File】 打开一个文件编辑窗口:
-
在打开的文件编辑窗口之后,输入代码
print("hello, world"):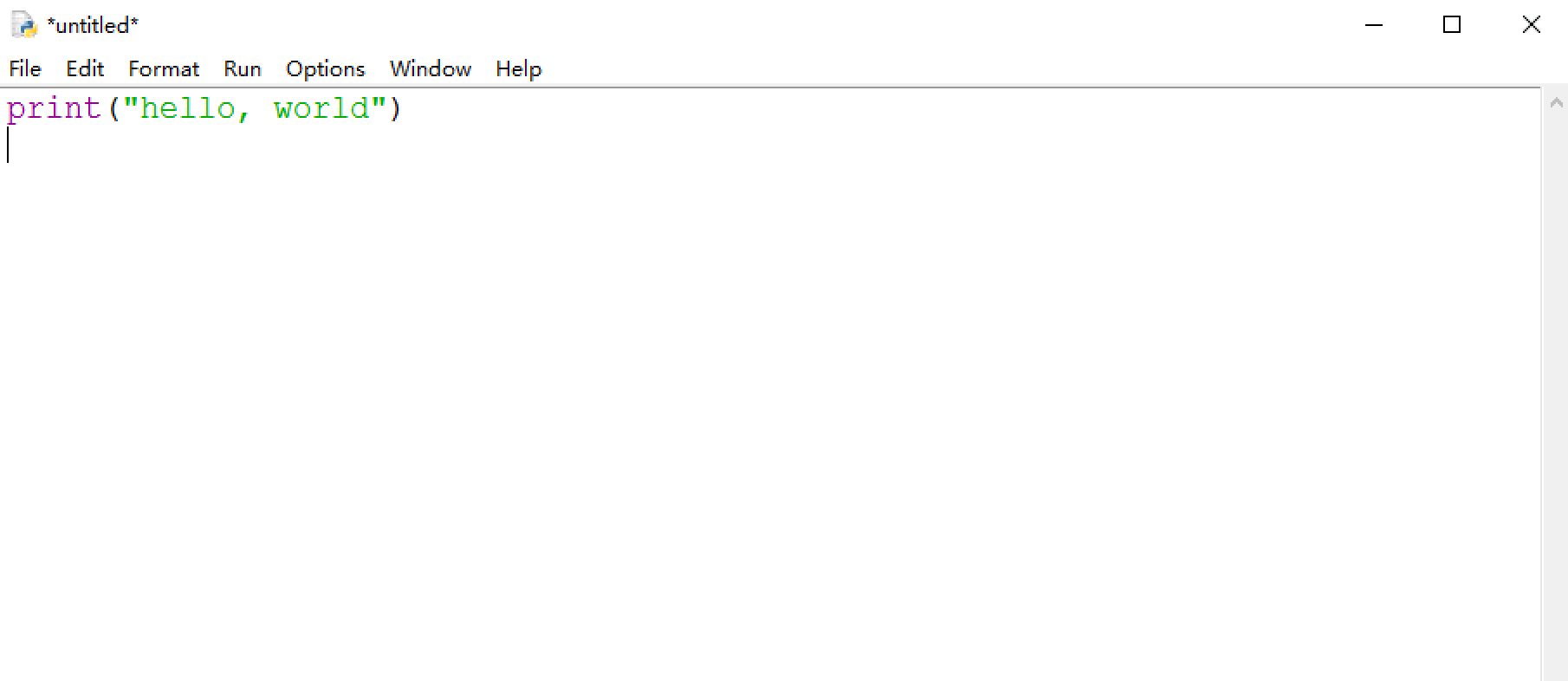
-
完成代码编写之后,保存文件,在菜单栏中 【File】, 然后点击 【Save】,然后输入保存的文件名字,一定要注意 【保存类型】 一定是 Python files(.py;.pyw,*.pyi) :
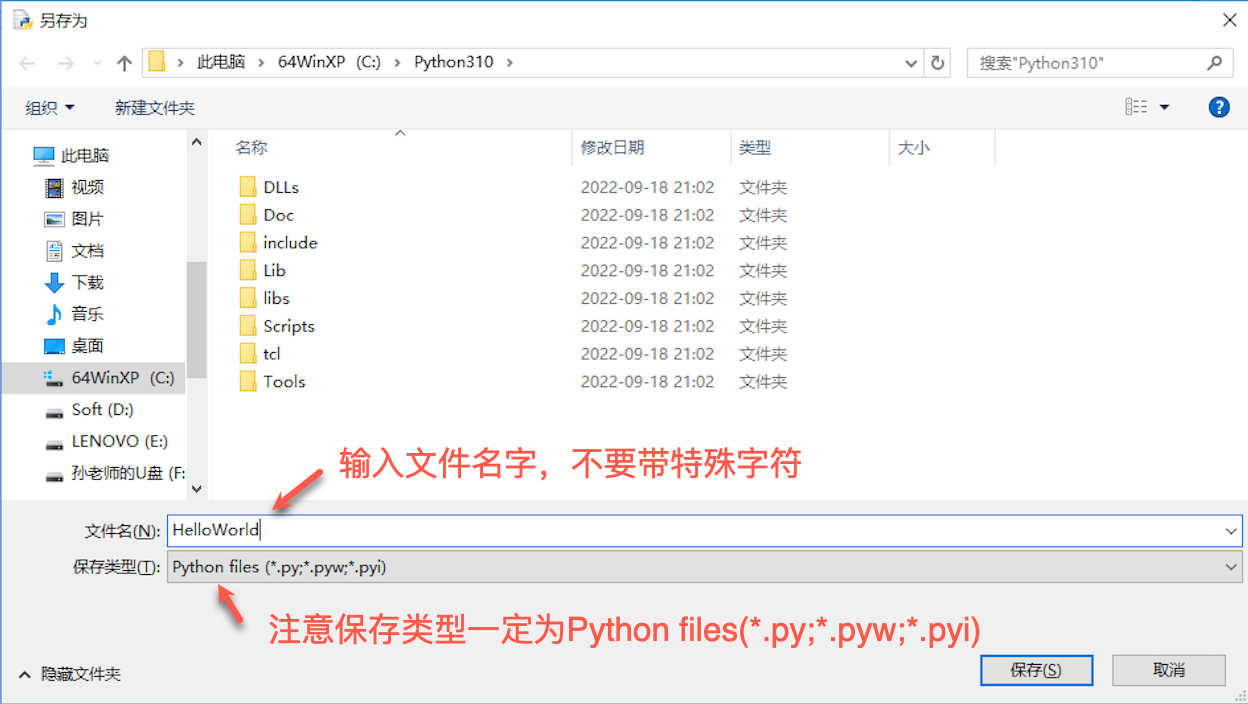
-
保存好文件之后,就可以运行程序了,在菜单栏中选择 【Run】, 然后点击 【Run Module】 就可以了,该操作的快捷键为 F5:
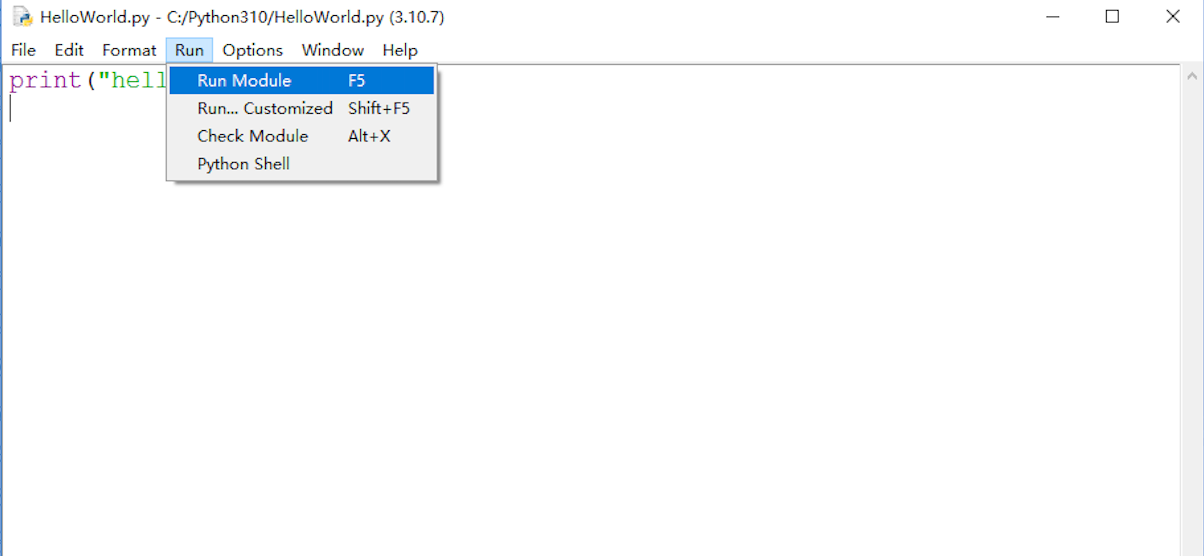
-
运行完成之后,结果会输出在IDLE中:
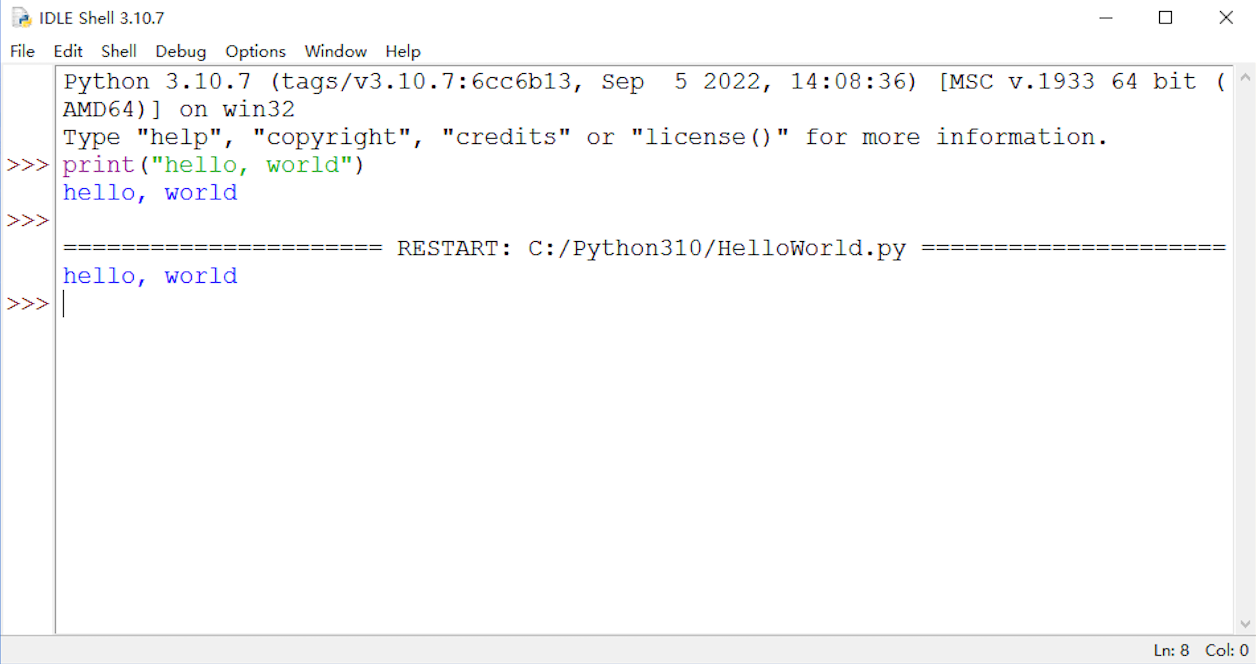
文本式编程是一种比较灵活的编程方式,一旦我们编写完代码运行之后发现了错误,就可以重新打开文件去修改:
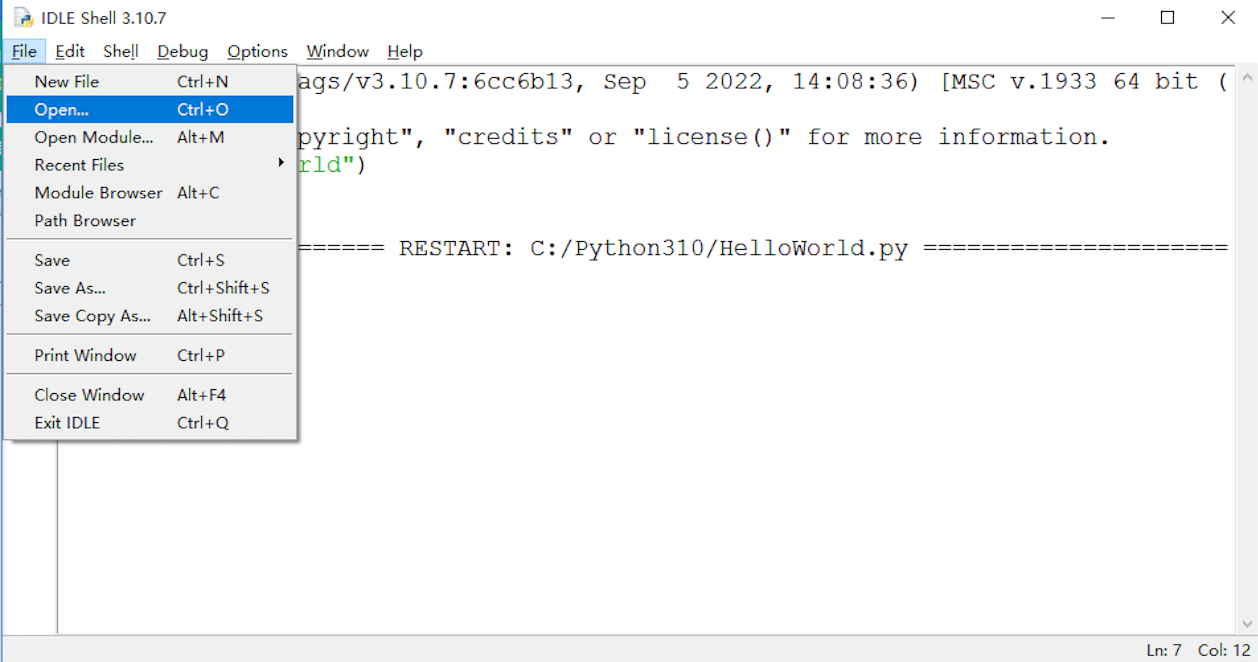
-
在菜单栏中,选择 【File】,点击 【Open】:
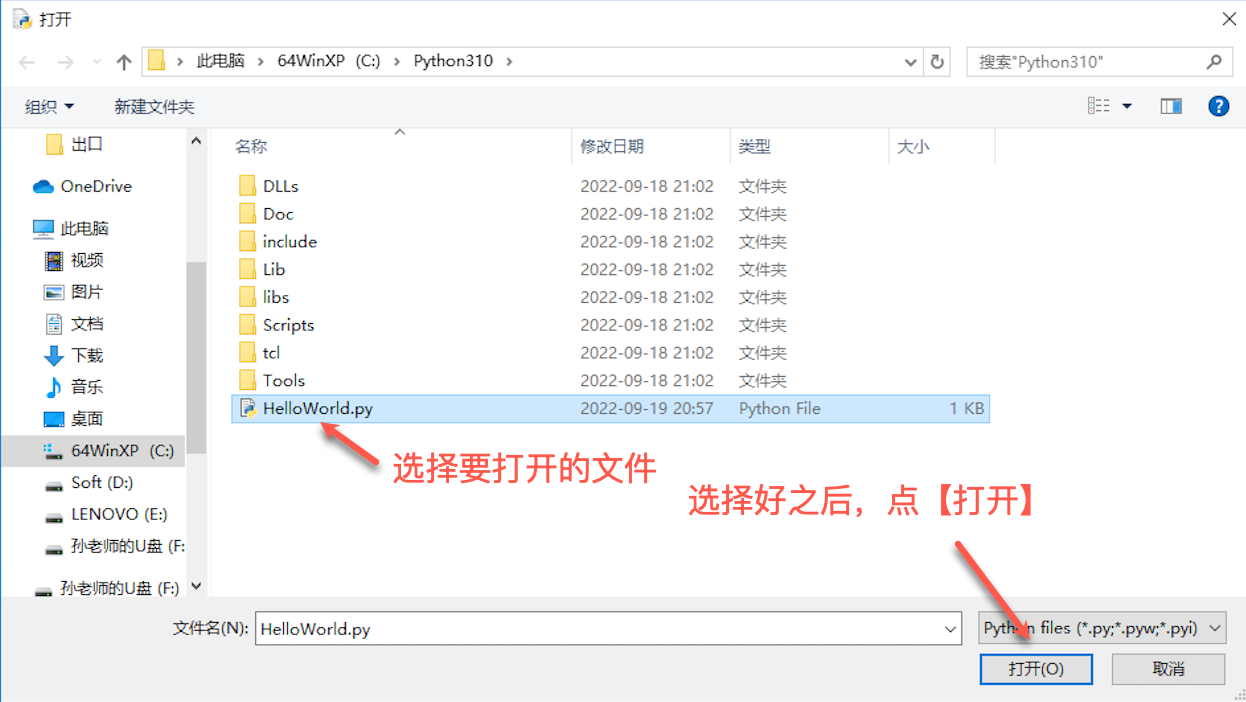
-
选择要打开的文件:
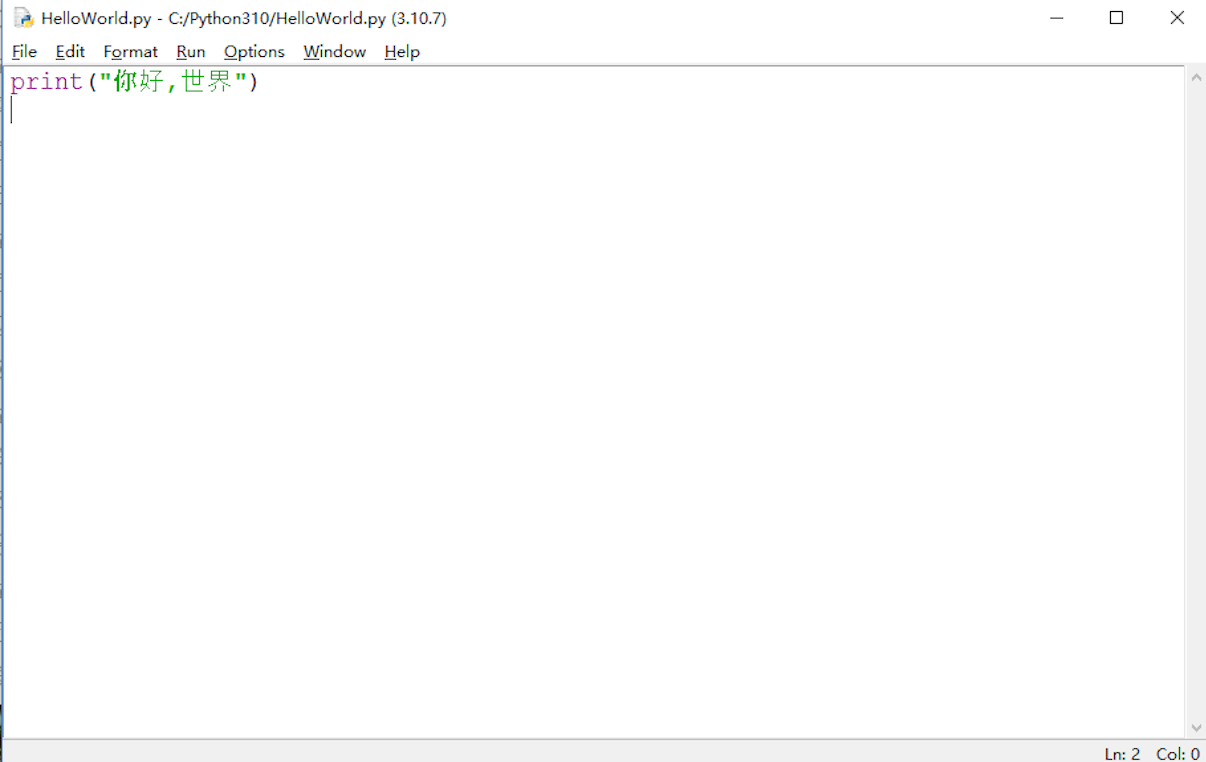
-
修改代码,之后再运行即可:
对于一个的程序员来讲,找到一个强大的集成开发环境是必不可少的先决条件。目前有几款比较流行的集成开发工具都支持Python编程,比如微软的Visual Studio Code (简称VS Code),或者JetBrains的PyCharm, 这些都是很强大且专业的工具。
有兴趣的同学可以点击下列链接了解上述提到的工具:
总结
我们已经把第一个Python程序运行起来了,同时出了解了两种不同的编程环境。同学们可以自由发挥,用print函数输出一些其它内容,注意要用引号引上。
可以尝试把下列代码通过文本式编程编写并运行,看看我们能看到什么?
注:两个"""之间的内容可以不用写, 且不要直接复制粘贴到交互式的环境中!
"""
第一个海龟画图程序:
1. 注意语句的缩进
2. 可以把range后面括号里的值改成其它数值
3. 可以把left后面括号里的值改成其它数值
4. 可以把left替换成right
"""
import turtle as t
colors = ['red', 'green', 'orange', 'blue']
for i in range(100):
t.color(colors[i%4])
t.forward(i)
t.left(90)
类型和变量
一个计算机程序是由算法+数据结构组成,在我们编写完程序之后,在运行它之前,它仅仅是一段静态的代码,只是步骤和方法的描述,并没有真正地帮我们解决问题。只有在运行起来之后,才能开始做事情,就像一副写在书上的《西红柿炒鸡蛋》的菜谱,我们光去看它是没有用的,只有我们买好原材料(西红柿和鸡蛋)之后,去厨房真正地去做它才能最终吃到好吃的西红柿炒鸡蛋。
细心的同学应该已经发现了,如果把程序比做菜谱,那么原材料(西红柿和鸡蛋)又应该是什么的比喻呢?实际上讲,我们编写的程序就是为了用来处理数据, 上一段中提到的原材料就是数据的比喻,而当程序运行起来并开始处理数据之后,它就从静态变为了动态,那么这个动态运行活动就叫做进程:
进程 = 程序 + 数据
process = program + data
或者
进程 = 算法 + 数据结构 + 数据
process = algorithm + data structure + data
那么什么是数据呢?你可能第一个想到的就是数学里学到的数值,如1,2,3...43.23,50,1000等等, 其实你的理解并不是错的,只是仅仅列出了数据的其中一种类型。
计算机中的数据不仅仅是狭义上的数字,还可以是具有一定意义的文字,字母,数字符号的组合、图形、图像、音频、视频等等。总之,根据百度百科的解释,数据是事实和观察的结果,是对客观事物的逻辑归纳,是用来表示客观事物的未经加工的原始素材。
每一种编程语言都有自己内建的基本数据类型,所以我们学习Python的第一个重要的内容就是基本数据类型。
基本数据类型Basic DataTypes
整型int
整型,英文为integer,是指没有小数部分的数值型数据,比如1,2,3,100,44221等等,但是1.0, 2.0, 10.0这些数值则不是整型,因为它们都带有小数部分,即使他们和整数部分的值大小相等。一个integer是集合 Z = {..., -2, -1, 0, 1, 2, ...} 中的一个数。在Python中,用int来表示整型的类型名,它是Python中唯一的一个整型类型,可以处理任意大小的整数。
可以在IDLE中直接输入一个整型数据,再回车:
>>> 1
1
>>> 2
2
>>> 100
100
>>> 888888888888888888888
888888888888888888888
Python中同样可以支持二进制、八进制和十六进制的表示法,如0b1000(二进制,换算成十进制为8),0o742(八进制,换算成十进制为482), 0xFAE(十六进制,换算成十进制为4014)。其中0b、0o和0x分别为二进制、八进制和十六进制的前缀,如果不写的话,二进制和八进制会被当做十进制处理,十六进制则会报错。
>>> 0b1000
8
>>> 0o742
482
>>> 0xFAE
4014
浮点型float
浮点型,英文为float,是指具有小数部分的数值型数据,比如1.414、3.1415926、2.718281828459045、4.000等等。在Python中,用float来表示浮点型的类型名,它是Python中唯一的一个浮点型类型,可以处理任意精度的浮点数。
>>> 1.414
1.414
>>> 3.1415926
3.1415926
>>> 2.718281828459045
2.718281828459045
>>> 4.000
4.0
Python中的浮点型支持十进制和指数型两种表示法,指数型也叫科学记数法,属于超纲内容,这里就不做过多介绍了,感兴趣的同学可以自行研究一下。
字符串str
字符串,英文为string,是指由文字、字母、数字以及一系列符号组成的一串字符,这些字符由单引号或者双引号括起来,比如“abc”、‘banana’、‘1000’等等。在Python中,用str来表示字符串的类型名。需要特别注意的是,只要用引号括起来之后,就是字符串,即使里面的字符看起来看是一个整型或者浮点型。
>>> "abc"
'abc'
>>> 'banana'
'banana'
>>> '1000'
'1000'
如果在字符串中需要用到引号("或')的话,可以用转义的方式(\'或\"),或者在需要用到单引号的时候,用双引号把字符串括起来,反之亦然:
>>> 'I\'m a student.'
"I'm a student."
>>> "I\'m a student."
"I'm a student."
布尔型bool
布尔型,英文为boolean,用来描述真假的一种数据,也叫逻辑型,它只有两个值: True 和 False。这里要注意一定是只有首字母大写,如果写成了true、flase、TURE或者是FaLSe都是错误的。在Python中,用bool表示布尔型的类型名。
>>> True
True
>>> False
False
如果输入错误,会报错,如输入true:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'true' is not defined
在Python中,bool类型其实是int类型的子类型,一般情况下,False就是0, True就是1;但是所有的非0的数值都可以认为是真逻辑值,这一点我们会在下一章节中详细说明。
空值None
空值,英文为None,是Python中一个很特殊的类型,它只有一个值,即None,表示空对象,什么都没有。但是数据为空并不是空值,比如空字符串"",它是字符串类型,并不是空值类型。在Python中,用NoneType表示空值的类型名。
>>> None
>>>
>>> ""
''
空值并不是一个没有意义的类型,相反,需要用到它的地方有很多。比如,调用函数的时候,不想给某个参数传递值,但是这个参数没有默认的值,所以传值是必须的,那么就可以把空值传给它。关于这一点,我们以后遇到的时候,结合实际用法就可以理解得更好。
变量Variables
在计算机编程中,变量就是一个数据的载体,也就是一块用来保存数据的内存空间,它可以被读取和修改。一个变量有两个最基本的要素:名字和类型。
我们可以把变量想像成一个用来存放数据的容器,像下图一样:
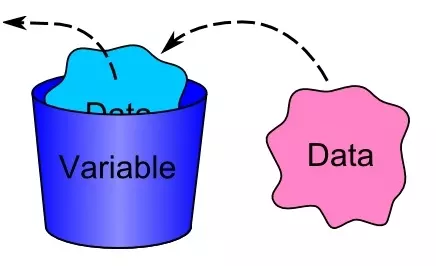
他在内存中的表现是这样的:
上图中的a就是变量的名字,在Python中,变量的类型不是在声明它的时候给出,而且会根据我们赋给它的值变化,比如a = 1,这时变量a的类型是整型int,如果我们重新给它赋值a="apple",那它的类型就变成了字符串str;我们也可以通过一些内建函数来改变它的类型,这一点我们后面很快就会讲到。
变量命名
每一个变量都需要提前定义,首先要给它取一个名字,方便我们在后面使用它。变量的命名是要遵循下列规则的:
- 变量的名字由字母、下划线
_和数字组成,但是不能以数字开头。这里的字母不单单是26个英文字母,它指的是在Unicode(也被称作万国码)字符集里的所有字母,包括中文、英文、日文、希腊字母、德文等等,范围非常广,但是像@、#、$这些字符是不能出现在变量名中的,我们强烈建议起名的时候只用英文字母。 - 变量的名字是大小写敏感的,比如
A和a是两不同的变量。 - 变量的名字不要使用Python中已经保留的关键字,也不要用自定义的函数、类名。
我们可以通过下面的方式查看Python中有哪些保留的关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
有关我自定义函数和类名的限制,我们以后会讲到。
变量赋值
可以通过执行赋值表达式来修改变量中存储的值,Python中的赋值运算符为=,这个等号并不是我们数学上的等于,千万不要混淆。给变量赋值的语法为:
变量 = 值
变量 = 变量
变量 = 表达式
变量 = 函数返回值
在赋值的时候,变量永远要写在左边,右边是要赋与它的值。
>>> a = 1 #直接用值给变量赋值
>>> print(a)
1
>>> b = a #用变量的值给变量赋值
>>> print(b)
1
>>> c = a + b #用表达式给变量赋值
>>> print(c)
2
>>> a = a + 1 #同样是用表达式给a赋值
>>> print(a)
2
>>> d = str(a) #用函数返回值给变量赋值
>>> print(d)
'2'
看到上面的例子,你是不是对于a = a + 1不太理解?没关系,我来给你解释:
赋值表达式在执行过程中,是先要执行赋值符=右边的代码的,当右边的代码执行完并得到结果之后,就会把这个结果赋值给赋值符=左边的变量。所以在a = a + 1中,最初变量a存储的值为1,先是使用了变量a,把它加了1之后得到2,再把字面量值2重新赋值给了变量a。
总之,变量是一种方便使用的占位符,用于引用计算机的内存地址来存储值。
类型和变量
一个计算机程序是由算法+数据结构组成,在我们编写完程序之后,在运行它之前,它仅仅是一段静态的代码,只是步骤和方法的描述,并没有真正地帮我们解决问题。只有在运行起来之后,才能开始做事情,就像一副写在书上的《西红柿炒鸡蛋》的菜谱,我们光去看它是没有用的,只有我们买好原材料(西红柿和鸡蛋)之后,去厨房真正地去做它才能最终吃到好吃的西红柿炒鸡蛋。
细心的同学应该已经发现了,如果把程序比做菜谱,那么原材料(西红柿和鸡蛋)又应该是什么的比喻呢?实际上讲,我们编写的程序就是为了用来处理数据, 上一段中提到的原材料就是数据的比喻,而当程序运行起来并开始处理数据之后,它就从静态变为了动态,那么这个动态运行活动就叫做进程:
进程 = 程序 + 数据
process = program + data
或者
进程 = 算法 + 数据结构 + 数据
process = algorithm + data structure + data
那么什么是数据呢?你可能第一个想到的就是数学里学到的数值,如1,2,3...43.23,50,1000等等, 其实你的理解并不是错的,只是仅仅列出了数据的其中一种类型。
计算机中的数据不仅仅是狭义上的数字,还可以是具有一定意义的文字,字母,数字符号的组合、图形、图像、音频、视频等等。总之,根据百度百科的解释,数据是事实和观察的结果,是对客观事物的逻辑归纳,是用来表示客观事物的未经加工的原始素材。
每一种编程语言都有自己内建的基本数据类型,所以我们学习Python的第一个重要的内容就是基本数据类型。
基本数据类型Basic DataTypes
整型int
整型,英文为integer,是指没有小数部分的数值型数据,比如1,2,3,100,44221等等,但是1.0, 2.0, 10.0这些数值则不是整型,因为它们都带有小数部分,即使他们和整数部分的值大小相等。一个integer是集合 Z = {..., -2, -1, 0, 1, 2, ...} 中的一个数。在Python中,用int来表示整型的类型名,它是Python中唯一的一个整型类型,可以处理任意大小的整数。
可以在IDLE中直接输入一个整型数据,再回车:
>>> 1
1
>>> 2
2
>>> 100
100
>>> 888888888888888888888
888888888888888888888
Python中同样可以支持二进制、八进制和十六进制的表示法,如0b1000(二进制,换算成十进制为8),0o742(八进制,换算成十进制为482), 0xFAE(十六进制,换算成十进制为4014)。其中0b、0o和0x分别为二进制、八进制和十六进制的前缀,如果不写的话,二进制和八进制会被当做十进制处理,十六进制则会报错。
>>> 0b1000
8
>>> 0o742
482
>>> 0xFAE
4014
浮点型float
浮点型,英文为float,是指具有小数部分的数值型数据,比如1.414、3.1415926、2.718281828459045、4.000等等。在Python中,用float来表示浮点型的类型名,它是Python中唯一的一个浮点型类型,可以处理任意精度的浮点数。
>>> 1.414
1.414
>>> 3.1415926
3.1415926
>>> 2.718281828459045
2.718281828459045
>>> 4.000
4.0
Python中的浮点型支持十进制和指数型两种表示法,指数型也叫科学记数法,属于超纲内容,这里就不做过多介绍了,感兴趣的同学可以自行研究一下。
字符串str
字符串,英文为string,是指由文字、字母、数字以及一系列符号组成的一串字符,这些字符由单引号或者双引号括起来,比如“abc”、‘banana’、‘1000’等等。在Python中,用str来表示字符串的类型名。需要特别注意的是,只要用引号括起来之后,就是字符串,即使里面的字符看起来看是一个整型或者浮点型。
>>> "abc"
'abc'
>>> 'banana'
'banana'
>>> '1000'
'1000'
如果在字符串中需要用到引号("或')的话,可以用转义的方式(\'或\"),或者在需要用到单引号的时候,用双引号把字符串括起来,反之亦然:
>>> 'I\'m a student.'
"I'm a student."
>>> "I\'m a student."
"I'm a student."
布尔型bool
布尔型,英文为boolean,用来描述真假的一种数据,也叫逻辑型,它只有两个值: True 和 False。这里要注意一定是只有首字母大写,如果写成了true、flase、TURE或者是FaLSe都是错误的。在Python中,用bool表示布尔型的类型名。
>>> True
True
>>> False
False
如果输入错误,会报错,如输入true:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'true' is not defined
在Python中,bool类型其实是int类型的子类型,一般情况下,False就是0, True就是1;但是所有的非0的数值都可以认为是真逻辑值,这一点我们会在下一章节中详细说明。
空值None
空值,英文为None,是Python中一个很特殊的类型,它只有一个值,即None,表示空对象,什么都没有。但是数据为空并不是空值,比如空字符串"",它是字符串类型,并不是空值类型。在Python中,用NoneType表示空值的类型名。
>>> None
>>>
>>> ""
''
空值并不是一个没有意义的类型,相反,需要用到它的地方有很多。比如,调用函数的时候,不想给某个参数传递值,但是这个参数没有默认的值,所以传值是必须的,那么就可以把空值传给它。关于这一点,我们以后遇到的时候,结合实际用法就可以理解得更好。
变量Variables
在计算机编程中,变量就是一个数据的载体,也就是一块用来保存数据的内存空间,它可以被读取和修改。一个变量有两个最基本的要素:名字和类型。
我们可以把变量想像成一个用来存放数据的容器,像下图一样:
他在内存中的表现是这样的:
上图中的a就是变量的名字,在Python中,变量的类型不是在声明它的时候给出,而且会根据我们赋给它的值变化,比如a = 1,这时变量a的类型是整型int,如果我们重新给它赋值a="apple",那它的类型就变成了字符串str;我们也可以通过一些内建函数来改变它的类型,这一点我们后面很快就会讲到。
变量命名
每一个变量都需要提前定义,首先要给它取一个名字,方便我们在后面使用它。变量的命名是要遵循下列规则的:
- 变量的名字由字母、下划线
_和数字组成,但是不能以数字开头。这里的字母不单单是26个英文字母,它指的是在Unicode(也被称作万国码)字符集里的所有字母,包括中文、英文、日文、希腊字母、德文等等,范围非常广,但是像@、#、$这些字符是不能出现在变量名中的,我们强烈建议起名的时候只用英文字母。 - 变量的名字是大小写敏感的,比如
A和a是两不同的变量。 - 变量的名字不要使用Python中已经保留的关键字,也不要用自定义的函数、类名。
我们可以通过下面的方式查看Python中有哪些保留的关键字:
>>> import keyword
>>> keyword.kwlist
['False', 'None', 'True', '__peg_parser__', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
有关我自定义函数和类名的限制,我们以后会讲到。
变量赋值
可以通过执行赋值表达式来修改变量中存储的值,Python中的赋值运算符为=,这个等号并不是我们数学上的等于,千万不要混淆。给变量赋值的语法为:
变量 = 值
变量 = 变量
变量 = 表达式
变量 = 函数返回值
在赋值的时候,变量永远要写在左边,右边是要赋与它的值。
>>> a = 1 #直接用值给变量赋值
>>> print(a)
1
>>> b = a #用变量的值给变量赋值
>>> print(b)
1
>>> c = a + b #用表达式给变量赋值
>>> print(c)
2
>>> a = a + 1 #同样是用表达式给a赋值
>>> print(a)
2
>>> d = str(a) #用函数返回值给变量赋值
>>> print(d)
'2'
看到上面的例子,你是不是对于a = a + 1不太理解?没关系,我来给你解释:
赋值表达式在执行过程中,是先要执行赋值符=右边的代码的,当右边的代码执行完并得到结果之后,就会把这个结果赋值给赋值符=左边的变量。所以在a = a + 1中,最初变量a存储的值为1,先是使用了变量a,把它加了1之后得到2,再把字面量值2重新赋值给了变量a。
总之,变量是一种方便使用的占位符,用于引用计算机的内存地址来存储值。
运算符和表达式
运算符是用来组成表达式的重要元素,会对表达式的结果产生影响。
表达式可以直接用来执行,并通过运算会得到一个结果,但是这个结果马上就会补缓存释放且不再存在,所以在编程过程中,表达式要配合变量来使用。
运算符 Operators
我们这里提到的运算符不仅仅是在数学中学到的加、减、乘、除, Python提供了大量的强大的运算符来帮助我们进行运算,这里我们先介绍下面三种类型的运算符(按优先级排列):
算术运算符 Arithmetic Operator
| 运算符 | 说明 |
|---|---|
** | 幂运算(指数运算) |
+ - | 正负号(正号可省略) |
* / % // | 乘、除、模(取余)、整除 |
+ - | 加、减 |
位运算符 Bit Operator
| 运算符 | 说明 |
|---|---|
~ | 按位取反 |
>> << | 右移 左移 |
& | 按位与 |
^ | | 按位异或、按位或 |
关系运算符(比较运算符)Relational Operator
| 运算符 | 说明 |
|---|---|
<= < >= > | 小于等于、小于、大于等于、大于 |
== != | 等于、不等于 |
逻辑运行符 Logic Operator
| 运算符 | 说明 |
|---|---|
not | 逻辑非 |
and | 逻辑与 |
or | 逻辑或 |
需要说明的是,上述前三种运算符的优先级为: 算术运算符>位运算符>比较运算符>逻辑运行符,而的位运行符中的按位取反~的优先级和正负号一样,低于幂运算**,高于其它算术运算符。
完整的运算符列表以及优先级可查看附录-完整运算符
表达式 Expression
表达式是由字面量的值、变量等等与运算符组成的运算式,每一个表达式最终都会等到一个确切的字面量的值。
有关字面量的解释,可以查看附录-字面量
在Python中,常用的表达式有算术表达式、关系表达式(或者叫比较表达式)和逻辑表达式。
算术表达式 Arithmetic Expression
Python中的算术表达式和数学中算式很像,只是我们不需要在后面再写个等号并给出结果。
>>> 1 + 1
2
>>> 1 - 1
0
>>> 1 * 2
2
Python中的除法运算/得到的结果一定是一个浮点型的数值:
>>> 10 / 5
2.0
Python中的整除和取余分别用来得到数学中除法运算的商和余数,比如:
\[10 \div 3 = 3 \ldots 1\]
取余运算%和整除运算//不仅仅适用于整型数值,也适用于浮点型数值,只要在参与运算的数值里,有一个浮点型,那么结果一点是一个浮点型数值。
>>> 10 // 3
3
>>> 10 % 3
1
>>> 10.0 // 3
3.0
>>> 10.0 % 3
1.0
>>> 18.32 // 2.51
7.0
>>> 18.32 % 2.51
0.7500000000000018
注: 至于上面的余数为什么出现了0.7500000000000018,我们后面会讲到。
在使用算术表达式的时候,一这要注意运算符的优先级关系,如果搞不清楚优先级,可以使用圆括号来确保运算的执行顺序。
比如在数学中的:
\[\lbrace[(3 + 4) \times 5-6]+7 \rbrace \times 8\]
应该写成:
>>> (((3 + 4) * 5 - 6 ) + 7) * 8
288
这一点同样适用于关系表达式和逻辑表达式。
在Python中,字符串也能进行加法+和乘法*运算,加法运算只能发生在两个字符串之间,运算结果为两个字符串连接在一起之后的新字符串;而乘法运算是只能由字符串和整型参与,比如"abc" * 2,结果为'abcabc'
>>> "abc" + "def"
'abcdef'
>>> "def" + "abc"
'defabc'
>>> "a" * 10
'aaaaaaaaaa'
关系表达式 Ralational Expression
关系表达式,也可以被叫做比较表达式,通过关系运算符将两个值连接到一起得到的一种表达式,用来运算这一关系是否成立,一个关系表达式的结果只有两个值True和False。
在使用关系表达式的时候,要注意数据的类型,一般情况下,整型和浮点型之间的比较没有限制,也可以和布尔型进行比较(基本不会用到),但是它们都不能与字符串进行比较:
>>> 3 > 2
True
>>> 4 < 2
False
>>> 5.3 > 3
True
>>> True > False
True
>>> False > -1
True
字符串之间则是按照字节逐个去比较的,比如下面三个字符串'16'、'161'和'8',先比较第一个字符,分别为'1'、'1'、'8',其中'8'比其它两个都大,所以'8'是三个中最大的字符串;在其余两个字符串中,前面两个字节均为'1'和'6',所以还要继续比较下一个字节的大小,但是第一个字符串只有两个字节,而第二个字符串还有第三个字节,所以第二个字符串比第一个字符串要大。根据以上分析,下面三个字符串的大小顺序为'8'>'161'>'16'。
>>> '16' < '161'
True
>>> '161' > '8'
False
两个字符串的大小是根据它们在字符集中的位置判断的,暂时我们只需要下表即可。
| 字符 | 位置 |
|---|---|
'0'~'9' | 48~57 |
'A'~'Z' | 65~90 |
'a'~'z' | 97~122 |
从上表可以看出,即使字母a是小写的,但是它并不“小”,在字符串中,它要大于大写字母A。当我们不确定某个字符在字符集中的位置的时候,可以调用函数ord()来查看,有关这一内建函数,我们会在后面章节详细学习:
>>> ord('A')
65
逻辑表达式 Logic Expression
当我们用两个关系表达式和逻辑运算符组成一个逻辑表达式时,它的结果也是只有两个True和False:
>>> 5 > 3 and 4 < 6
True
>>> 5 > 6 or 6 < 7
True
>>> 7 > 4 and 3 < 1
False
>>> not (5 > 6)
True
对于关系表达式,也可以多个值一起比较,但不建议用,在这里还是建义大家用逻辑表达式来代替:
>>> 5 < 6 > 2
True
>>> 5 < 6 and 6 > 2 #与上式等价
True
假如,假和爸爸去看电影,检票员说:”你们两个必须都有票才能进“,那么这里用的就是and,如果检票员说:”你们两个只要有一发张票就可以进入“,那么这里用的就是or。
我们可以用下表来熟悉两个关系表达式的结果在逻辑表达式中的运算情况
| 表达式a | 表达式b | and运算 | or运算 | not a运算 |
|---|---|---|---|---|
True | True | True | True | False |
True | False | False | True | False |
False | True | False | True | True |
False | False | False | False | True |
在Python中,还有一种特别有意思的概念,也是我们接下来要讲的:短路逻辑,它的意思可以理解成在逻辑表达式中,运算符右边部分的运算被短路了:
在a and b表达式中,如果a的值为True,那么结果为b的值,否则结果直接为a的值
>>> 5 and 6
6
>>> 5 < 4 and 6 > 1 #这里关系表达式“6 > 1”被短路了,并没有进行运算
False
>>> False and 6 #这里6被短路了,并没有被运算
False
在a or b表达式中,如果a的值为True,那么结果为a的值,否则结果直接为b的值
>>> 5 or 6 #这里6被短路了,并没有被运算
5
>>> 5 > 4 or 6 < 1 #这里关系表达式“6 > 1”被短路了,并没有进行运算
True
>>> False or 6
6
在上一章节,我们提到过,任何非0数值均可被认为是真逻辑值,这一说法可以扩展到其它基本类型:
| 类型 | 假逻辑值 | 真逻辑值 |
|---|---|---|
int | 0 | 非0整数 |
float | 0.0、0.00等等 | 非0.0浮点数 |
str | '' | 非空字符串 |
NoneType | None | 无 |
>>> '' and True
''
>>> None and False
>>>
表达式与变量
在本章节开篇时,我们提到,表达式的结果被输出之后就会被缓存释放了,所以为了后面继续使用表达式运算出来的结果,需要配合变量来使用。
>>> a = 5 + 7
>>> print(a)
12
>>> b = 4 > 3 and 5 < 1
>>> print(b)
False
>>> c = a and b
>>> print(c)
False
有关变量的详细内容,如果还有不清楚的地方,可以回到上一章节中复习:变量。
位运算
程序中的所有数在计算机内存中都是以二进制的形式储存的。位运算就是直接对整数在内存中的二进制位进行操作。所以要先了解二进制。
另:本章节详细分析部分有一定难度,建议只学习位运算符的使用方法即可。
二进制
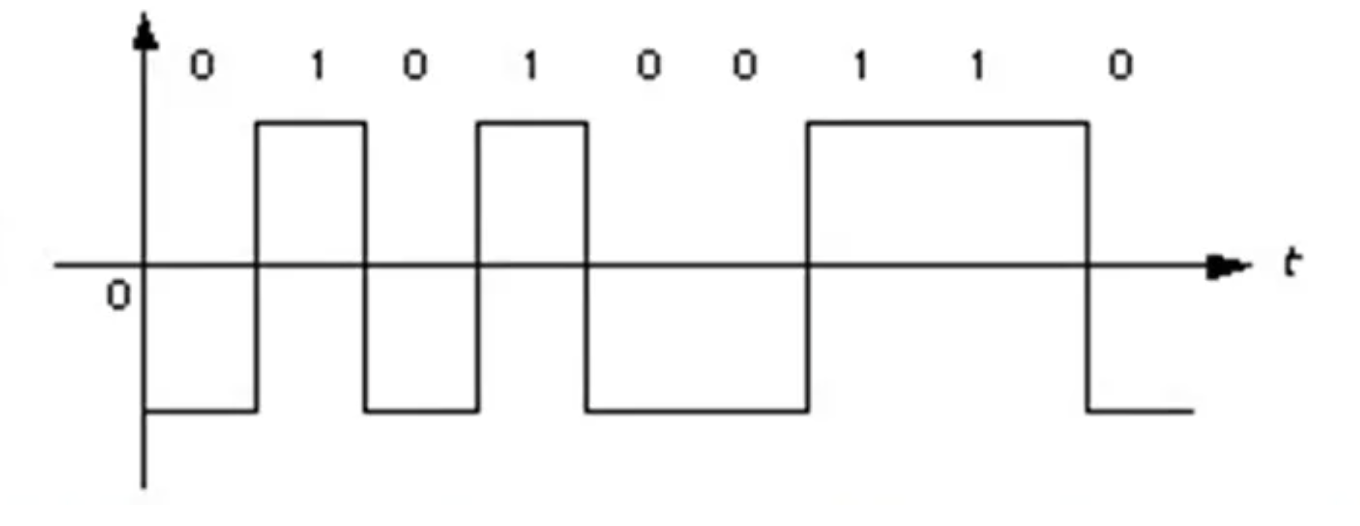
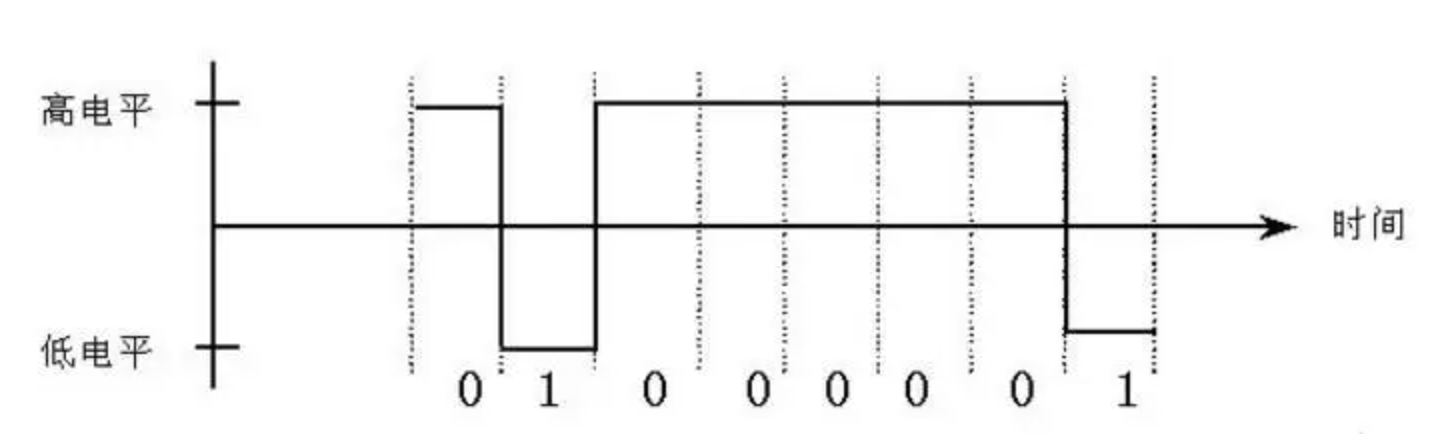
17世纪至18世纪的德国数学家莱布尼茨,是世界上第一个提出二进制记数法的人。用二进制记数,只用0和1两个符号,无需其他符号。这一计数方法充分结合了数字电子电路系统的高低电平,在一些系统中,高电平表示1,低电平表示0,而有的系统则是高电平表示1,低电平表示2。这也是为什么低级语言编写的程序不能跨平台使用的原因。下面两个图可以简单表示两种不同系统的高低电平情况:
进制转换
十进制转二进制
一个十进制数转换为二进制数要分整数部分和小数部分分别转换,最后再组合到一起。
整数部分采用 "除2取余,逆序排列"法。具体做法是:用2整除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为小于1时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。例:125:
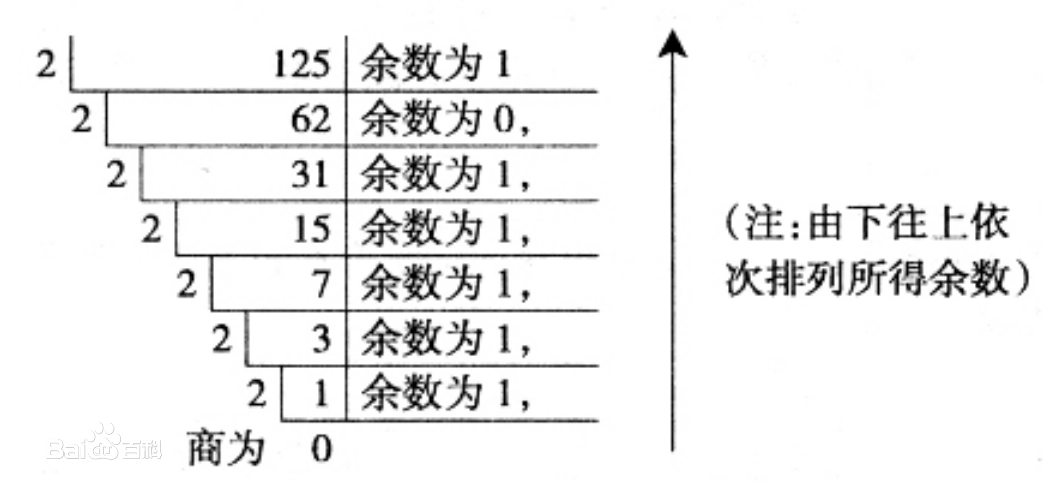
经过运算,十进制的125,转换成二进制之后为1111101。
小数部分要使用“乘2取整法”。即用十进制的小数乘以2并取走结果的整数(必是 0或1),然后再用剩下的小数重复刚才的步骤,直到剩余的小数为0时停止,最后将每次得到的整数部分按先后顺序从左到右排列即得到所对应二进制小数。例如,将十进制小数 0.8125 转换成二进制小数过程如下:

二进制转十进制
二进制转换成十进制是要按位进行\(2^{x-1}\)运算,再加到一起,比如:
\[(111111)_2 = 2^5 + 2^4 + 2^3 + 2^2 + 2^1 + 2^0 = 63\]
或:
\[(101011)_2 = 2^5 + 2^3 + 2^1 + 2^0 = 43\]
位运算 Bitwise
| 运算符 | 说明 |
|---|---|
~ | 按位取反 |
>> << | 右移 左移 |
& | 按位与 |
^ | | 按位异或、按位或 |
按位取反
按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1:
>>>~6
-7
>>>~-8
7
~x 类似于 -x-1,但是实际情况远远要复杂得多,有兴趣的同学可以查看附录进行学习附录-按位取反
左移、右移
位运算中,左移n位相当于原数整除2n,左移n位相当于原数乘以2n,但是位移运算效率更高。
>>>15>>2
3
>>>15<<2
60
假设我们的一台简易计算机只用一个字节(byte,即8位)来存储数值,那么15的二进制应该为0000 1111,所以左移2位之后变为0000 0011,即3; 左移2位之后变成0011 1100,即60。
按位与
按位与运算是将两个数值的二进制按位进行逻辑与运算,只有同时为1时才能得到1,否则结果都是0。
>>>15 & 24
8
| 15: | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 24: | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| & | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
按位或
按位或运算是将两个数值的二进制按位进行逻辑或运算,只有同时为0时才能得到0,否则结果都是1。
>>>15 | 24
31
| 15: | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 24: | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| | | 0 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
按位异或
按位异或运算是将两个数值的二进制按位进行逻辑异或运算,当值相同是得到0,不同时则得到1。
>>>15 | 24
23
| 15: | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 1 |
| 24: | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 |
| ^ | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 |
总结
位运算是计算机编程中很重要的一种运算方式,这里我们暂时了解这些就足够了。
常用内建函数
在今后的学习过程中,我们会用到很多内建函数,比如标准的输入输出,类型转换等等。内建函数实现了一些常用的功能,可以直接拿来使用。
| 函数名 | 功能 | 返回值 |
|---|---|---|
print() | 向终端输出信息 | 无 |
input() | 通过终端输入数据并返回结果 | 有 |
int() | 将参数中的值转换成整型并返回结果 | 有 |
float() | 将参数中的值转换成浮点型并返回结果 | 有 |
str() | 将参数中的值转换成字符串并返回结果 | 有 |
eval() | 将参数中字符串转换成一段可执行的表达式并返回结果 | 有 |
chr() | 返回整型参数在Uncode 中对应的字符 | 有 |
ord() | 返回字符参数在Uncode 中对应的码位 | 有 |
print()
我们在hello, world中已经使用过了print()函数:
>>>print("hello, world!")
hello, world!
print()函数的功能就是将参数的内容打印出来:
- 对于实际的值,原样打印,字符串要用引号(如上)
>>> print(1)
1
>>> print(1.4)
1.4
>>> print(True)
True
- 对于变量,打印变量内存储的值
>>> a = 4
>>> print(a)
4
>>> name = "Chris"
>>> print(name)
Chris
- 也可以打印函数返回的值
>>> print(chr(65))
A
print()函数是默认以\n结束,也就是说,当打印完信息之后自动会换行,如果想要不自动换行,可以给参数end传一个别的值:
>>>print(123);print(456)
123
456
>>>print(123, end = "$");print(456)
123$456
print()函数也可以打印多段值,默认用' '隔开,如果想要换成其它分隔符,可以给参数sep传入其它值:
>>> a = 'A'
>>> b = 'B'
>>> c = 'C'
>>> print(a,b,c)
A B C
>>> print(a,b,c,sep = "&")
A&B&C
占位符
在用print()函数向终端输出信息时,可以使用占位符来格式化:
| 占位符 | 描述 | 说明 |
|---|---|---|
%d | 整型占位符 | 无 |
%f | 浮点型占位符 | 默认保留小数点后6位,如果要自定义保留n 位,可以写成%.nf,结果会四舍五入 |
%s | 字符串占位符 | 无 |
>>> print("%s is a student." %"Tom")
Tom is a student.
>>> name = "Jerry"
>>> print("%s is a student." %name)
Jerry is a student.
>>> age = 10
>>> print("He is %d years old." %age)
He is 10 years old.
>>> height = 1.46
>>> print("His height is %.1f." %height)
His height is 1.5.
#有多个占位符时,需要用括号
>>> print("%s is a student. He is %d years old. His height is %.1f." %(name, age, height))
Jerry is a student. He is 10 years old. His height is 1.5.
#如果不填充占位符,那么就会原样输出。
>>> print("%s is a student. He is %d years old. His height is %.1f.")
%s is a student. He is %d years old. His height is %.1f.
input()
input()函数可以接收标准输入的数据,并且把数据以字符串格式返回,括号里的参数会被输出到终端作为提示用,这里参数的用法和print()一致:
>>> input()
# 下面一行是输入的内容,在输入时会有光标闪烁
1
# 下面一行是input()函数返回的值
'1'
>>> input("Input a value:")
# 先输出提示的参数,然后再在后面输入内容,在输入时会有光标闪烁
Input a value:1
'1'
由于input()是有返回值的函数,所以当我们输入了值之后,如果没有把返回的值赋值给变量,那么这个值会马上被缓存释放,并不再存在,所以我们要用一个变量来接收这个返回值:
>>> a = input("Input a:")
# 下面一行是输入的内容,在输入时会有光标闪烁
Input a:1
>>> print(a)
'1'
练习: 从终端输入两个值,分别赋值给变量a和b,并尝试进行计算下列算式,查看结果:
>>> a = input("Input a:")
Input a: #输入值给a
>>> b = input("Input b:")
Input b: #输入值给b
#尝试下列算式:
>>> a + b
>>> a - b
>>> a * b
>>> a / b
int()和float()
假如你已经尝试了上述代码,给a 赋值了1,给b 赋值了2,那么你会发现加法运算的结果是'12',而其它运算都报了错误:
Traceback (most recent call last):
File "<pyshell#71>", line 1, in <module>
a-b
TypeError: unsupported operand type(s) for -: 'str' and 'str'
...
TypeError: can't multiply sequence by non-int of type 'str'
...
TypeError: unsupported operand type(s) for /: 'str' and 'str'
相信细心的同学已经想到了原因:用input()函数通过终端输入的内容都会以字符串的形式返回出来,但是字符串与字符串之间并没有-、*、/的运算,而+运算只是把两个字符串连接到一起。
为了能够进行数学运算,我们需要用到int()和float()将返回的字符串转换成数值:
- int(): 将输入的参数转换成整型,可以输入的参数为<整型、浮点型和整数型的字符串>
>>> int(1)
1
>>> int(1.5)
1
>>> int("32")
32
>>> int("2.2")
Traceback (most recent call last):
File "<pyshell#74>", line 1, in <module>
int("2.2")
ValueError: invalid literal for int() with base 10: '2.2'
# int()是有返回值的函数,需要用变量接收返回值:
>>> a = int("32")
>>> print(a)
32
- float():将输入的参数转换成浮点型,可以输入的参数为<整型、浮点型和数值型的字符串>
>>> float(3)
3.0
>>> float(1.2)
1.2
>>> float("2.2")
2.2
>>> float("2.2.2")
...
Traceback (most recent call last):
File "<pyshell#78>", line 1, in <module>
float("2.2.2")
ValueError: could not convert string to float: '2.2.2'
# float()是有返回值的函数,需要用变量接收返回值:
>>> a = float("1.5")
>>> print(a)
1.5
函数之间是可以嵌套的:
>>> a = int(float("2.2"))
>>> print(a)
2
练习: 重新练习下面练习题,从终端输入两个值,分别赋值给变量a和b,并尝试进行计算下列算式,查看结果
要求:1. 第一次尝试给 a和b 分别输入整型
2. 第二次尝试给 a和b 分别输入浮点型
>>> # input a 代码,由学生练习时填写
>>> # input b 代码,由学生练习时填写
#尝试下列算式:
>>> a + b
>>> a - b
>>> a * b
>>> a / b
str()
str()用来将输入的参数转换成字符串并返回:
>>> str(1)
'1'
>>> a = str(1)
>>> print(a)
>>> a
'1'
在IDLE中,用交互环境直接输入变量名字,会打印出该变量的值,这个和 print()是有区别的,如果用print()打印出来的是用户能理解的数据,而直接输入变量名字,打印出来的是解释器能理解的数据。但是在文本编程环境中,只能用print()函数。
eval()
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
>>> a = 5
>>> b = eval("a + 5")
>>> print(6)
b
如果字符串表达式中用到的变量不存在,就会报错:
>>> c = eval("d + 3")
Traceback (most recent call last):
File "<pyshell#85>", line 1, in <module>
c = eval("d + 3")
File "<string>", line 1, in <module>
NameError: name 'd' is not defined. Did you mean: 'id'?
chr()和ord()
我们可以将这两个函数理解成字典,chr()和ord()的功能是正好相反的,chr()是根据数值查找字符,ord()是根据字符查找它所在位置。
>>> chr(65)
'A'
>>> ord('A')
65
>>> ord("我")
25105
函数的参数
通过上面内建函数的学习,我们发现在调用函数时需要在()给出一个值,这个值就是参数。
也许你已经在数学中学习过了有关未知数的概念,那么你对参数已经有了初步的接触,如下面的方程:
\[5x+(4 \times 5)-19=46\]
我们可以经过解方程得到\(x\)的值为9,然而这里的\(x\)是一个固定的值,在解方程之前它只是个未知数,只有解开方程之后才知道它的值是多少。
然而,Python中参数更像是初中要学习的函数里的定义域:
\[ y=x^2+2x+1 \]
或者
\[ f(x)=x^2+2x+1 \]
这里的\(x\)是一个变化的值,随着\(x\)的变化,\(y\)或者函数\(f(x)\)的值也会变化。在编程领域,这里的\(x\)定义域可以理解成参数(parameters)。
此处我们先对位置参数和默认值参数简单介绍一下,首先需要知道的是,函数的参数可以有零个和多个:
-
当函数
f没有参数时,在调用时只需要写出f()即可,括号内不需要给出任何值。 -
当函数
f有一到多个位置参数时,有三种调用方式,假设函数为f(a, b, c):- 按顺序传参数,比如
f(a, b, c); - 传值时,按名字传参数,比如
f(b=1, a=5, c=4),如果写在最前面的参数不是位置1的参数,那么其它参数必要都要按名字传值; - 最前面参数按顺序传参时,排在后面的参数可以按名字传,比如
f(1, c=5, b=10)。
- 按顺序传参数,比如
-
当函数
f中,有默认值参数时,根据Python语法,默认值一定会写在位置参数之后,调用方式除第2点中的三种之外,还有另外一种方式为,假设函数为f(a, b=5, c=7):- 不给默认值参数传值,调用时直接写
f(1); - 当不需要给第二个参数传值时,可以写作
f(1, c=7)。
- 不给默认值参数传值,调用时直接写
返回值
调用一个有返回值的函数会生成一个值,我们通常可以将这个返回值赋值给某个变量,或者将函数的调用作为为表达式的一部分。
例如:
>>> a = int('5')
>>> b = int('5') + 7
在 Python 中,直接执行有返回值的函数不会有错误发生,但是这个返回值只在缓存里短暂地保留,稍后很快就会被释放。可以将函数比喻成一只母鸡,输入的参数值比喻成虫子,而接受返回值的变量或者表达式可以比喻成篮子;母鸡吃了虫子之后,就会下蛋;如果没有篮子接受这颗蛋,它就会碎掉;所以为了保护鸡蛋的完整,需要有篮子接住它。

基于上述原因,我们在调用有返回值函数时要配合变量或者表达式来使用,不要做无用的调用。
海龟画图-第一部分
海龟画图(Turtle Graphics)是Python的内建模块,它移植于LOGO语言,这门语言是在1967年由Seymour Papert, Wally Feurzig和Cynthia Solomon 为了专门给儿童学习编程发明出来的,它的特色就是通过编程指挥一个小海龟(Turtle) 在屏幕上绘图。
在 Python 中,海龟绘图提供了一个实体“海龟”形象(带有画笔的小机器动物),假定它在地板上平铺的纸张上画出线条形成各种图形。
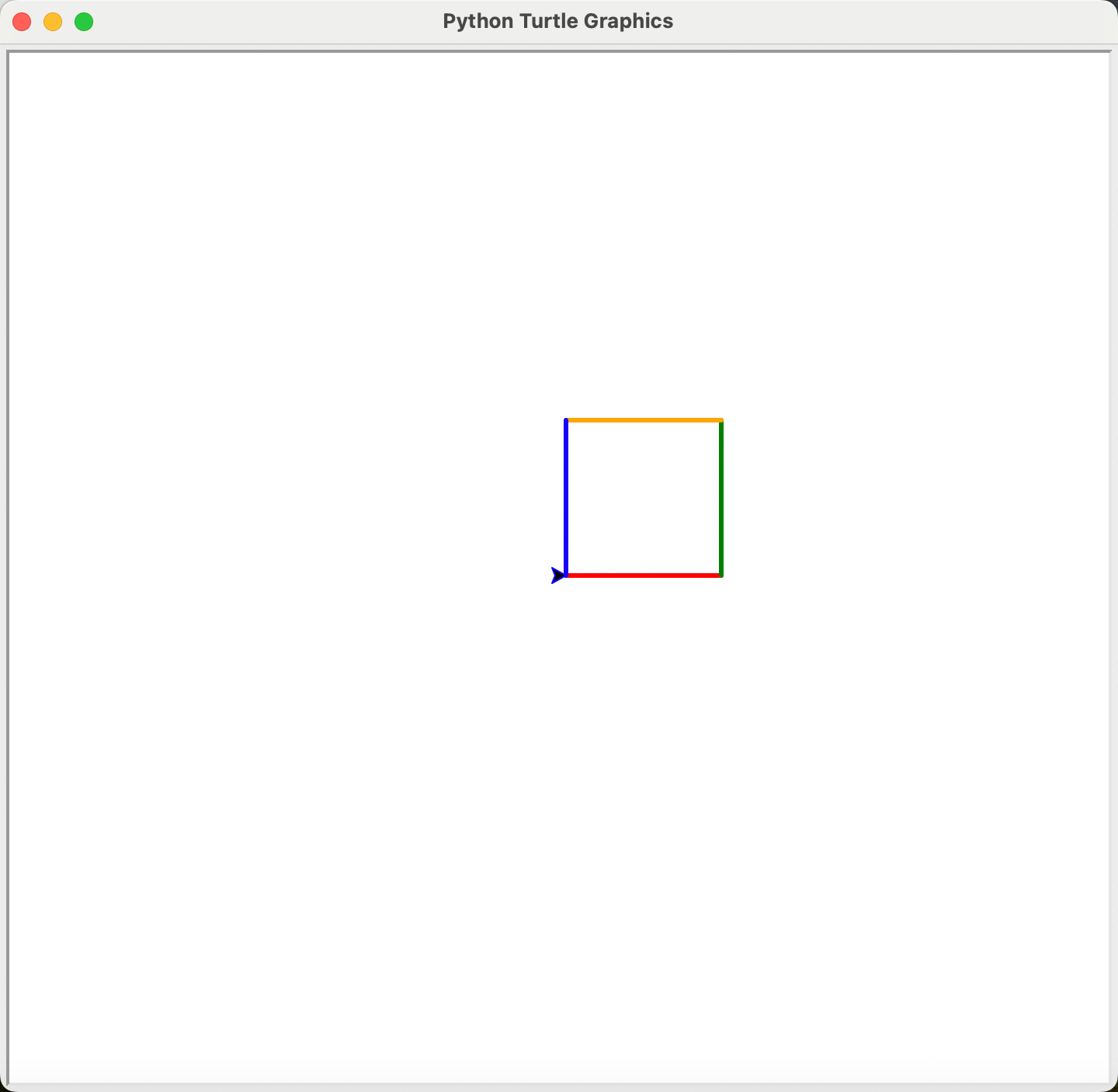
我们先通过下面简单代码对海龟画图有个初步认识
import turtle as t
"""
author: 孙老师
功能: 画一个正方形
"""
t.pensize(3)
t.pencolor("red")
t.forward(100)
t.left(90)
t.pencolor("green")
t.forward(100)
t.left(90)
t.pencolor("orange")
t.forward(100)
t.left(90)
t.pencolor("blue")
t.forward(100)
t.left(90)
运行上述代码之后,弹出绘画窗口,并画出一个正方形:
导入模块
由于turtle是Python中的内置模块,在使用之前需要先用import关键字来导入,导入模块有三个方式:
# 方式1:导入模块
import turtle
# 方式2:导入模块并起一个别名
import turtle as t
# 方式3:批量导入资源
from turtle import *
- 使用第一种方式时,在调用模块中的资源时,用
turtle.的方式即可,例如turtle.forward(100)。 - 使用第二种方式时,在调用模块中的资源时,用
t.的方式即可,例如t.forward(100)。 - 使用第三种方式时,可以直接用资源的名字调用,不需要加任何前缀,例如
forward(100)。
这里我们建议用第二种方式;不建议用第一种方式的原因是有些模块的名字会很长,在编写代码时应用起来不太方便;而对于第三种方式而言,需要特别注意不要从不同模块导入有相同名字的资源,也不要编写同名的自定义函数,所以在初期学习阶段并不建议。
海龟的属性
在让海龟画图之前,首先要了解海龟的三个属性,分别为:位置、方向和颜色。
位置
在Python中,海龟的位置是由x和y两个信息组成的,它们分别表示海龟横纵坐标。我们以画布的最中心点为原点,分别在水平和垂直的方向画两条线,这样就画出类似于数学中的平面坐标系,如下图:
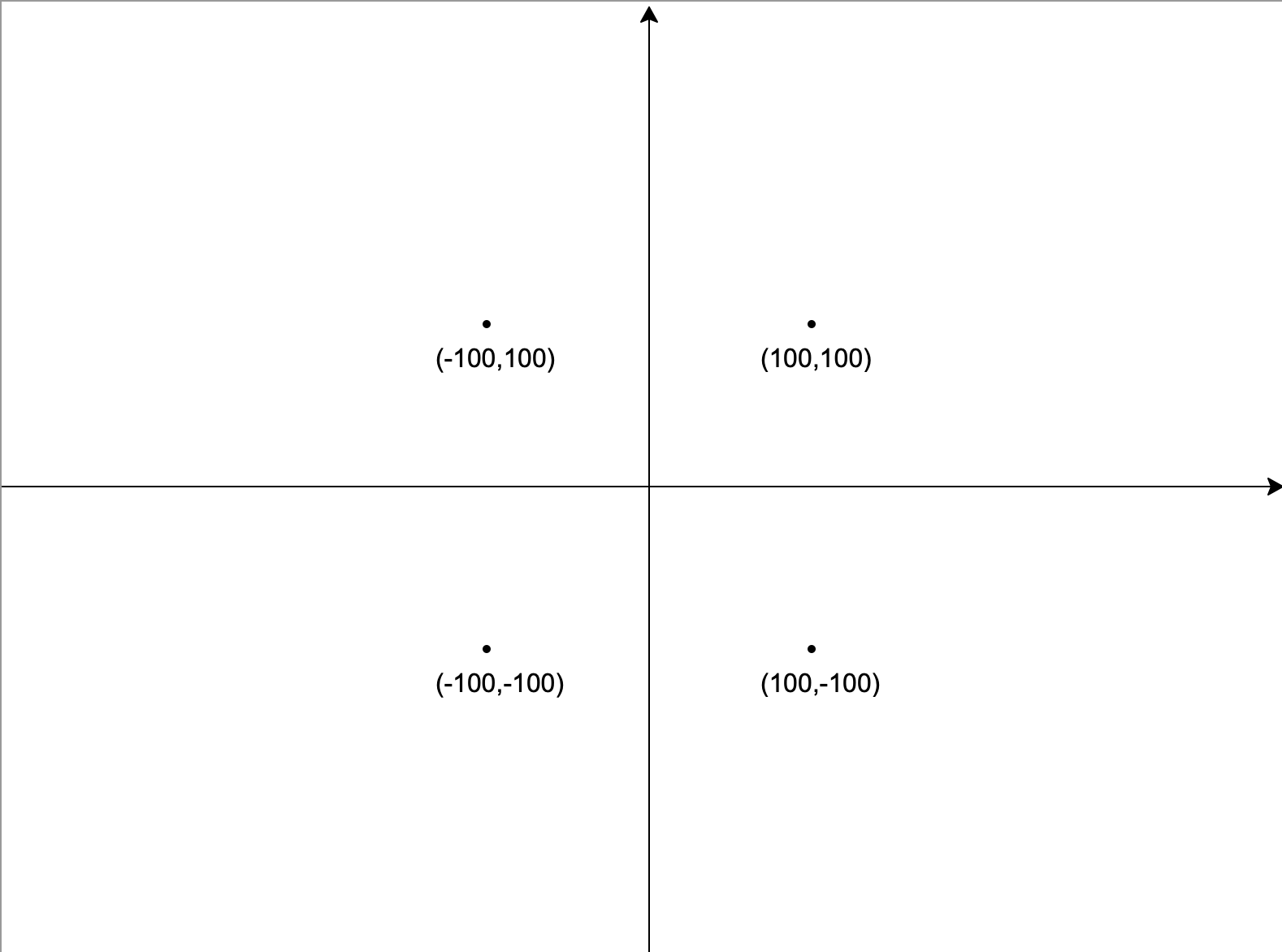
平面坐标系把整个画布分成了四个部分,也叫四个象限:
- 第一象限:位于坐标系的右上,
x和y的值均为正数; - 第二象限:位于坐标系的左上,
x为负数,y为正数; - 第三象限:位于坐标系的左下,
x和y的值均为负数; - 第四象限:位于坐标系的左上,
x为正数,y为负数。
坐标的表示方式为(x,y),如(100,100)、(-43,32)等。
方向
这里提到的方向指的就是绝对方向:
- 0°:水平向右
- 90°:垂直向上
- 180°:水平向左
- 270°:垂直向下
即,只要当海龟的箭头指向水平向左,那边它的绝对方向就是180°。
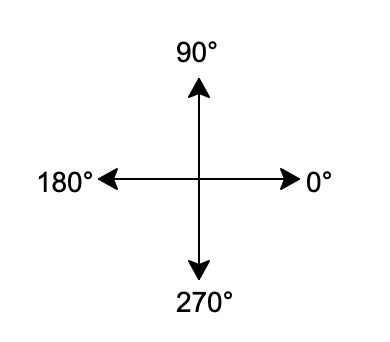
需要提醒的是,水平向右的绝对方向为0°是模块中默认的情况,我们可以调用mode()函数来设置垂直向上的绝对方向为0°。请查看海龟的绝对零度进行详细的学习,我们在学习本章过程中以默认的情况为主。
颜色
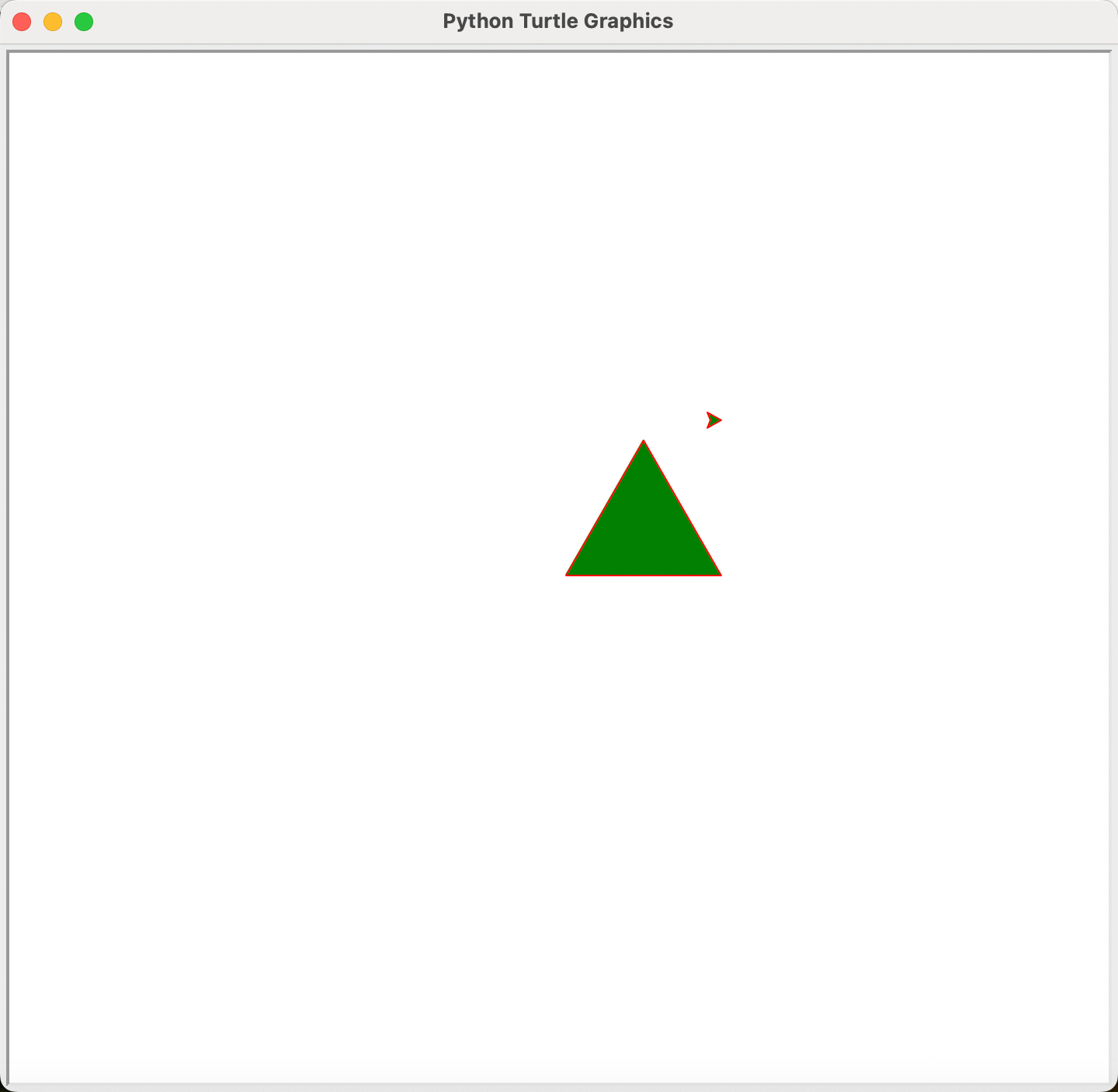
海龟的颜色分为画笔颜色和填充颜色,画笔颜色决定海龟在画图时线条的颜色,而当海龟在绘制之后,会形成一个平面图形,如果调用了填充函数,会给这个平面图形填充颜色,那么海龟的填充颜色影响的就是这个平面图形内的颜色。
如下图所示,在绘制完等边三角形之后,我们将海龟称动到了坐标为(100, 100)的位置,可以很清楚看到,海龟的外面一圈为红色, 而内部为绿色,这里外面的一圈就是画笔颜色,内部为填充颜色。所以,这只海龟所绘制的等边三角形的线条为红色,而内部填充的为绿色:
海龟和它的分身
在导入海龟之后,可以直接让海龟去画图,如下:
import turtle as t
t.circle(100)
这里我们直接用的模块的别名t来画的这个图形;除此之外,也可以用Pen()函数给海龟创建一个影分身来作画。调用这个函数时不需要传递任何参数,并且要注意第一个字母P要大写:
import turtle as t
p1 = t.Pen()
p2 = t.Pen()
p1.pu()
p1.goto(100,100)
p1.pd()
p2.pu()
p2.goto(-100,100)
p2.pd()
t.showturtle()
在创建了分身之后,并不影响我们继续使用别名t去调用海龟的函数让他作画,在上述代码中,我们在创建好两个影分身并移动它们之后,调用了showturtle()函数让海龟本体也显示出来了,此时可以进行绘画的画笔就有了三个。
让海龟去画图(一)
所谓的海龟画图,就是能用调用海龟画图模块turtle的函数,让小海龟在画布上移动画出线条,形成平面图形的过程。所以我们需要掌握主要内容就是如何去调用turtle模块的函数。
我们可以根据海龟的属性将海龟的功能分为几个不同的类型:
方向
| 函数名 | 功能 |
|---|---|
setheading(),seth() | 设置海龟的绝对方向 |
left(),lt() | 向左转动海龟,改变其方向 |
right(),rt() | 向右转动海龟,改变其方向 |
位置
| 函数名 | 功能 |
|---|---|
dot() | 画出一个点 |
goto(),setpos(),setposition() | 设置海龟的坐标,让海龟从当前位置直接移动到指定坐标 |
pos(),position() | 获取当前海龟的坐标 |
up(), penup(), pu() | 抬笔,海龟移动时不会留下痕迹 |
down(), pendown(), pd() | 落笔,海龟移动时会留下痕迹 |
forward(), fd() | 延着海龟面对的方向向前移动 |
backward(), bk() | 背对海龟面对的方向移动 |
circle() | 让海龟画圆或者画一段弧线,也可以画出正多边形 |
home() | 让海龟的位置回到(0,0)坐标 |
颜色
| 函数名 | 功能 |
|---|---|
pencolor() | 改变画笔的颜色 |
fillcolor() | 设置填充颜色 |
begin_fill() | 开始填充 |
end_fill() | 结束填充 |
color() | 改变画笔和填充颜色 |
bgcolor() | 改变画布的背景颜色 |
画笔与画布控制
| 函数名 | 功能 |
|---|---|
setup() | 设置主窗口的尺寸和位置 |
speed() | 改变海龟画图的速度 |
pensize() | 改变画笔的大小,单位为像素 |
hideturtle(), ht() | 隐藏画笔 |
showturtle(), st() | 显示画笔 |
reset() | 重置海龟的状态,并清除画布 |
下面我们对每个函数逐一介绍:
改变海龟的方向
我们可以从相对和绝对两个概念去改变海龟的方向:
设置绝对方向
可以调用setheading()函数来改变海龟的绝对方向,这个函数接收一个数值型的值;seth()是setheading()的简写,二者用其一即可。
海龟的初始方向为0°,调用了setheading(45)之后,海龟的方向就会变成45°。
import turtle as t
t.seth(45)
向左转left()和向右转right()
让海龟向左或向右转,都是基于当前的方向,所以这种方向的改变是相对的,如果当前海龟的绝对方向为45°,向左转了90°之后,绝对方向就变成了135°:
import turtle as t
t.seth(45)
t.left(90)
right()同理。两个函数都接收数值型参数。
对海龟位置的操作
在画布上画上一个点 dot()
dot()函数可以让海龟在画布上画上一个点,它有两个参数size和color:
size表示点的粗细,如果没给定一个值,那么画出的点的粗细取pensize*2和pensize+4之间的最大值。color表示点的颜色,传参数的要求和pencolor一下致。
import turtle as t
p = t.Pen()
p.pu()
p.goto(100, 100)
p.pd()
p.pensize(10)
p.dot()
t.dot(20, 'red')
让海龟直接移动指定位置
在本章节的海龟的属性-位置部分介绍了画布的四个象限的分配情况,以及如何根据坐标来表达海龟在画布中的位置,基于对这两个知识点的理解,我们可以调用goto(),setpos(),setposition()这三个函数改移到海龟到指定的坐标位置,这三个函数实现在的功能是一样的,调用时都需要传递两个参数x和y,分别代表目标坐标的横纵坐标;我们这里介绍其中的goto()即可:
import turtle as t
t.goto(100, 100)
除了goto()之外,也可以调用setx()和sety()来单独设置海龟的横、纵坐标,这两个函数都只需要传入一上数值型参数即可。
抬笔与落笔
我们已经发现,海龟在画布上移动会画出线条,但是有些线条并不是想要画出图形的一部分,这时我们可以调用抬笔功能,当海龟移动到指定位置后,再调用落笔功能继续作画:
penup()、pu()、up()抬笔,三个函数功能一致,无参数。pendown()、pd()、down()落笔,三个函数功能一致,无参数。
import turtle as t
t.goto(100, 100)
t.pu()
t.goto(-100, 100)
t.pd()
t.goto(-100, 0)
获取海龟的位置
pos()或position()函数可以返回当前海龟所在位置的坐标:
import turtle as t
p = t.position()
print(p)
执行上述代码之后,print函数会在终端打印如下内容:
(0.00,0.00)
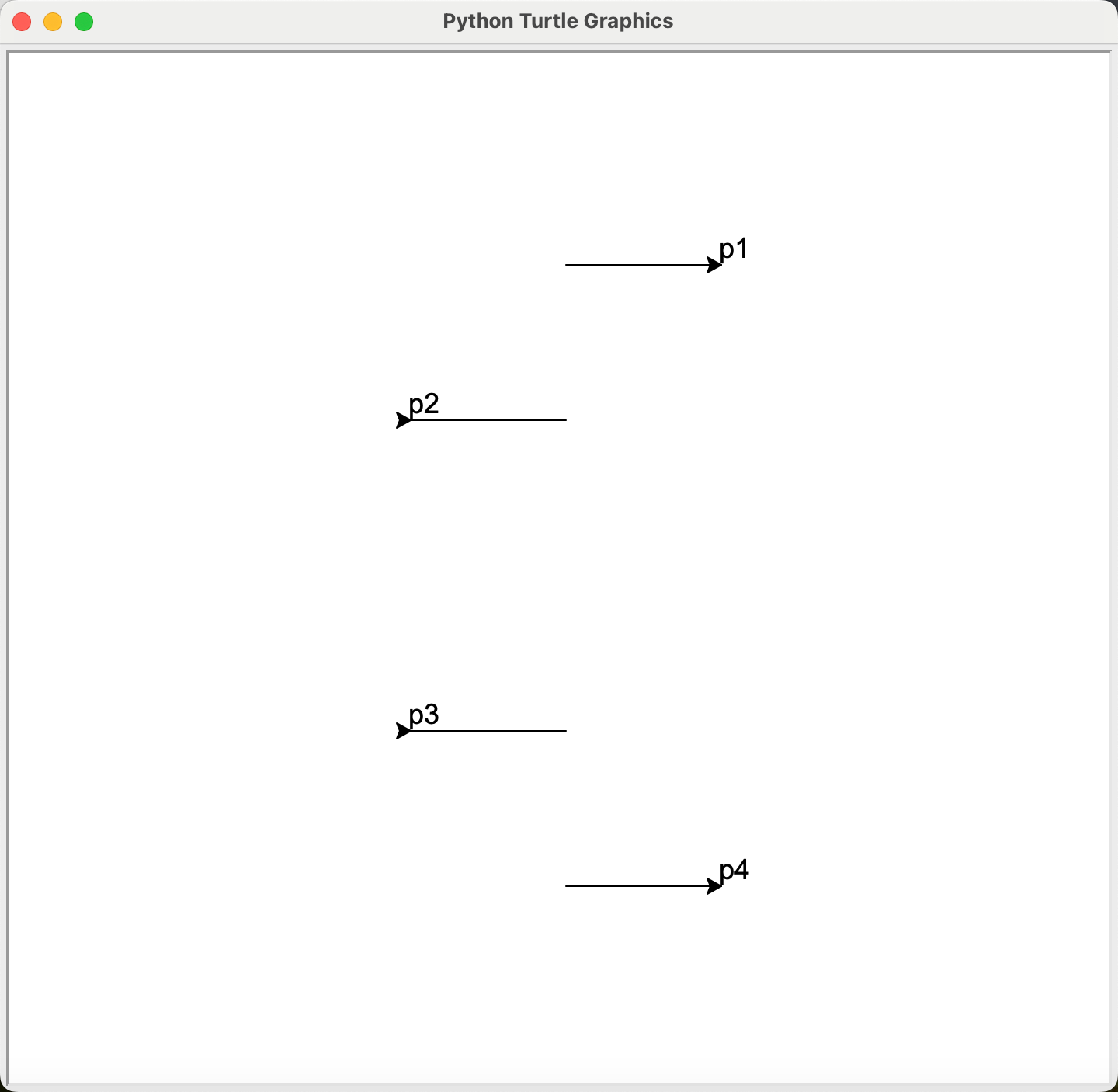
前进 forward , 后退 backward
我们可以用forward()和backward()函数控制海龟前进和后退,这两个函数都要求在被调用时传入一个数值型的参数,表示海龟前进或者后退的距离。
需要特别注意的是,海龟的移动受到两个因素的影响:海龟的方向和传入参数的正负。
import turtle as t
p1 = t.Pen()
p2 = t.Pen()
p3 = t.Pen()
p4 = t.Pen()
p1.pu()
p1.goto(0, 200)
p1.pd()
p1.forward(100)
p1.write("p1", font=('Arial', 18))
p2.pu()
p2.goto(0, 100)
p2.pd()
p2.forward(-100)
p2.write("p2", font=('Arial', 18))
p3.pu()
p3.goto(0, -100)
p3.pd()
p3.backward(100)
p3.write("p3", font=('Arial', 18))
p4.pu()
p4.goto(0, -200)
p4.pd()
p4.backward(-100)
p4.write("p4", font=('Arial', 18))
画出一个圆弧
circle是海龟画图模块中较复杂的一个函数,它可以画布上画出圆弧,在turtle模块中的定义如下:
circle(radius, extent=None, steps=None)
这三个参数分别为:
radius-- 一个数值extent-- 一个数值 (或None)steps-- 一个整型数 (或None)
这个函数的功能为绘制一个radius指定半径的圆。圆心在海龟左边radius个单位;extent为一个夹角,用来决定绘制圆的一部分。如未指定 extent则绘制整个圆。如果extent不是完整圆周,则以当前画笔位置为一个端点绘制圆弧。如果radius为正值则朝逆时针方向绘制圆弧,否则朝顺时针方向。最终海龟的朝向会依据extent的值而改变。
圆实际是以其内切正多边形来近似表示的,其边的数量由steps指定。如果未指定边数则会自动确定为一个弧度为extent的圆弧。在指定了steps之后,海龟会将该圆弧内切成steps条连接的等长线段,如果该圆弧为一个完整的圆,那么绘制出来的则为一个正steps边形。
调用这个函数会复杂一些,这里建议同学可以回到常用内建函数一章中的函数的参数部分进行复习。
- 画出完整的圆:
import turtle as t
t.circle(80)
t.circle(-100)
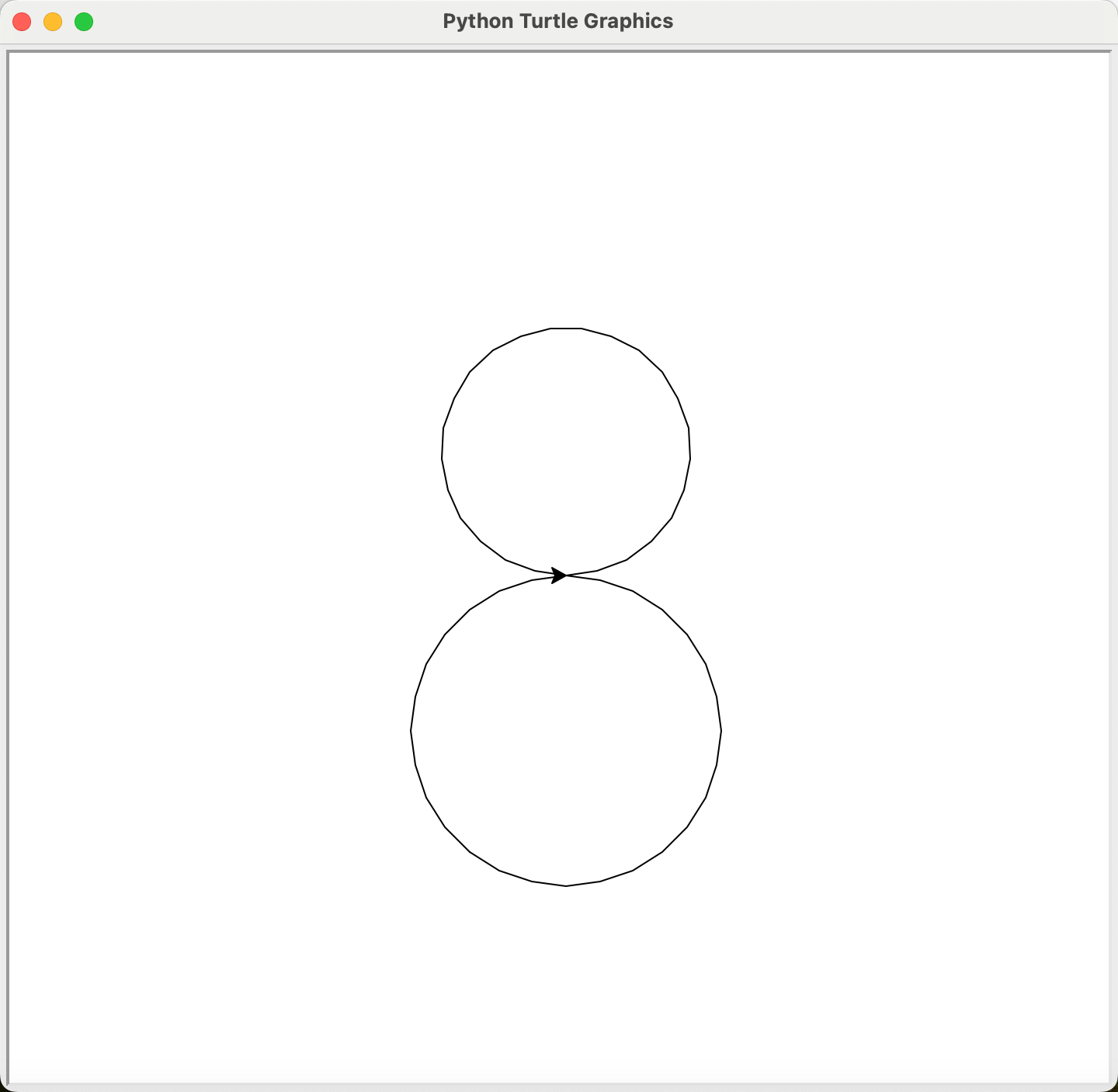
如上图,首先我们可以根据海龟所在的位置可以判断,海龟是沿着圆的弧线移动画出的圆,其次,根据上面代码,第一个圆的半径是正数,那么画完之后,它位于海龟的左侧,另一个圆的半径为负数,那么这个圆位于了海龟的右侧。
- 画出一段圆弧
import turtle as t
t.circle(100, 90) #或者 t.circle(100, extent=90)
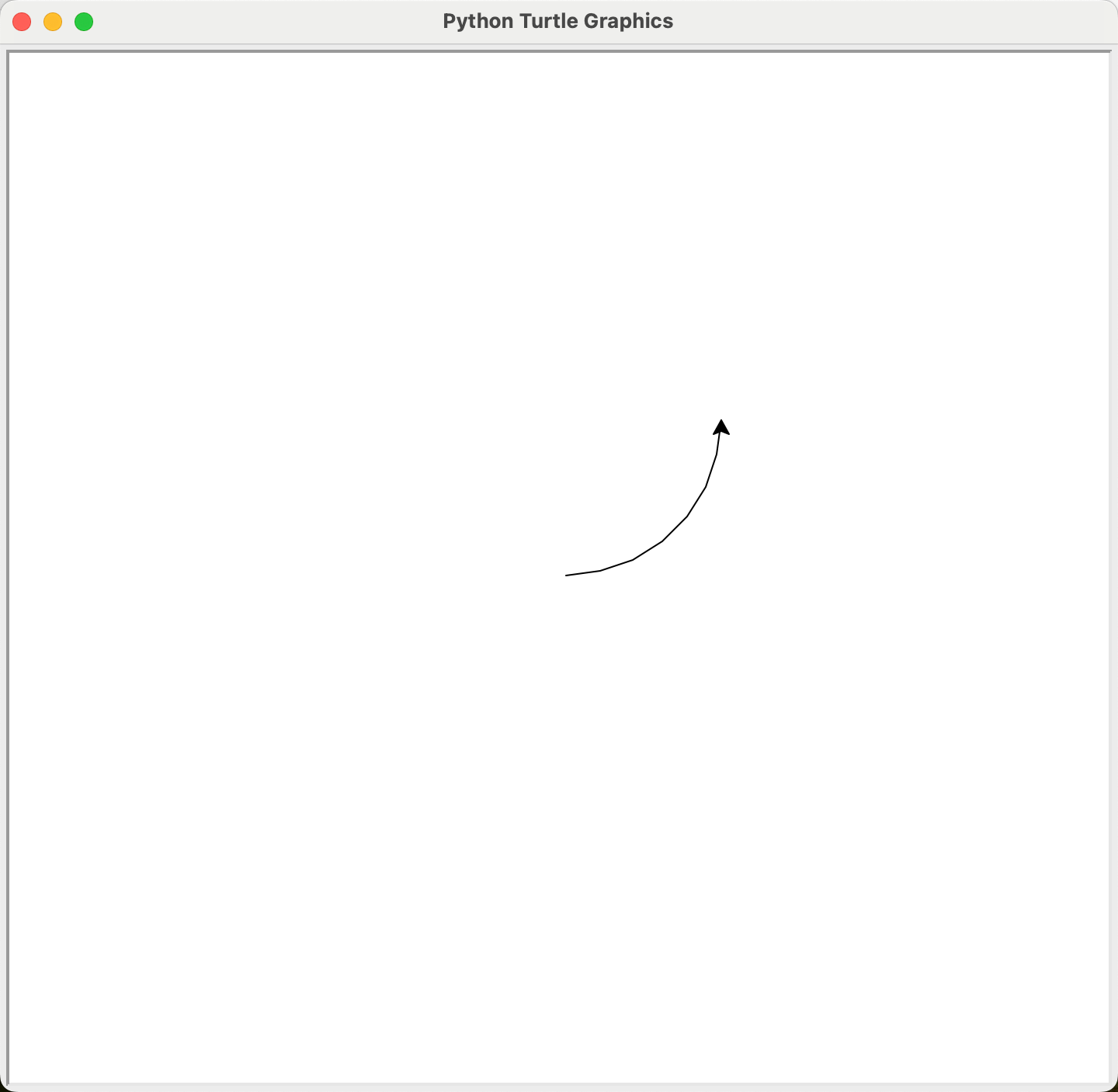
在一段画圆弧时,海龟的方向会随着移动而发生改变的,只有当所画的圆弧正好为一个完整的圆时,海龟才会回到画弧之前所面对的方向。
- 内切圆弧
import turtle as t
t.circle(100, 120, 3)
结合代码,我们可以从上图中观察到,海龟在120度的圆弧均匀地点了3个点,在将相临的两点连接之后,把外面的圆弧给舍弃了,最后保留了三个等长的线段。所以基于这一特点,我们可以在完整的圆内内切出正多边形。
import turtle as t
t.circle(100, None, 5) # 或者 t.circle(100, steps=5)
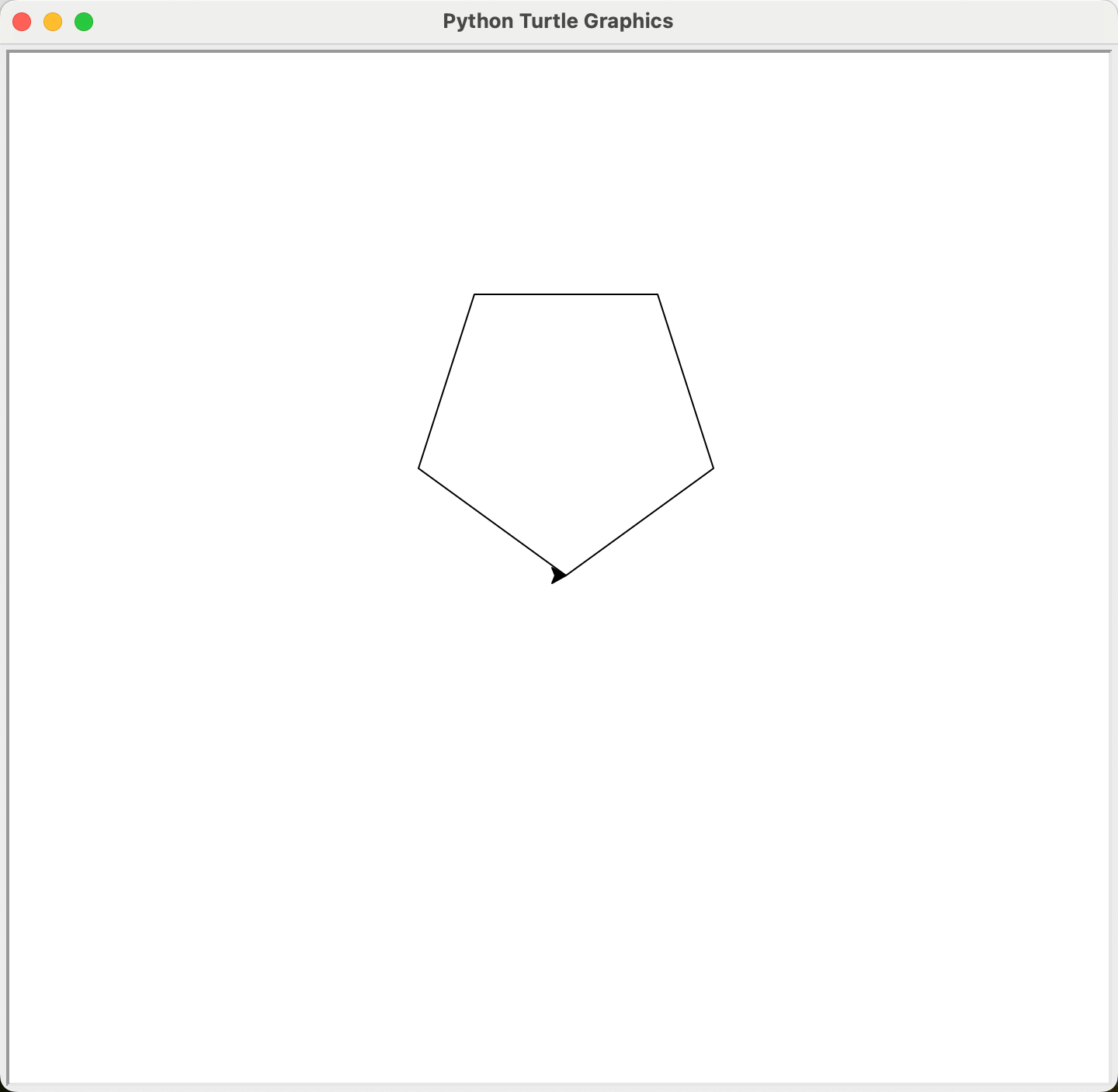
可以通过改变海龟的绝对方向和半径的正负来改变出正多边形的方向,大家可以自行尝试下列代码:
import turtle as t
t.circle(-100, None, 5) # 或者 t.circle(-100, steps=5)
import turtle as t
t.seth(60)
t.circle(-100, None, 5) # 或者 t.circle(-100, steps=5)
回归原点
当海龟移动到原点之外的其它位置之后,我们可以调用home()函数让海龟立即回到原点位置,并重置它的绝对方向为初始方向,调用这个函数不需要传递参数。
import turtle as t
t.circle(100, 120)
t.home()
如果直接调用goto(0, 0),也可以回归到原点,但是它的绝对方向不会被重置,继续保持回归前一刻所面对的方向。
海龟画图-第二部分
让海龟去画图(二)
让海龟涂上颜色
改变画笔的颜色
画笔的默认颜色为黑色,可以调用pencolor()改变画笔的颜色,这个函数的参数有很多格式,我们先只学习最简单的格式,即传入有实际颜色涵义的英文字符串,如:
"red" "green" "yellow" "blue" "orange" "grey" "cyan" "white" "brown" "black"...
import turtle as t
t.forward(100)
t.pu()
t.goto(0, 100)
t.pencolor("red")
t.pd()
t.forward(100)
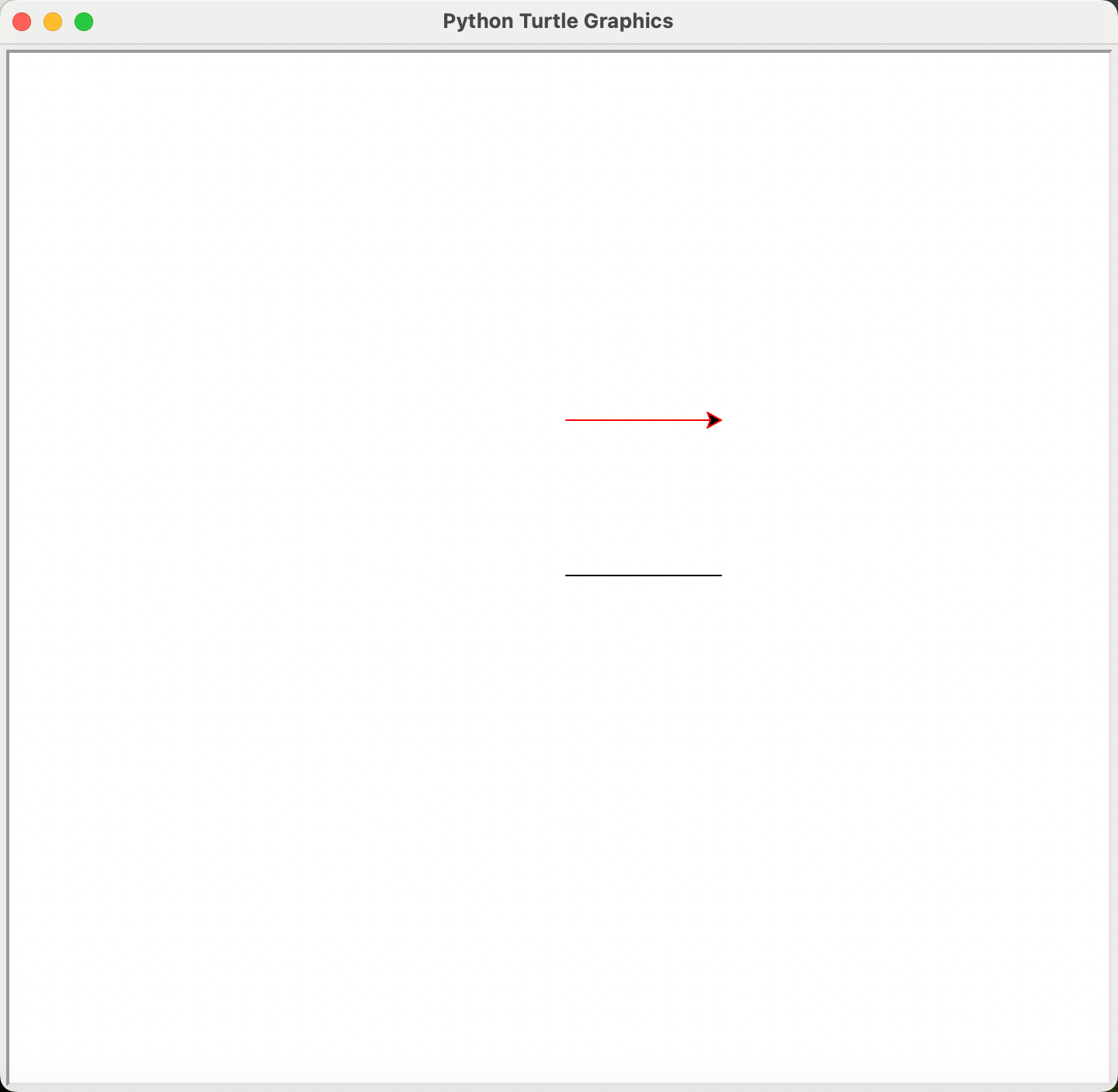
我们让海龟先移动了100px,然后抬笔将海龟移动到坐标(0, 100)的位置,改变画笔的颜色为red,再让海龟向前移动了100px,画出红色的线。
填充颜色
在海龟画出一个平面图形之后,可以给这个图形填充颜色,需要调用下面两个函数来实现:
begin_fill()表示开始填充,需要在要填充的形状之前调用,无参数。end_fill()表示结束填充,在turtle模块中,这个函数才是实际用来填充的函数,也无参数。
能够被填充的图形是由写在上述两个函数之间的代码所绘制的。
填充的颜色默认为黑色,需要改变填充颜色时,可以调用fillcolor()实现,所需传入的参数同pencolor()。
强调一下,被填充的是什么颜色只与在end_fill()函数之前最后一次调用fillcolor()所设置的颜色有关。
我们以下面代码为例:
import turtle as t
t.fillcolor("red") # 设置填充颜色为red
t.begin_fill()
t.circle(100)
t.fillcolor("blue") # 设置填充颜色为blue,替换第一次设置的red
t.end_fill()
t.fillcolor("yellow") # 设置填充颜色为yellow,只对之后的填充生效,并不影响已经结束填充的图形
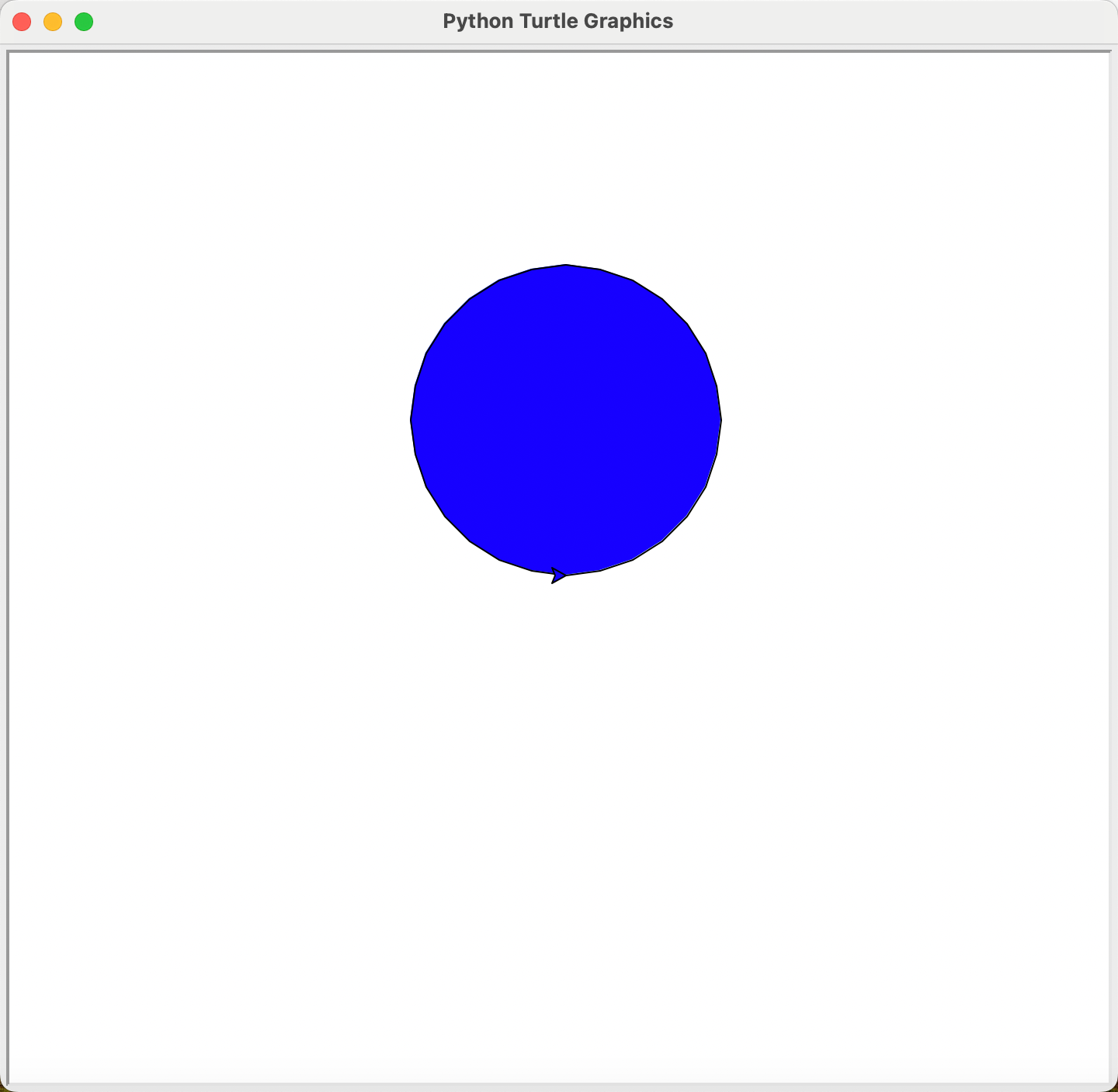
同时改变画笔和填充颜色
color()函数可以同时设置画笔和填充的颜色, 允许输入 0 至 3 个参数,这里我们只学习其中两种:
color("red","blue")设置画笔颜色为red,填充颜色为blue。color("yellow")设置画笔与填充颜色均为yellow。
import turtle as t
t.color("yellow")
设置画布的颜色
海龟画图的画布为白色,如果想设置成其它颜色,可以调用bgcolor()实现,颜色参数的格式同pencolor().
import turtle as t
t.bgcolor("yellow")
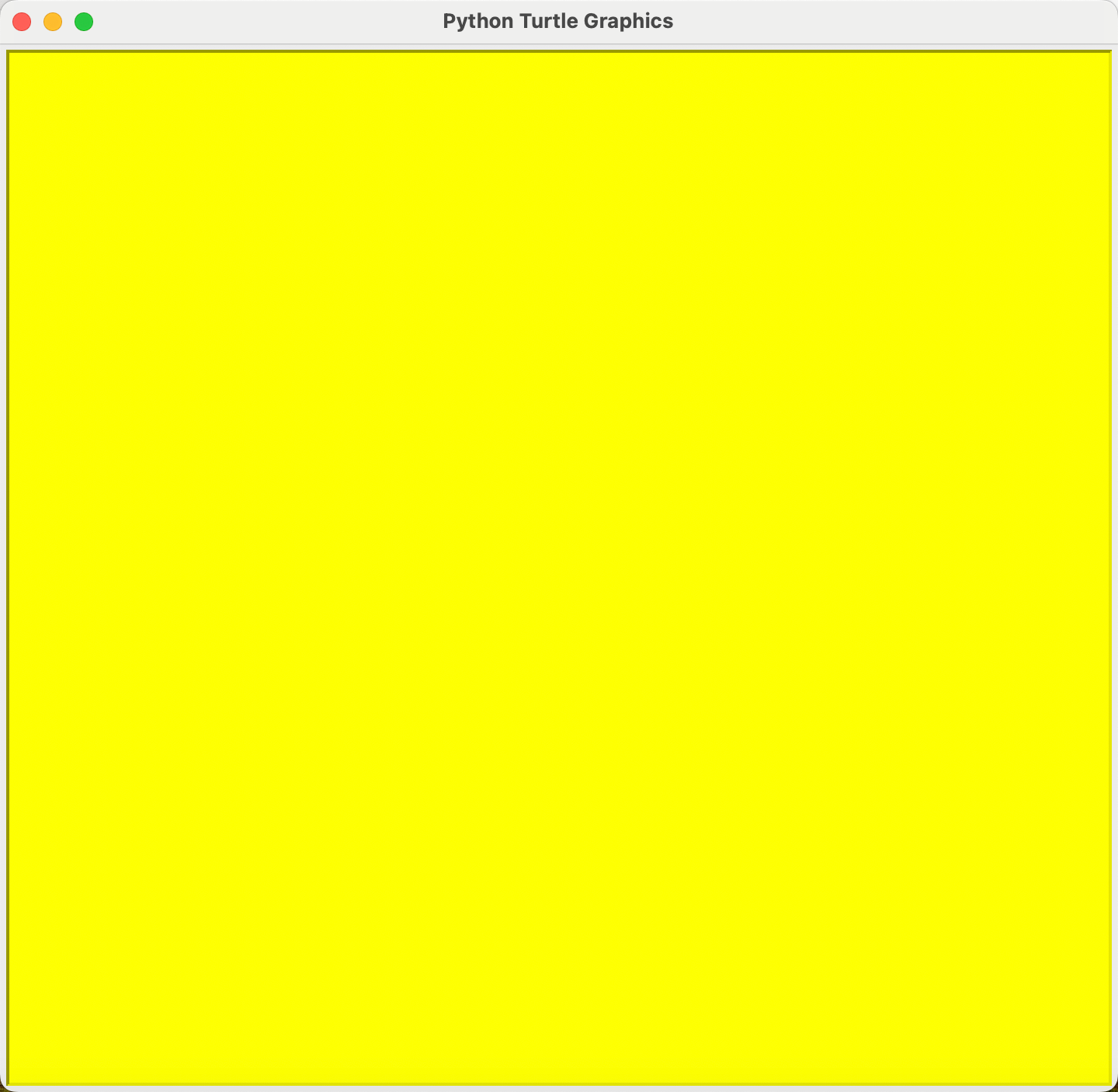
画笔与画在控制
设置画布大小和位置
setup()函数可以设置主窗口的大小和位置,它有四个参数:
import turtle as t
t.setup(width=0.5, height=0.75, startx=None, starty=None)
- width -- 如为一个整型数值,表示大小为多少像素,如为一个浮点数值,则表示屏幕的占比;默认为屏幕的 50%
- height -- 如为一个整型数值,表示高度为多少像素,如为一个浮点数值,则表示屏幕的占比;默认为屏幕的 75%
- startx -- 如为正值,表示初始位置距离屏幕左边缘多少像素,负值表示距离右边缘,None 表示窗口水平居中
- starty -- 如为正值,表示初始位置距离屏幕上边缘多少像素,负值表示距离下边缘,None 表示窗口垂直居中
import turtle as t
t.setup(300, 300, 0, 0)
设置海龟绘制速度
海龟模块中speed()函数可以设置绘制速度,这个函数只能接收0~10之间的整数,当传入0时,海龟的绘制速度是最快的,其次速度值从1到10,画线和海龟转向的动画效果逐级加快;如果输入数值大于10或小于0.5则速度设为0。
也可以传入速度字符串设置绘制速度,速度字符串与速度值的对应关系如下:
- "fastest": 0 最快
- "fast": 10 快
- "normal": 6 正常
- "slow": 3 慢
- "slowest": 1 最慢
import turtle as t
t.speed(0)
t.speed("normal")
设置画笔的粗细
画笔的默认为1px,调用pensize()函数可以设置画笔所画线条的粗细。
import turtle as t
t.forward(100)
import turtle as t
t.pensize(5)
t.pencolor("red")
t.forward(100)
隐藏与显示画笔
在上面的学习过程中所示的图片中,可以看到海龟一直显示在画布上,可以调用hideturtle()使海龟不可见,隐藏之后在绘制复杂图形时可以显著加快绘制速度。
import turtle as t
t.hideturtle() # 或 t.ht()
如果想重新让海龟显示在画布上,可以调用showturtle():
import turtle as t
t.showturtle() # 或 t.st()
重置所有
reset()可以重置海龟的所有状态,并从画布中消除所有绘制的图形。
import turtle as t
t.color("yellow")
t.seth(100)
t.goto(100, 100)
t.reset()
编程中的三大结构
Python是一种高级、通用、解释性的编程语言,它支持多种编程范式,包括过程式、面向对象和函数式编程。在Python中,程序的控制结构主要由三大基本结构构成:顺序结构、选择结构和循环结构。这三大结构为程序提供了基本的控制流程,使得程序能够按照特定的方式执行。在本文中,我们将深入探讨这三大结构的使用方法、示例和最佳实践。
顺序结构
顺序结构是程序执行的默认结构,代码按照从上到下的顺序执行,每一行代码都会被依次执行。在Python中,大多数代码都是按照顺序结构编写的。以下是一个简单的顺序结构的示例:
print("这是第一行")
print("这是第二行")
print("这是第三行")
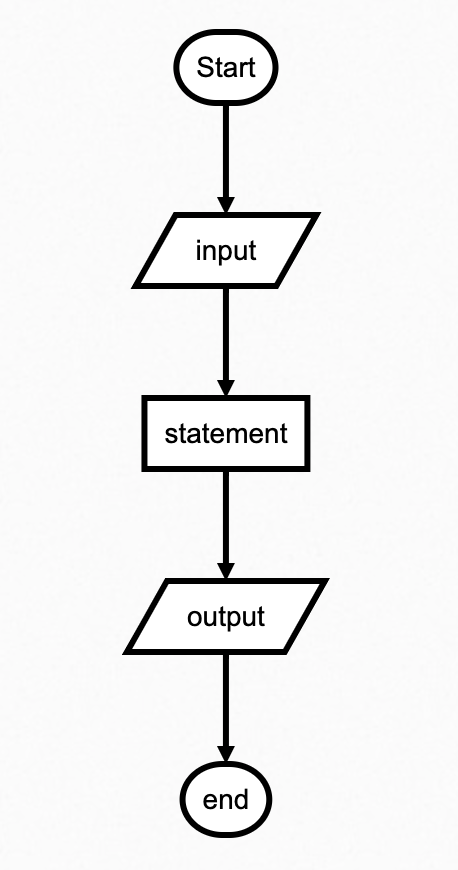
在这个例子中,代码会按照从上到下的顺序执行,依次输出每一行的内容。顺序结构是程序的基础,是编写代码的最简单形式。
下图为顺序结构的流程图
选择结构(if 语句)
选择结构也叫分支结构,允许程序根据条件的真假选择性地执行不同的代码块。在Python中,使用if语句来实现选择结构。基本的if语句结构如下:
if 条件:
# 如果条件为真,执行这里的代码块
else:
# 如果条件为假,执行这里的代码块
elif(else if的缩写)关键字可以用于处理多个条件的情况:
if 条件1:
# 如果条件1为真,执行这里的代码块
elif 条件2:
# 如果条件1为假,但条件2为真,执行这里的代码块
else:
# 如果所有条件都为假,执行这里的代码块
选择结构使得程序能够根据不同的条件执行不同的代码路径,实现分支逻辑。
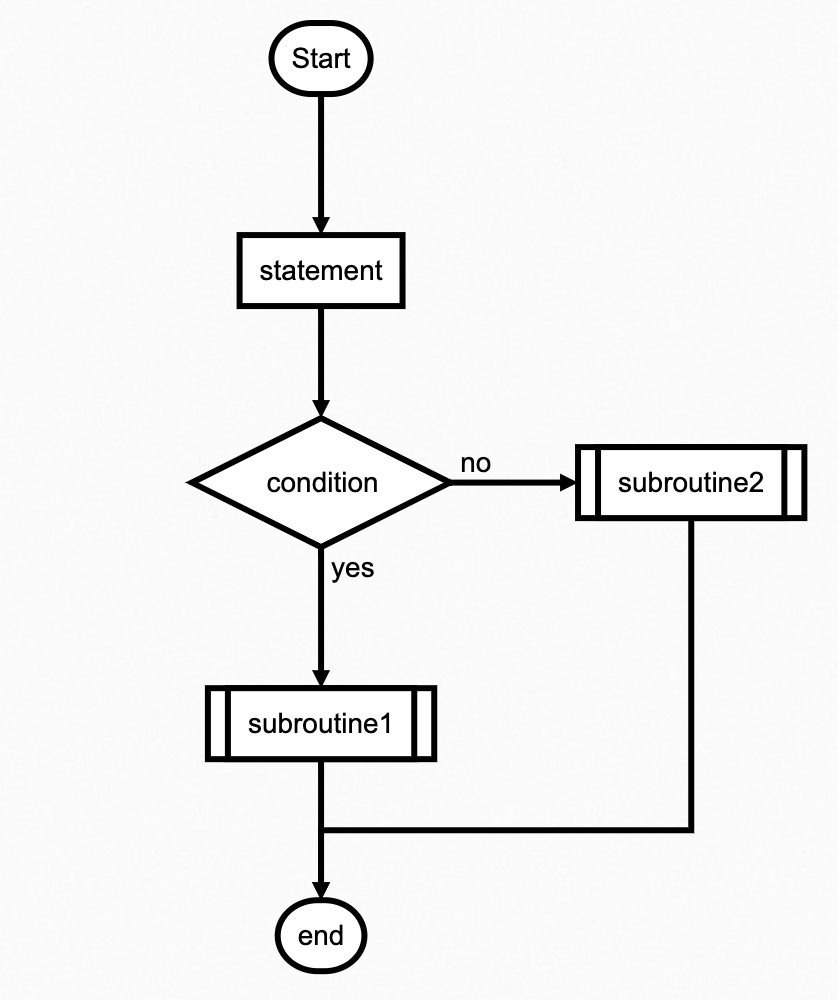
示例演示:
考虑一个简单的示例,根据用户的年龄判断其所属的年龄段:
user_age = int(input("请输入您的年龄:"))
if user_age < 0:
print("年龄不能为负数")
elif 0 <= user_age < 18:
print("您是未成年人")
elif 18 <= user_age < 65:
print("您是成年人")
else:
print("您是老年人")
在这个例子中,通过if语句判断用户所属的年龄段并输出相应的信息。
循环结构
循环结构允许程序重复执行特定的代码块,直到满足退出条件。Python中主要有两种循环结构:for循环和while循环。
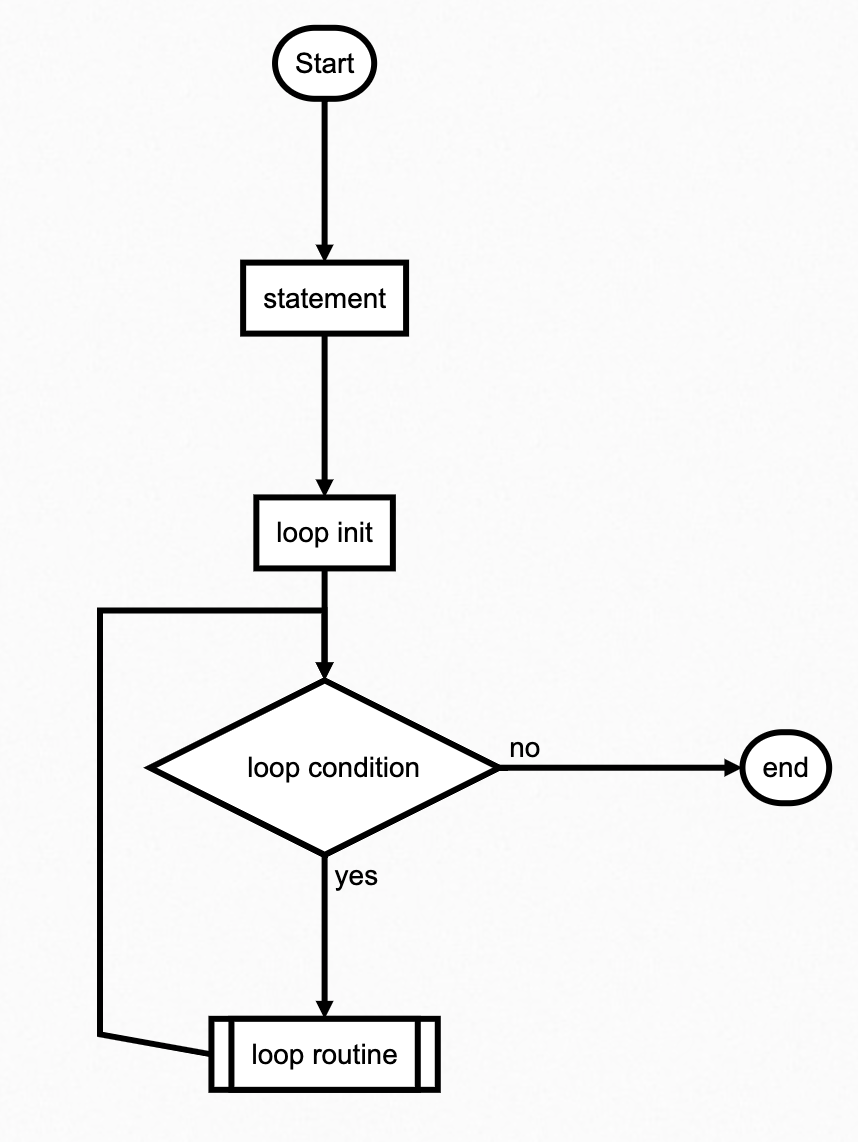
for 循环
for循环用于遍历可迭代对象,每次迭代执行相同的代码块。基本语法如下:
for 变量 in 可迭代对象:
# 执行这里的代码块
例如,遍历一个列表:
fruits = ["苹果", "香蕉", "橙子"]
for fruit in fruits:
print(fruit)
for循环会依次将列表中的元素赋值给fruit变量,并执行相应的代码块。这种循环适用于已知迭代次数的情况。
while 循环
while循环用于在条件为真的情况下重复执行代码块,直到条件变为假。基本语法如下:
while 条件:
# 执行这里的代码块
例如,计算一个数的阶乘:
number = 5
factorial = 1
while number > 0:
factorial *= number
number -= 1
print("5的阶乘是:", factorial)
while循环会在每次迭代前检查条件,只有在条件为真时才执行循环体。这种循环适用于未知迭代次数的情况。
示例演示:
考虑一个简单的示例,使用while循环输出斐波那契数
列的前十个数字:
a, b = 0, 1
count = 0
while count < 10:
print(a, end=" ")
a, b = b, a + b
count += 1
在这个例子中,使用while循环输出斐波那契数列的前十个数字,直到count达到10为止。
结构的嵌套和组合
在实际的程序中,三大结构通常会被灵活地嵌套和组合使用,以满足更复杂的逻辑需求。例如,可以在循环结构中嵌套选择结构,或者在选择结构中嵌套循环结构,以实现更丰富的功能。
示例演示:
考虑一个简单的示例,使用嵌套结构判断一个数是否为质数:
num = int(input("请输入一个整数:"))
if num > 1:
for i in range(2, int(num/2)+1):
if (num % i) == 0:
print(num, "不是质数")
break
else:
print(num, "是质数")
else:
print(num, "不是质数")
通过嵌套使用if语句和for循环,判断用户输入的整数是否为质数。
总结与最佳实践
- 清晰的代码结构: 为了提高代码的可读性,建议使用适当的缩进和空格,使代码结构清晰。
- 合理使用注释: 对于复杂的逻辑或特殊情况,使用注释来解释代码的意图,提高代码的可维护性。
- 谨慎使用嵌套: 避免过度嵌套,以保持代码的简洁和可读性。过深的嵌套结构可能会导致代码难以理解和维护。
- 利用函数封装逻辑: 对于重复使用的逻辑,考虑将其封装成函数,提高代码的模块化和复用性。
- 灵活使用三大结构: 根据具体问题的需求,灵活使用顺序结构、选择结构和循环结构,构建清晰且高效的程序。
通过深入理解和熟练运用顺序结构、选择结构和循环结构,程序员能够更加灵活地设计和实现各种算法和应用,使得代码具有更好的可读性、可维护性和可扩展性。这三大结构为Python程序提供了强大的控制能力,使得开发者能够应对不同的编程场景,创造出高效且功能强大的应用程序。
编程中的三大结构
Python是一种高级、通用、解释性的编程语言,它支持多种编程范式,包括过程式、面向对象和函数式编程。在Python中,程序的控制结构主要由三大基本结构构成:顺序结构、选择结构和循环结构。这三大结构为程序提供了基本的控制流程,使得程序能够按照特定的方式执行。在本文中,我们将深入探讨这三大结构的使用方法、示例和最佳实践。
顺序结构
顺序结构是程序执行的默认结构,代码按照从上到下的顺序执行,每一行代码都会被依次执行。在Python中,大多数代码都是按照顺序结构编写的。以下是一个简单的顺序结构的示例:
print("这是第一行")
print("这是第二行")
print("这是第三行")
在这个例子中,代码会按照从上到下的顺序执行,依次输出每一行的内容。顺序结构是程序的基础,是编写代码的最简单形式。
下图为顺序结构的流程图
选择结构(if 语句)
选择结构也叫分支结构,允许程序根据条件的真假选择性地执行不同的代码块。在Python中,使用if语句来实现选择结构。基本的if语句结构如下:
if 条件:
# 如果条件为真,执行这里的代码块
else:
# 如果条件为假,执行这里的代码块
elif(else if的缩写)关键字可以用于处理多个条件的情况:
if 条件1:
# 如果条件1为真,执行这里的代码块
elif 条件2:
# 如果条件1为假,但条件2为真,执行这里的代码块
else:
# 如果所有条件都为假,执行这里的代码块
选择结构使得程序能够根据不同的条件执行不同的代码路径,实现分支逻辑。
示例演示:
考虑一个简单的示例,根据用户的年龄判断其所属的年龄段:
user_age = int(input("请输入您的年龄:"))
if user_age < 0:
print("年龄不能为负数")
elif 0 <= user_age < 18:
print("您是未成年人")
elif 18 <= user_age < 65:
print("您是成年人")
else:
print("您是老年人")
在这个例子中,通过if语句判断用户所属的年龄段并输出相应的信息。
循环结构
循环结构允许程序重复执行特定的代码块,直到满足退出条件。Python中主要有两种循环结构:for循环和while循环。
for 循环
for循环用于遍历可迭代对象,每次迭代执行相同的代码块。基本语法如下:
for 变量 in 可迭代对象:
# 执行这里的代码块
例如,遍历一个列表:
fruits = ["苹果", "香蕉", "橙子"]
for fruit in fruits:
print(fruit)
for循环会依次将列表中的元素赋值给fruit变量,并执行相应的代码块。这种循环适用于已知迭代次数的情况。
while 循环
while循环用于在条件为真的情况下重复执行代码块,直到条件变为假。基本语法如下:
while 条件:
# 执行这里的代码块
例如,计算一个数的阶乘:
number = 5
factorial = 1
while number > 0:
factorial *= number
number -= 1
print("5的阶乘是:", factorial)
while循环会在每次迭代前检查条件,只有在条件为真时才执行循环体。这种循环适用于未知迭代次数的情况。
示例演示:
考虑一个简单的示例,使用while循环输出斐波那契数
列的前十个数字:
a, b = 0, 1
count = 0
while count < 10:
print(a, end=" ")
a, b = b, a + b
count += 1
在这个例子中,使用while循环输出斐波那契数列的前十个数字,直到count达到10为止。
结构的嵌套和组合
在实际的程序中,三大结构通常会被灵活地嵌套和组合使用,以满足更复杂的逻辑需求。例如,可以在循环结构中嵌套选择结构,或者在选择结构中嵌套循环结构,以实现更丰富的功能。
示例演示:
考虑一个简单的示例,使用嵌套结构判断一个数是否为质数:
num = int(input("请输入一个整数:"))
if num > 1:
for i in range(2, int(num/2)+1):
if (num % i) == 0:
print(num, "不是质数")
break
else:
print(num, "是质数")
else:
print(num, "不是质数")
通过嵌套使用if语句和for循环,判断用户输入的整数是否为质数。
总结与最佳实践
- 清晰的代码结构: 为了提高代码的可读性,建议使用适当的缩进和空格,使代码结构清晰。
- 合理使用注释: 对于复杂的逻辑或特殊情况,使用注释来解释代码的意图,提高代码的可维护性。
- 谨慎使用嵌套: 避免过度嵌套,以保持代码的简洁和可读性。过深的嵌套结构可能会导致代码难以理解和维护。
- 利用函数封装逻辑: 对于重复使用的逻辑,考虑将其封装成函数,提高代码的模块化和复用性。
- 灵活使用三大结构: 根据具体问题的需求,灵活使用顺序结构、选择结构和循环结构,构建清晰且高效的程序。
通过深入理解和熟练运用顺序结构、选择结构和循环结构,程序员能够更加灵活地设计和实现各种算法和应用,使得代码具有更好的可读性、可维护性和可扩展性。这三大结构为Python程序提供了强大的控制能力,使得开发者能够应对不同的编程场景,创造出高效且功能强大的应用程序。
选择结构
引言
在Python编程语言中,if是选择结构最主要的语句,它是一项基本而强大的控制结构,用于根据特定条件的真假执行不同的代码块。这是一种编写灵活和适应性强的程序逻辑的关键工具。本章将深入探讨if语句的各个方面,包括基本语法、多分支结构、条件表达式、嵌套结构、缩进的重要性以及通过示例演示其实际用法。
试想以下场景:
- 如果到了18周岁,就可以开车了
- 如果周末不下雨,就约同学去骑行,否则就在家写作业
- 给学生的数学成绩分为优、良、中、差
- 去市场买菜的时候,比较哪家又好又便宜就买那家
这些问题都需要用选择结构去解决。
基本语法结构
二元分支结构
if语句二元分支结构的基本语法结构如下:
if 条件:
# 如果条件为真,执行这里的代码块
或
if 条件:
# 如果条件为真,执行这里的代码块
else:
# 如果条件为假,执行这里的代码块
第一种结构中,当条件满足时,也就是这个表达式返回True或者本身就是个真值,则会执行:下面一行被缩进的代码,否则什么都不做。但是在第二种结构中,有了else语句,那么当条件不成立时,就行执行else:以下被缩进的语句;这里else的后面不需要写出条件表达式。
示例演示
- 如果到了18周岁,就可以开车了
age = int(input("请输入你的年龄:"))
if age >= 18:
print("你可以开车了!")
# 第一次执行,输入19,会打印出"你可以开车了!"
请输入你的年龄:19
你可以开车了!
# 第二次执行,输入17,什么都不会打印
请输入你的年龄:17
- 如果周末不下雨,就约同学去骑行,否则就在家写作业
weather = input("请输入明天的天气:")
if weather != 'rain':
print("约同学去骑行")
else
print("在家写作业")
# 第一次执行,输入sunshine,会打印出"约同学去骑行"
请输入明天的天气:sunshine
约同学去骑行
# 第二次执行,输入rain,会打印出"在家写作业"
请输入明天的天气:rain
在家写作业
多分支结构
if语句可以扩展为多分支结构,通过使用elif(else if的缩写)关键字,可以处理多个条件。例如:
if 条件1:
# 如果条件1为真,执行这里的代码块
elif 条件2:
# 如果条件1为假,但条件2为真,执行这里的代码块
......
elif 条件n:
# 如果条件1~n-1为假,但条件n为真,执行这里的代码块
else:
# 如果所有条件都为假,执行这里的代码块
这种结构允许程序根据多个条件进行逻辑分支,更灵活地处理各种情况。
示例演示
- 给学生的数学成绩分为优、良、中、差
score = int(input("请输入你的成绩:"))
if score >= 90:
print("成绩:优")
elif score >= 80:
print("成绩:良")
elif score >= 60:
print("成绩:中")
else:
print("成绩:差")
条件表达式
条件通常是表达式,可以是比较运算、逻辑运算、成员运算等返回布尔值的操作。例如:
x = 10
if x > 0:
print("x 是正数")
else:
print("x 不是正数")
在这个例子中,条件是x > 0,如果这个条件为真,就执行print("x 是正数"),否则执行print("x 不是正数")。条件表达式的灵活性使得if语句可以适应各种判断场景。
也可以直接使用bool类型的值:
flag = True
if flag:
print("flag 是真值")
嵌套结构
if语句可以嵌套在其他if语句内,形成更复杂的条件结构。这样的嵌套结构使得程序能够更细致地处理各种情况。例如:
x = 5
if x > 0:
if x % 2 == 0:
print("x 是正偶数")
else:
print("x 是正奇数")
else:
print("x 不是正数")
在这个例子中,外层if语句检查x是否为正数,如果是,进一步嵌套的if语句判断x是否为偶数或奇数。嵌套结构可根据具体问题的复杂性灵活运用,但需要注意避免过度嵌套,以保持代码的可读性。
缩进的重要性
在Python中,缩进是一种语法结构,而不仅仅是代码格式。它决定了代码块的开始和结束,是Python语言独有的特点。因此,要确保同一代码块的缩进相同,否则会导致语法错误或逻辑错误。例如:
if 条件:
# 代码块 A
if 另一个条件:
# 代码块 B
else:
# 代码块 C
else:
# 代码块 D
在这个例子中,代码块 B 和代码块 C 同属于外层的if语句,因此它们的缩进相同。与之相反,代码块 D 是属于外层的else语句的,所以它的缩进与else语句一致。
示例演示
为了更全面地理解if语句的实际应用,考虑以下示例:一个简单的登录系统。用户需要输入用户名和密码,程序会根据预设的用户名和密码进行验证,根据验证结果给出相应的提示。
# 预设的用户名和密码
correct_username = "user123"
correct_password = "pass456"
# 用户输入
input_username = input("请输入用户名:")
input_password = input("请输入密码:")
success = message = None
# 登录验证
if username == correct_username and password == correct_password:
success, message = True, "登录成功"
else:
success, message = False, "用户名或密码错误"
if success:
print(message)
else:
print(message)
在这个示例中,authenticate函数接受用户输入的用户名和密码,与预设的正确用户名和密码进行比较,返回验证结果。主程序根据验证结果使用if语句输出相应的提示信息。这个简单的示例展示了if语句在实际应用中的作用,根据条件的真假执行不同的代码块。
实际场景的应用
数据处理与分析
在数据处理与分析的场景中,if语句常用于根据数据的特征或条件执行不同的数据处理步骤。例如:
if data_type == "numeric":
# 执行数值型数据处理
process_numeric_data(data)
elif data_type == "text":
# 执行文本型数据处理
process_text_data(data)
else:
# 执行其他数据处理
process_other_data(data)
用户权限管理
在用户权限管理中,if语句可以根据用户的角色或权限级别来控制其对系统资源的访问。例如:
if user_role == "admin":
# 执行管理员权限的操作
perform_admin_actions()
elif user_role == "user":
# 执行普通用户权限的操作
perform_user_actions()
else:
# 执行其他角色的操作
perform_generic_actions()
程序异常处理
在程序中,if语句通常用于处理异常情况。例如,在文件读取时,可以使用if语句检查文件是否存在:
file_path = "example.txt"
if os.path.exists(file_path):
with open(file_path, 'r') as file:
# 执行文件读取操作
content = file.read()
else:
print("文件不存在,无法读取。")
总结
if语句是Python中一项基本而强大的控制结构,通过它,程序能够根据不同的条件采取不同的行动,使得代码更灵活、可读性更强。理解其基本语法、多分支结构、条件表达式、嵌套结构和缩进的重要性,能够帮助开发者更有效地使用if语句构建复杂的程序逻辑。
在实际应用中,if语句通常用于处理用户输入、业务逻辑判断、状态管理等方面。它的灵活性使得程序可以根据不同的情况执行不同的代码块,从而满足各种需求。在编写代码时,务必注意缩进,因为它不仅仅是格式规范,更是Python语法的一部分。通过合理使用if语句,可以写出结构清晰、逻辑严谨的代码,提高代码的可维护性和可读性。
循环
在 Python 中,循环是一种重要的控制结构,用于重复执行一组语句。Python 提供了两种主要的循环结构:for 循环和 while 循环。
for 循环
for 循环是 Python 中用于迭代访问序列元素的重要工具。通过 for 循环,你能够方便地遍历列表、元组、字符串等可迭代对象的元素,执行特定的代码块。
for 循环的基本语法如下:
for 变量 in 可迭代对象:
# 执行这里的代码块
else:
# 执行这里的代码块
- 变量: 在每次迭代中,可迭代对象中的一个元素会被赋值给变量。你可以使用这个变量在代码块中进行操作。
- 可迭代对象: 任何可以被迭代的对象,例如列表、元组、字符串等。
for循环会按顺序迭代可迭代对象中的元素。 - else: 循环结束之后执行的代码。
- 循环语句同样有缩进的要求。
下面是一个简单的例子,演示如何使用 for 循环遍历列表中的元素:
for i in range(5):
print(i)
else:
print("end")
这段代码会输出:
0
1
2
3
4
end
执行过程
for 循环的工作原理是,它会依次取出可迭代对象中的每个元素,并将元素赋值给指定的变量,然后执行循环体中的代码块。这个过程会一直持续,直到可迭代对象中的所有元素都被访问完。
让我们通过一个简单的例子来理解 for 循环的工作原理:
for num in range(1, 6):
square = num ** 2
print(f"{num} 的平方是 {square}")
这段代码会输出:
1 的平方是 1
2 的平方是 4
3 的平方是 9
4 的平方是 16
5 的平方是 25
在每次迭代中,num 变量都被赋值为 numbers 列表中的一个元素,然后计算平方并输出。
range() 函数与 for 循环结合
range() 函数是 Python 中常用的生成数字序列的函数。结合 for 循环,range() 可以用于指定循环的次数或遍历一定范围的数字。range() 的基本语法如下:
range(start, stop, step)
三个参数只可能为整型数值
- start 序列起始值,默认为 0,可选值。
- stop 序列终止值,不包含在序列中。
- step 步长,即两个相邻数字之间的差值,默认为 1;也为可选值。
根据上面的说明,range 函数可以大致有三种调用方式:
range(stop):从0开始到stop-1结束,循环stop次;range(start, stop):从start开始到stop-1结束,循环stop-start次;range(start, stop, step):从start开始到stop-1结束,每次循环步长为step, 如果step为正数,需要满足stop>start,否则要求stop<start。
这里可以用数学中区间来描述start与stop的范围 [start, stop),即左闭右开。
示例演示
利用 for 循环计算从1加到100的总和。
summ = 0
for i in range(1, 101):
summ += i
print(f"1到100的总和为{summ}")
利用 for 循环打印出1-20以内所有的奇数。
""" 利用步长 """ for i in range(1, 21, 2): print(i)""" 利用if条件语句与 for循环语句的嵌套 """ for i in range(21): if i % 2 == 1: print(i)
依次输入期末考试的各科成绩,总计算出平均值。
n = int(input("输入学科数量:"))
score = 0
for i in range(n):
x = int(input("输入第%d科成绩:" %(i+1)))
score = score + x
print("平均成绩为:%.2f" %(score/n))
嵌套循环
for 循环可以嵌套在其他 for 循环内,形成嵌套循环。嵌套循环在处理二维结构(例如二维列表)或需要遍历多个维度的情况下非常有用。以下是一个简单的例子:
for i in range(3):
for j in range(2):
print(f"({i}, {j})")
这段代码会输出:
(0, 0)
(0, 1)
(1, 0)
(1, 1)
(2, 0)
(2, 1)
示例演示
利用 for 循环的嵌套,打印出乘法口诀表。
for i in range(1, 10):
for j in range(1, i+1):
print(f'{j}x{i}={i*j}', end=" ")
print("")
while 循环
while 循环是 Python 中的一种迭代结构,用于重复执行一组语句,直到指定的条件不再满足。它提供了一种灵活的方式来处理需要多次执行的任务。
while 循环的基本语法如下:
while 条件:
# 循环体
# 在每次迭代中,当条件为真时,执行循环体
条件 是一个表达式,当这个表达式的值为真时,循环体将会被执行。当条件为假时,循环结束。
示例演示
以下是一个简单的示例,演示了 while 循环的基本用法:
count = 0
while count < 5:
print(f"Count: {count}")
count += 1
在这个例子中,count 初始化为 0。while count < 5: 表达式检查 count 是否小于 5,如果是真,则执行循环体。在每次循环中,打印 count 的值,并将 count 增加 1。当 count 达到 5 时,循环结束。
循环中的 else 语句
while 循环也支持 else 语句,它在循环条件变为假时执行,除非循环被中断。以下是一个使用 else 的示例:
count = 0
while count < 5:
print(f"Count: {count}")
count += 1
else:
print("Loop completed.")
在这个例子中,当 count 不再小于 5 时,else 语句将被执行,输出 Loop completed.。
无限循环
无限循环也叫死循环,在某些情况下,需要一直循环下去来保证程序不间断的运行下去,在 Python 中可以使用 while True: 或者 while 1:实现无限循环。
while True:
# 无限循环
print("I am looping.")
循环控制
在 Python 编程语言中,break 和 continue 是两个用于控制循环执行的关键字。它们分别用于中断循环和跳过当前迭代,使程序更加灵活和高效。
- break: 完全中断循环,跳出循环体。
- continue: 跳过当前迭代,继续下一次迭代。
如果有循环嵌套,这两个关键字只在其所处的那一层循环发生作用,不会影响该层循环的外部和内部循环。
break 关键字
break 是一个用于中断循环的关键字。当 break 语句被执行时,循环会立即终止,程序将跳出循环体,继续执行循环之后的代码。
while 条件:
# 循环体
if 某个条件:
break # 中断循环
# 循环体的其余部分
for 变量 in 可迭代对象:
# 循环体
if 某个条件:
break # 中断循环
# 循环体的其余部分
让我们通过一个简单的示例来说明 break 的用法。假设我们要在一个列表中查找某个特定的元素:
A博物馆由于展出的内容比较受欢迎,所以在参观高峰的展出期间采取限流的文案保证馆内不会过于拥挤。具体文案是,参观人员在馆外排队依次进入,管理人员每隔5分钟打开隔离带开放观众进入,同时会进行计数,当本次进入人员达到20人时,会关闭隔离带,其它观众需要等待下一轮开放。
count = 0
while True:
count = count + 1
print("进入%d位观众。" % count)
if count == 20:
break
else:
print("停止进入")
上述代码的else部分不会执行,这是因为break是中断整个循环,else也属于循环的一部分。
进入1位观众。
进入2位观众。
进入3位观众。
进入4位观众。
进入5位观众。
进入6位观众。
进入7位观众。
进入8位观众。
进入9位观众。
进入10位观众。
进入11位观众。
进入12位观众。
进入13位观众。
进入14位观众。
进入15位观众。
进入16位观众。
进入17位观众。
进入18位观众。
进入19位观众。
进入20位观众。
continue 关键字
continue 是一个用于跳过当前迭代的关键字。当 continue 语句被执行时,循环会跳过当前迭代的剩余部分,直接进入下一次迭代。
while 条件:
# 循环体
if 某个条件:
continue # 跳过当前迭代
# 循环体的其余部分
for 变量 in 可迭代对象:
# 循环体
if 某个条件:
continue # 跳过当前迭代
# 循环体的其余部分
某个连队在训练过程中,为了加强战士执行命令的效率,进行一种特殊的训练方式,教官先说出一个1-9之间的数字,然后战士们开始报数,当报到与这个数有关的数字时,该名战士就不要报数,然后下一个战士从下一个数字继续报数。 假设一个连队有150人,请用程序模拟出这个连队的报数情况。 提示:与这个数有关的数字有两种,第一种为个位上的数字为这个数,第二种为这个数的倍数。
print("请教官说出一个1-9之间任意数字")
n = int(input("数字为:"))
print("开始报数")
for i in range(1, 151):
if i % 10 == n or i % n == 0:
continue
print(i, end=' ')
使用场景
- 跳过不满足条件的迭代: 在循环中,当某个条件不满足时,使用
continue跳过当前迭代。 - 处理特殊情况: 在处理数据时,遇到特殊情况可使用
continue避免执行不必要的代码。
break 和 continue 是 Python 中控制循环执行的两个关键字。它们提供了在循环中灵活控制流程的手段,使得程序在面对不同情况时能够更加高效、清晰地执行。合理使用 break 和 continue 可以使代码更具可读性和可维护性。在编写循环时,根据具体需求选择使用 break 或 continue,能够更好地实现代码的逻辑。
高级数据类型
在类型和变量一章中,我们介绍了Python中的基本数据类型,除字符串之外,它们都是不能再被再被可视化分割的最小单元。而Python中同样也提供了高级数据类型,用以存储多个的数据到一个对象中,这些高级数据类型根据结构来分成下面几类:
序列sequence
- 字符串 str
- 列表 list
- 元组 tuple
- range
集合set
- 集合 set
映射mapping
- 字典 dict
基本操作
高级数据类型的基本操作主要包括一系列对数据进行处理和管理的操作,这些操作通常涵盖了数据的增insert、删delete、改update、查index/slice/key,以及其内置方法的调用。
- 创建:高级数据类型在使用之前需要先创建,可以使用声明变量的方式创建,也可以用推导式;
- 增:增加新的数据到一个高级数据类型中;
- 删:从高级数据类型中删除数据、或者删除整个高级数据类型;
- 改:修改高级数据类型其中一个数据的值
- 查:查找高级数据类型中的数据,主要有索引,切片和键值对查找;
- 内置方法调用:每种高级数据类型都内置了多个方法用于操作自身。
Python中内置函数的调用。
基本数据类型 vs 高级数据类型:
可变性
基本数据类型(不可变):
- 包括整数(int)、浮点数(float)、布尔值(bool)、字符串(str)、元组(tuple)等。
- 一旦创建,对象的值不能被修改。
- 操作不会改变原始对象,而是创建新的对象。
>>> x = 5 # 整数是不可变的
>>> y = x # 创建了一个新的变量 y,但是 x 和 y 都指向相同的对象
>>> y += 2 # 修改 y,但是 x 不受影响
>>> print(x, y)
5 7
高级数据类型(可变):
- 包括列表(list)、集合(set)、字典(dict)、自定义类实例等。
- 对象的值可以在原地被修改。
- 操作会影响原始对象。
>>> my_list = [1, 2, 3] # 列表是可变的
>>> other_list = my_list # 创建了一个新的变量 other_list,但是两者指向同一个列表对象
>>> other_list.append(4) # 修改了原始列表
>>> print(my_list, other_list)
[1, 2, 3, 4] [1, 2, 3, 4]
复制行为
基本数据类型:
- 复制基本数据类型时,实际上是创建了一个新的对象,原始对象保持不变。
>>> x = 10
>>> y = x # 创建了一个新的变量 y,但是 x 和 y 都指向相同的对象
>>> y += 5
>>> print(x, y)
10 15
高级数据类型:
- 复制可变对象时,创建了一个新的变量,但是两者仍然指向相同的对象。
>>> my_list = [1, 2, 3]
>>> other_list = my_list # 创建了一个新的变量 other_list,但是两者指向同一个列表对象
>>> other_list.append(4)
>>> print(my_list, other_list)
[1, 2, 3, 4] [1, 2, 3, 4]
性能和内存占用
- 基本数据类型通常更轻量,因为它们是不可变的,不需要考虑变化的可能性。
- 高级数据类型需要更多的内存和处理资源,特别是在进行频繁的修改、添加或删除元素时。
使用场景
- 基本数据类型适用于简单的数据表示和数值计算,以及需要保持数据不变性的情况。
- 高级数据类型适用于需要灵活性、可变性和复杂数据结构的情况,如列表、集合、字典等。
选择基本数据类型还是高级数据类型取决于问题的要求,对性能和内存的需求,以及数据的特性。在实际编程中,这两者通常都有其独特的用途和优势。
字符串
字符串或串String是由数字、字母、各种特殊字符组成的一串字符。一般记为 s="a1a2···an"(n>=0)。它是编程语言中表示文本的数据类型。在程序设计中,字符串为符号或数值的一个连续序列,如符号串(一串字符)或二进制数字串(一串二进制数字)。
Python中的字符串是一种非常重要且灵活的数据类型,它用于表示文本信息,并且在Python编程中被广泛使用。字符串在Python中被视为不可变的序列,这意味着一旦创建了字符串,就不能再对其进行修改。
字符串的基本特性
-
不可变性: 字符串一旦创建,就不能被修改。可以创建新的字符串来实现修改的效果。
-
序列性: 字符串是一个由字符组成的序列,可以通过索引和切片来访问字符串中的字符或子串。
-
Unicode支持:
Python的字符串是Unicode字符串,支持多种语言的字符集,因此可以处理各种语言的文本。
字符串的编码
字符串的编码是将字符转换为字节序列的过程,Python 中常用的编码方式包括 ASCII、UTF-8、UTF-16 等。在 Python 中,字符串默认使用 Unicode 编码。
-
ASCII编码: 最早的字符编码方式,只能表示英文字母、数字和一些特殊字符,使用7位字节表示一个字符。 -
UTF-8编码:Unicode的一种实现方式,是一种变长编码,能够表示全球范围内的字符集,并且节省存储空间。 -
UTF-16编码:Unicode的另一种实现方式,使用16位字节表示一个字符,适用于需要大量使用非ASCII字符的情况。
在Python中,你可以使用encode()方法将字符串编码为字节序列,使用decode()方法将字节序列解码为字符串。
基本操作
构造字符串
在Python中,以引号包围的内容均可认为是字符串:
>>> s = "jfdlasjlfewoi23u8ro23uokl"
>>> s1 = 'r32oodsalhf8oweohesalhfla'
>>> s2 = '''abcdefg
hijklmn
'''
索引和切片
索引
可以把索引理解成每个字符在字符串中的位置,只是从前面索引时,索引值是从0开始,比如a在字符串abcdefgh中的索引值为0, 从后面索引时,索引值从-1开始,索引的操作符为[]。
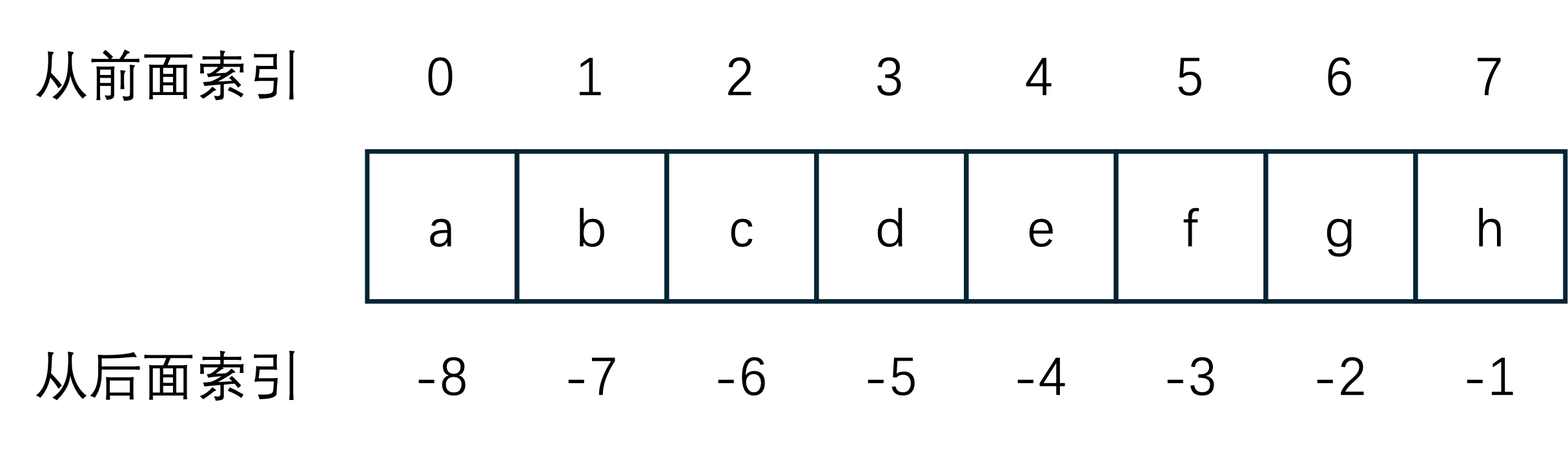
>>> s = 'abcdefgh'
>>> s[0]
'a'
切片
在Python中,切片(slice)是一种从序列(如列表、元组、字符串等)中获取子序列的方法。切片允许你通过指定起始索引、终止索引和步长来选择序列中的一部分元素,并将它们返回为一个新的序列。
切片的语法为
sequence[start:stop:step]
在执行切片时,Python遵循的是数学里区间的左闭右开原则,即[start, stop), 也就是说stop索引位置的元素是取不到的。
start为切片的起始索引,即从哪个索引开始切片;stop为切片的终止索引,但是切不到这个索引位置,只到它之前结束;step为步长,即切片时间隔多少个元素,默认为1。
正向切片时,stop的值要大于start的值,并且步长step要必须为正数,否则切片结果为一个空列表[]。
>>> s = "abcdefghijklmn"
>>> s[1:4]
'bcd'
>>> s[0:9:2]
'acegi'
反向切片时,stop的值要小于start的值,并且步长step要必须为负数,否则切片结果为一个空列表[]。
>>> s = "abcdefghijklmn"
>>> s[-3:-9:-1]
'lkjihg'
start和stop也可以省略不写。
>>> s = "abcdefghijklmn"
>>> s[:8:]
'abcdefg'
>>> s[8:]
'hijklmn'
>>> s[::-1]
'nmlkjihgfedcba'
成员运算
成员运算就是要判断某一个元素是否存在于一个数据结构中, 所用到的运算符为in和not in;成员运算返回的结果为bool型的数据,即True和False:
>>> s = "hello, world"
>>> 'h' in s
True
>>> 'Hello' in s
False
>>> 'a' not in s
True
由于成员运算返回的结果为bool数据,所以可以用在条件语句和循环语句中:
if __name__ == '__main__':
s = "abcdefg"
if 'a' in s:
print(s)
或:
if __name__ == '__main__':
s = 'abcdefg'
sub = input("Please input a sub string:")
while sub in s:
sub = input("Please input a sub string:")
s = s + sub
删除字符串
Python中只能完全删除字符串。
>>> del s
>>> print(s)
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
print(s)
NameError: name 's' is not defined
格式化
%格式化,使用%运算符和格式化字符来格式化字符串。
>>> name = "Alice"
>>>> age = 30
>>> result = "My name is %s and I am %d years old." % (name, age)
My name is Alice and I am 30 years old.
str.format(),是用来格式化字符串里的内容的方法。
>>> "My name is {}, I am {}.".format("Chris",36)
'My name is Chris, I am 36.'
>>> "I have {0} pens, all are {1}".format(10, "black")
'I have 10 pens, all are black'
>>> "I have {1} pens, all are {0}".format(10, "black")
'I have black pens, all are 10'
>>> "I am living in {city}, but I was born in {addr}".format("Shanghai", "Jiangsu")
Traceback (most recent call last):
File "<pyshell#50>", line 1, in <module>
"I am living in {city}, but I was born in {addr}".format("Shanghai", "Jiangsu")
KeyError: 'city'
>>> "I am living in {city}, but I was born in {addr}".format(city="Shanghai", addr="Jiangsu")
'I am living in Shanghai, but I was born in Jiangsu'
f-string, 使用f-string来格式化字符串。
>>> name = "Charlie"
>>> age = 20
>>> result = f"My name is {name} and I am {age} years old."
My name is Charlie and I am 20 years old.
遍历字符串
用for循环可以对那些可迭代的对象进行遍历,主要有两种方式:
索引遍历
s = "abcdefg"
for j in range(len(s)):
print(s[j])
for i in s:
print(i)
这种方式通过索引来访问字符串中的元素。j 在每次循环中都被赋值为字符串的下一个索引,然后使用这个索引来从字符串中获取元素。
直接遍历
s = "ABCDEFG"
for i in s:
print(i)
这种方式直接遍历字符串中的每一个元素。i 在每次循环中都会被赋值为字符串 s 的下一个元素。这种方式效率比索引遍历要高。
函数
在学习函数之前,首先要对函数有一个初步的认识。首先要知道的是Python中函数都是独立的代码块,可以重复调用,用来执行特定的任务或实现特定的功能。我们可以将函数比作一口做饭的大锅cooker,它可以用来炖母鸡hen,需要通过函数名和参数列表来调用:
>>> cooker(hen)
"Chicken Soup"
以下为列表中的三个函数为字符串中经常会使用的函数。
| 名字 | 说明 |
|---|---|
len | 有返回值,返回字符串的长度 |
min | 有返回值,返回字符串中最小的字符 |
max | 有返回值,返回字符串中最大的字符 |
len(string)
len返回字符串string的长度,即元素的个数。
>>> len("abcdefg")
7
max(string)/min(string)
max和min分别返回string的中最大和最小的元素,元素的大小以字符在字符集中的位置来判定。
>>> max("ABCDEFG")
'G'
>>> min("abCDEFG")
'C'
方法
在Python中,方法是要关联在对象中的,需要在一个类的内部定义,去操作对象的属性或者执行对象的特定的功能,所谓的对象可以理解成一个实际的事物,如一只母鸡(母鸡属于鸡这一类)。在这一例子中,母鸡有很多的方法,比如下蛋。
在调用方法时,需要通过对象名和方法名进行,并要传入方法的参数:
>>> hen = Chicken()
>>> hen.dropegg(2)
'The hen dropped 2 eggs.'
对于Python中所有的内置数据类型,我们在创建时,它们都自动被标识成它所属类型的实例对象:
1是int整型类型的实例对象'hello'是str字符串类型的实例对象[1,2,3]是list列表类型的实例对象- ......
将这些实际的值赋值给一个变量之后,上述说法也成立。所以我们不需要通过hen = Chicken()这样的方式创建这些类型。这个内容将会在学习面向对象时详细介绍。
在调用这些实例的方法时,可以直接通过值来调用,也可以在赋值给变量后,通过变量来调用:
>>> "hello".upper()
'HELLO'
>>> s = "WORLD"
>>> s.lower()
'world'
下面我们将对字符串中常用的方法进行学习。
查找与替换
| 方法 | 说明 |
|---|---|
count | 统计子串在字符串中出现的次数 |
find、index | 查找子串在字符串中的位置 |
replace | 替换字符串中的子串 |
count(sub[, start[, end]])
count函数可以查找在[start:end]切片之间,子串sub出现的次数,如果未指定范围则在整个字符串范围内查找。
>>> s = "My name is Chris, I am 6 years old, I will go to Primary School this September."
>>> s.count('I')
2
find(sub[, start[, end]]) / index(sub[, start[, end]])
find返回子字符串sub在[start:end]切片内被找到的最小索引。 如果sub未被找到则返回-1。index返回子字符串sub在[start:end]切片内被找到的最小索引。 如果sub未被找到则会报错ValueError。
>>> s = "to be or not to be, that is a question."
>>> s.find("to")
0
>>> s.index("to", 3, 20)
13
>>> s.find("I")
-1
>>> s.index("I")
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
s.index("I")
ValueError: substring not found
replace(old, new[, count])
replace返回字符串的副本,其中出现的所有子字符串old都将被替换为new。 如果给出了可选参数count,则只替换前count次出现;并不会改变原来的字符串。
>>> s = "My name is Chris."
>>> s.replace("Chris", "Eris")
'My name is Eris.'
>>> print(s)
'My name is Chris.'
分割和连接
| 方法 | 说明 |
|---|---|
split | 将字符串分割成子串列表 |
join | 连接字符串列表成为一个字符串 |
split(sep)
split使用sep作为分隔字符串,返回一个由字符串内单词组成的列表。
>>> '1,2,3'.split(',')
['1', '2', '3']
>>> '1,2,3'.split(',', maxsplit=1)
['1', '2,3']
>>> '1,2,,3,'.split(',')
['1', '2', '', '3', '']
>>> '1<>2<>3'.split('<>')
['1', '2', '3']
join(iterable)
join返回一个由iterable中的字符串拼接而成的字符串,iterable可以为任何高级数据类型,如列表、元组等。
>>> '-'.join(['a', 'b', 'c'])
'a-b-c'
>>> ','.join("abcdefg")
'a,b,c,d,e,f,g'
大小写转换
| 方法 | 说明 |
|---|---|
lower | 将字符串中的字符全部转换成小写 |
upper | 将字符串中的字符全部转换成大写 |
>>> s = 'hello world'
>>> print(s.upper())
'HELLO WORLD'
>>> print(s.lower())
'hello world'
去除左右的子串
| 方法 | 说明 |
|---|---|
strip | 去除字符串两端的子串 |
lstrip、rstrip | 去除字符串左侧或右侧的子串 |
strip(chars)
strip将去除字符串中左右两端的所有的子串,这个子串为所有由chars中指定字符的组合,并返回去除后字符串的副本。如果未指定sub,则默认去除左右两端的空格;不会改变原来的字符串值。
>>> " good ".strip()
'good'
>>> website = 'www.google.com'
>>> website.strip('cowm.')
'google'
>>> print(website)
www.google.com
>>> comment_string = '#....... Section 3.2.1 Issue #32 .......'
>>> comment_string.strip('.#! ')
'Section 3.2.1 Issue #32'
其他常用方法
| 方法 | 说明 |
|---|---|
startswith | 判断字符串是否以指定前缀开始 |
endswith | 判断字符串是否以指定后缀结束 |
isalpha | 判断字符串是否只包含字母 |
isdigit | 判断字符串是否只包含数字 |
isalnum | 判断字符串是否只包含字母或数字 |
isspace | 判断字符串是否只包含空白字符 |
>>> s = 'hello world'
>>> print(s.startswith('hello')) # 输出: True
>>> print(s.endswith('world')) # 输出: True
>>> print(s.isalpha()) # 输出: False
>>> print(s.isdigit()) # 输出: False
>>> print(s.isalnum()) # 输出: False
>>> print(s.isspace()) # 输出: False
列表 List
Python中的列表List是一种非常重要和常用的数据结构,它允许我们存储和操作多个元素。在Python中,列表是一种有序的序列,可以包含任意数量的元素,并且可以动态地改变大小。列表是Python中最灵活、最常用的数据类型之一,几乎在每个Python程序中都会被广泛应用。
基本操作
创建列表
在Python中,可以通过简单的方括号[]来创建一个列表,并在其中放入多个元素,元素之间用逗号,分隔。例如:
>>> my_list = [1, 2, 3, 4, 5]
上述代码创建了一个名为my_list的列表,其中包含了整数1到5。列表中的元素可以是任意类型的对象,也可以是不同类型的对象的组合,甚至可以是另一个列表。例如:
>>> mixed_list = [1, 'apple', True, [5, 6, 7]]
这个列表中包含了一个整数、一个字符串、一个布尔值和一个内嵌列表。Python的列表是可以嵌套的,也就是说一个列表可以包含另一个列表作为其元素。
索引
与字符串一样,列表也可以从正反两个方向来索引
比如:
lst = ['red', 'green', 'blue', 'yellow', 'white', 'black']
正向索引:
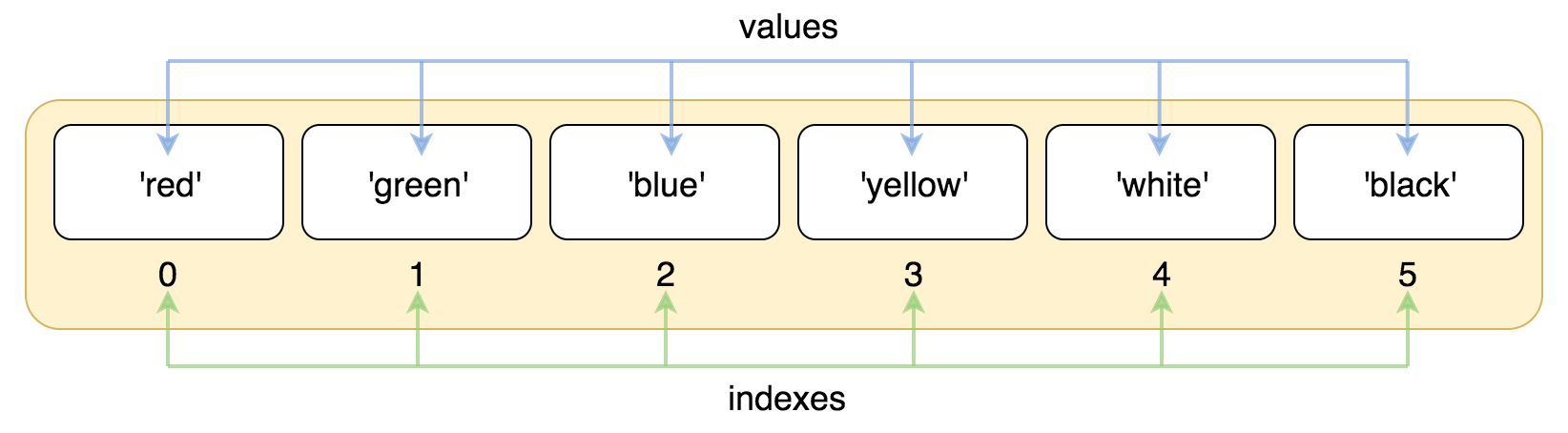
反向索引:
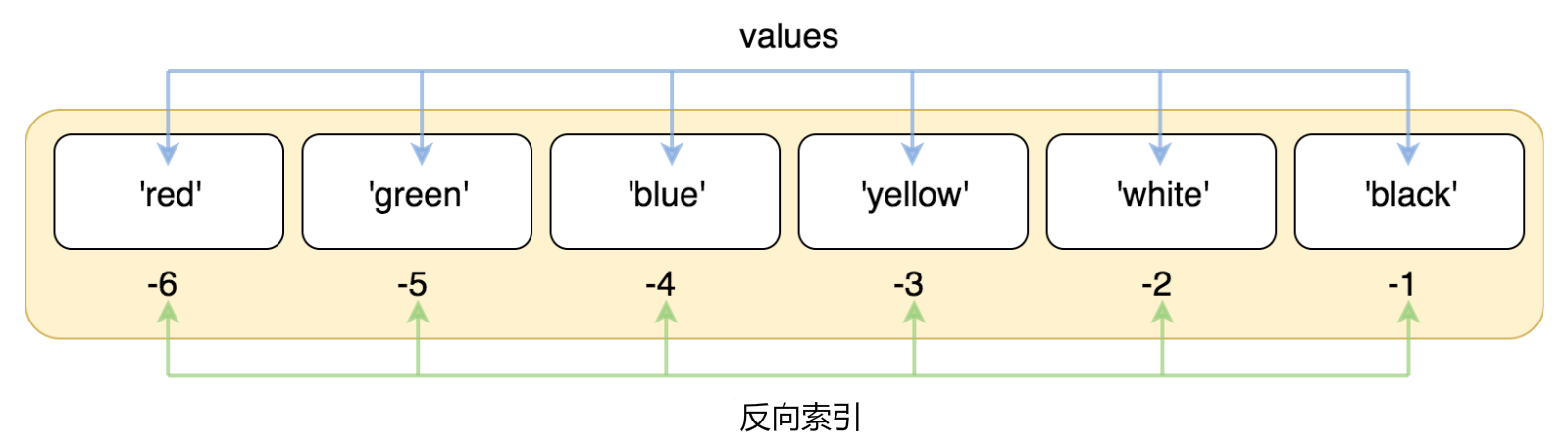
>>> print(lst[0])
red
>>> print(lst[-2])
white
同样列表也不能越界访问其中的元素:
>>> print(lst[10])
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
print(lst[10])
IndexError: list index out of range
切片
与字符串一样,列表也可以进行切片,所用的运算符也是[], 它的语法与字符串类似:
list_name[start:stop:step]
```python
>>> numlst = [1,2,3,4,5,6,7,8,9,10]
>>> numlst[1:4]
[2,3,4]
>>> numlst[6:] #切片从索引6开始,切到最后
[7,8,9,10]
>>> numlst[::2]
[1,3,5,7,9]
列表的切片结果还是列表
通常情况下,切片时,stop的值要大于start的值,否则切片结果为一个空列表[]。
但也有例外,如果设置了步长step为负数,那么stop的值一定要小于start的值,如:
>>> numlst[5:2:-1]
[6, 5, 4]
成员运算
成员运算可以用在Python中所有的数据结构中,语法一致:
>>> lst = [1, 2, 3, 4, 5]
>>> 1 not in lst
False
修改列表
可以通过索引和切片来修改列表的元素值:
>>> numlst = [1,2,3,4,5,6,7,8,9,10]
>>> numlst[0] = 100
>>> print(numlst)
[100,2,3,4,5,6,7,8,9,10]
>>> numlst[1:4] = ['a','b']
>>> print(numlst)
[100,'a','b',5,6,7,8,9,10]
这里提到的修改只是修改这个列表里的内容,不会改变列表的对象。
删除列表里的值
与字符串不同的是,我们可以调用del关键字来删除列表里的元素,或者一段切片。
>>> numlst = [1,2,3,4,5,6,7,8,9,10]
>>> del numlst[0]
>>> print(numlst)
[2,3,4,5,6,7,8,9,10]
>>> del numlst[1:4]
>>> print(numlst)
[1,5,6,7,8,9,10]
>>> del numlst #删除整个列表
列表的加法运算
列表的加法运算只能发生在两个列表之间,不能与其它类型进行加法运算。
>>> lst1 = [1,2,3]
>>> lst2 = [4,5,6]
>>> print(lst1 + lst2)
[1,2,3,4,5,6]
>>> lst3 = lst1 + lst2
列表的乘法运算
列表的加法运算只能发生在列表和整型之间,不能与其它类型进行乘法运算。
>>> lst1 = [1,2,3]
>>> print(lst1 * 2)
[1,2,3,1,2,3]
>>> lst3 = lst1 * 2
遍历列表
用for循环可以对那些可迭代的对象进行遍历,主要有两种方式:
索引遍历
lst = [1,2,3,4,5,6,7,8,9,10]
for j in range(len(lst)):
print(lst[j])
这种方式通过索引来访问列表中的元素。j 在每次循环中都被赋值为列表的下一个索引,然后使用这个索引来从列表中获取元素。这种方式在处理简单元素(如整数或字符串)的列表时,由于需要额外的索引查找,可能会比第一种方式稍慢一些。
直接遍历
lst = [1,2,3,4,5,6,7,8,9,10]
for i in lst:
print(i)
这种方式直接遍历列表中的每一个元素。i 在每次循环中都会被赋值为列表 lst 的下一个元素。这种方式更简洁,并且当列表的元素是复杂对象(如字典或自定义类的实例)时,效率更高。
函数
| 名字 | 说明 |
|---|---|
len | 有返回值,返回列表的长度 |
min | 有返回值,返回列表中最小的字符 |
max | 有返回值,返回列表中最大的字符 |
方法
内容查找
| 方法 | 说明 |
|---|---|
count | 统计在列表中某个元素出现的次数 |
index | 查找在列表中某个元素的位置 |
count(value)
count 返回在列表中有几个value
>>> lst = [2,3,4,65,1,34,5,2,5,7,10]
>>> lst.count(5)
2
index(value, start=0, stop)
列表的index(value,start, stop)方法有三个参数,其中后面两个是可以省略的。
其作用为返回value在整个列表或给定范围内第一次出现的索引,如果不存在则报错。
>>> lst = [1, 2, 3, 4, 5, 'a', 'b', 'c']
>>> lst.index(2)
1
>>> lst.index(2,1,5)
1
>>>
>>>
>>> lst.index(2,2,5)
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
lst.index(2,2,5)
ValueError: 2 is not in list
>>>
>>>
>>> lst.index('a',2,5)
Traceback (most recent call last):
File "<pyshell#7>", line 1, in <module>
lst.index('a',2,5)
ValueError: 'a' is not in list
>>> lst.index(5,2,5)
4
>>>
>>>
>>> lst.index(2,2)
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
lst.index(2,2)
ValueError: 2 is not in list
>>> lst.index(2,1)
1
扩展新的元素
| 方法 | 说明 |
|---|---|
append | 将一个新的元素插入在列表的末尾 |
extend | 将一个可迭代对象中的元素逐个插入到列表的末尾 |
insert | 将一个元素插入到列表的指定位置 |
append(object) 与 extend(iterable)
append,这个方法无返回值,其作用为将object做为一个元素,插入到列表的最后一位。
>>> lst = [1,2,3,4,5]
>>> lst.append('a')
>>> print(lst)
[1,2,3,4,5,'a']
>>> lst.append([7,8,9])
>>> print(lst)
[1,2,3,4,5,'a',[7,8,9]]
extend,这个方法也无返回值,要求输入的参数必须为一个序列,它的作用为将iterable中的所有元素,都单独作为一个元素按顺序插入到列表的后面。
>>> lst = [1,2,3,4,5]
>>> lst.extend('abc')
>>> print(lst)
[1,2,3,4,5,'a','b','c']
>>> lst.extend(1)
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
lst.extend(1)
TypeError: 'int' object is not iterable
insert(index, object)
insert无返回值,它会将值value插入到列表的索引位置index上。
>>> lst.insert(2,6)
>>> lst
[1, 2, 6, 3, 4, 5, 'a', 'b', 'c']
>>> lst.insert(9,7)
>>> lst
[1, 2, 6, 3, 4, 5, 'a', 'b', 'c', 7]
>>> lst.insert(100, 8)
>>> lst
[1, 2, 6, 3, 4, 5, 'a', 'b', 'c', 7, 8]
删除列表的元素
| 方法 | 说明 |
|---|---|
pop | 删除列表中指定索引位置的元素 |
remove | 删除列表中第一次出现值为指定内容的元素 |
clear | 清空整个列表 |
pop(index=-1)
pop(index),如果给定index一个索引值,则移除列表中这个索引下的元素,如未给定则移除最后一个元素,最后将这个被移除的元素返回。
>>> lst.pop()
8
>>> lst
[1, 2, 6, 3, 4, 5, 'a', 'b', 'c', 7]
>>> lst.pop(2)
6
>>> lst
[1, 2, 3, 4, 5, 'a', 'b', 'c', 7]
remove(value)
remove无返回值,其作用为移除掉第一个值为value的元素。
>>> lst = [1,2,3,4,5,2,7]
>>> lst.remove(2)
>>> print(lst)
[1,3,4,5,2,7]
clear()
clear清空列表,将其变成一个空列表[]
>>> lst = [1,2,3,4,5]
>>> lst.clear()
>>> print(lst)
[]
改变元素的排列
| 方法 | 说明 |
|---|---|
sort | 将列表的元素按升序或降序排列 |
reverse | 将列表的元素反序,但是并使列表元素有序 |
sort(reverse=False)
sort对原列表的元素进行排序,将列表生成一个新的有序的列表。 参数reverse被传入的值为True,则倒序排列;否则正序排列。
>>> lst = [5,7,2,3,6,10]
>>> lst.sort()
>>> print(lst)
[2,3,5,6,7,10]
>>> lst = [5,7,2,3,6,10]
>>> lst.sort(reverse=True)
>>> print(lst)
[10,7,6,5,3,2]
reverse()
reverse将列表中元素按索引的位置反序排列。
>>> lst = [5,7,2,3,6,10]
>>> lst.reverse()
>>> print(lst)
[10, 6, 3, 2, 7, 5]
复制列表
| 方法 | 说明 |
|---|---|
copy | 将列表进行浅复制并返回 |
copy()
copy浅复制列表并返回。
>>> lst = [1,2,3,4,5]
>>> new_lst = lst.copy()
>>> print(new_lst)
[1, 2, 3, 4, 5]
在这里简单区分一下Python中的有一种复制方式:
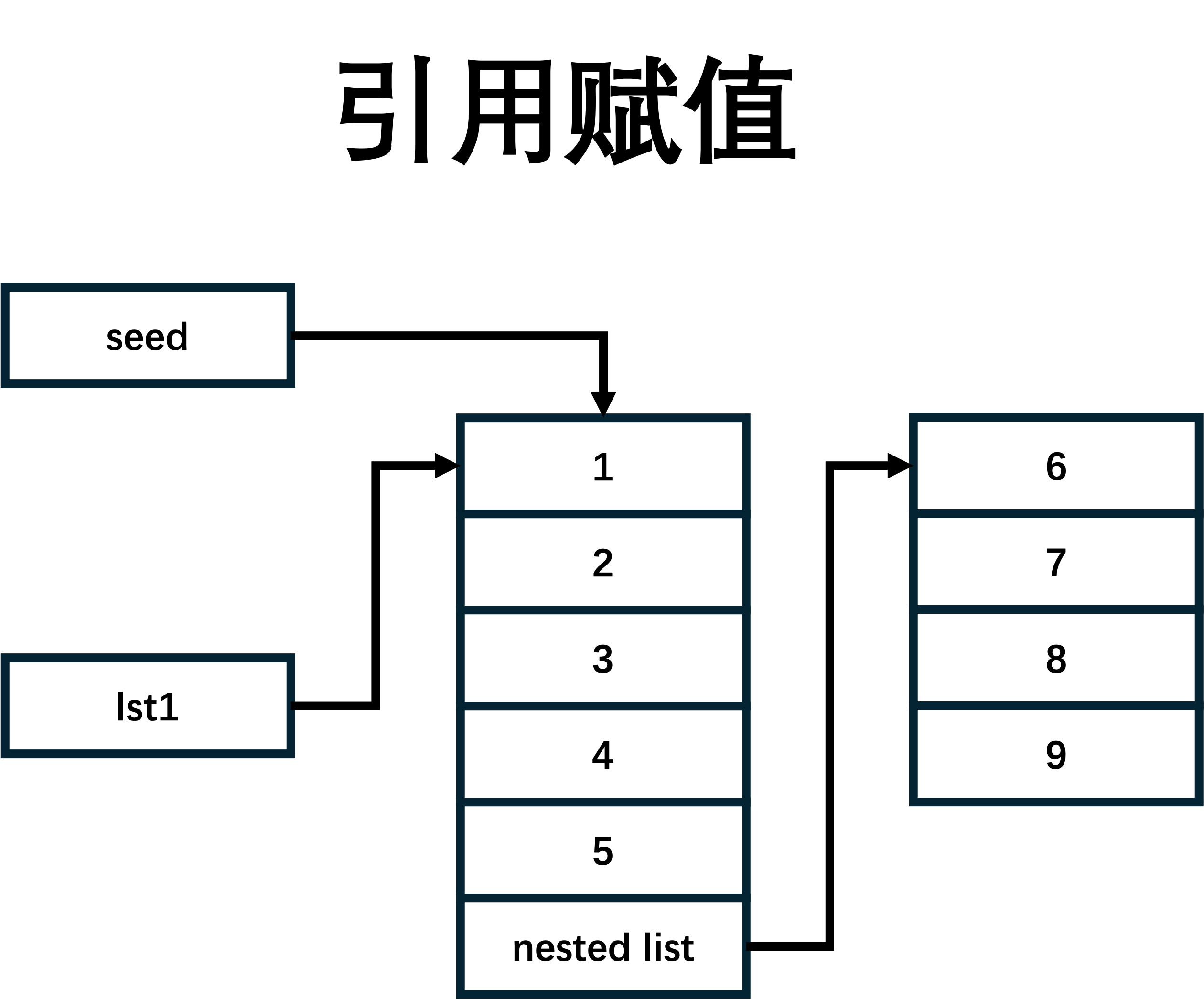
- 引用赋值: 将一个对象的引用赋给另一个变量,不复制对象的任何内容。这也意味着,这两个变量指向同一个对象。
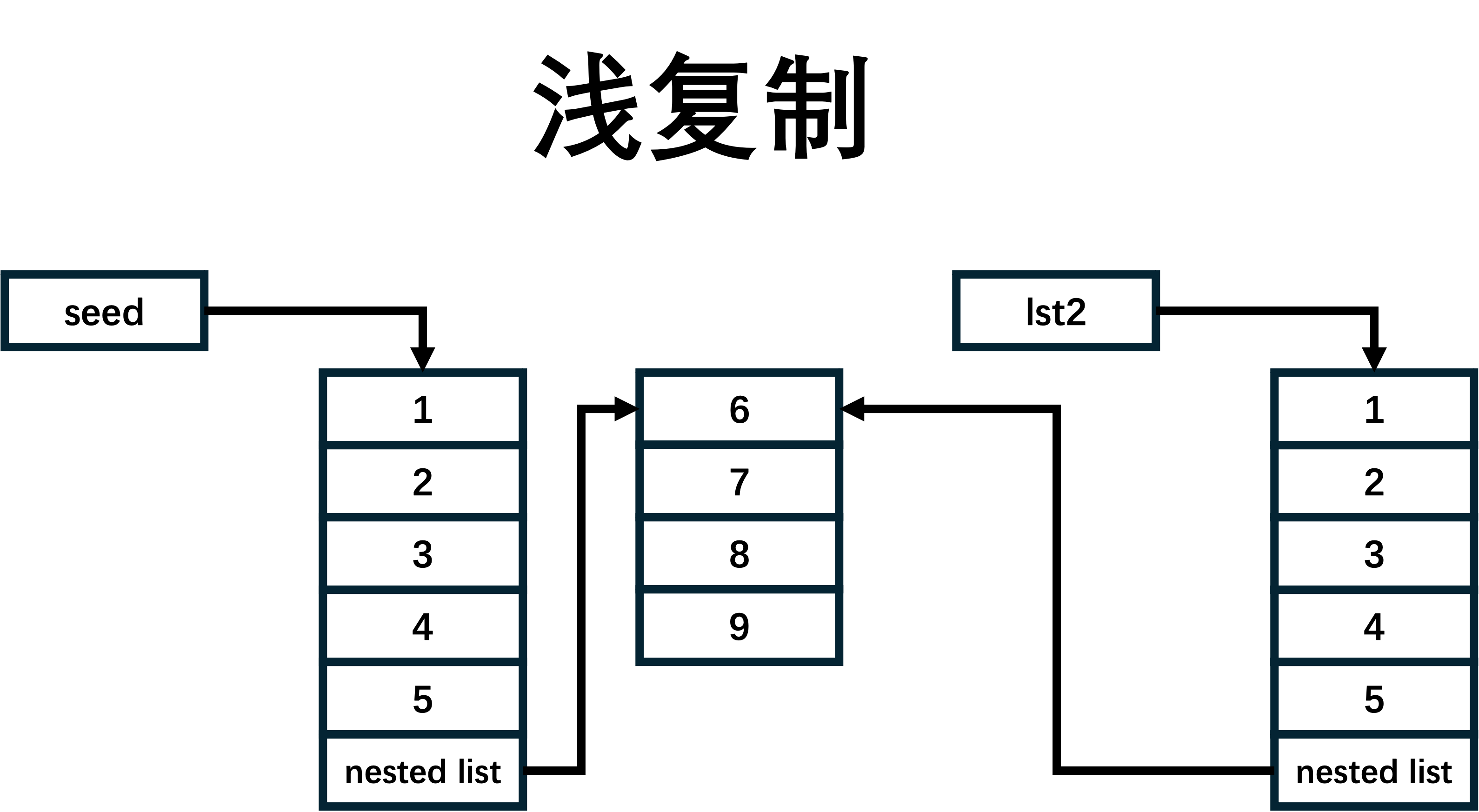
- 浅复制: 创建一个新的对象,并将原始对象中的元素的引用复制到新对象中。如果原始对象中的元素是不可变的,那么浅复制和引用赋值的效果是一样的,因为不可变对象的引用和值是一样的。但如果原始对象中包含可变对象(例如列表中嵌套列表),那么浅复制只会复制最外层的元素的引用,内部元素仍然共享。
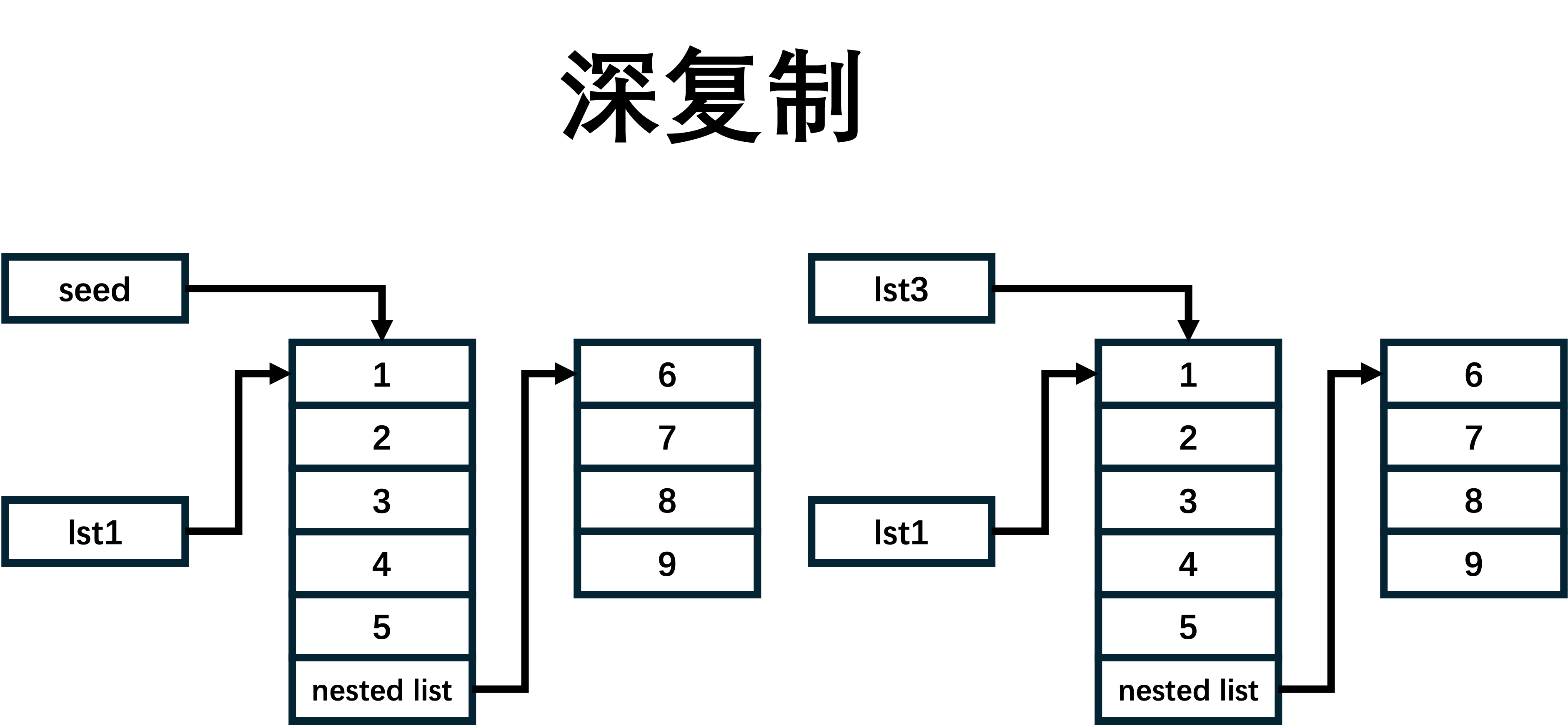
- 深复制: 创建一个全新的对象,同时递归地复制原始对象中的所有元素及其子元素,这样就完全脱离了原始对象。深复制会创建一个独立的对象,不论原始对象中的元素是不可变还是可变,它们都不会共享内存。
根据上面的介绍,我们可以进行如下的测试:
from copy import deepcopy # 导入copy模块中的深复制函数
if __name__ == '__main__':
seed = [1,2,3,4,5,[6,7,8,9]]
lst1 = seed
lst2 = seed.copy()
lst3 = deepcopy(seed)
seed.append(10)
print('lst1:', lst1)
print('lst2:', lst2)
print('lst3:', lst2)
"""
上面print 语句输出的内容为:
list1: [1, 2, 3, 4, 5, [6, 7, 8, 9], 10]
list2: [1, 2, 3, 4, 5, [6, 7, 8, 9]]
list3: [1, 2, 3, 4, 5, [6, 7, 8, 9]]
"""
seed[5].append('a')
print('lst1:', lst1)
print('lst2:', lst2)
print('lst3:', lst2)
"""
上面print 语句输出的内容为:
list1: [1, 2, 3, 4, 5, [6, 7, 8, 9, 'a'], 10]
list2: [1, 2, 3, 4, 5, [6, 7, 8, 9], 10]
list3: [1, 2, 3, 4, 5, [6, 7, 8, 9]]
"""
元组
元组Tuple是Python中的一种有序、不可变的数据类型,用于存储多个元素。与列表类似,元组也可以包含任意数量的元素,但一旦创建后,元组中的元素不能被修改、删除或添加。
基本操作
创建元组
>>> tp = (1,2,3,4,5)
>>> tp1 = (1, 'a', [3,4,5], True)
只有一个元素时,需要在第一个元素后加上一个,。如果不加,,系统会认为创建的不是元组,这个元素是什么类型,就会被认为创建的是什么类型
>>> tp2 = ('A',)
>>> tp3 = ([1,2,3],)
索引和切片
索引和切片的操作与列表和字符串一致。
探讨
元组真的是不可变的吗?我们先看下面的例子:
>>> tp = (1, 'a', [3,4,5], True)
>>> tp[0] = 2
Traceback (most recent call last):
File "<pyshell#14>", line 1, in <module>
tp[0] = 2
TypeError: 'tuple' object does not support item assignment
>>>
>>>
>>> tp[2][0] = 6
>>> print(tp)
(1, 'a', [6, 4, 5], True)
由上可知,元组本身是不能被改变的,但是如果其内部的元素是可变对象时,可以对这个元素进行修改。
集合
集合Set是一个无序且元素唯一的数据结构,可用于存储不重复的元素,并且可以进行交集、并集、差集等常见的集合操作。
集合一旦创建后里面的内容是不能被修改的,所以列表等能被修改的数据结构对象不能作为集合的元素。
基本操作
创建集合
可以使用大括号 {} 创建集合,元素之间用逗号 , 分隔, 或者也可以使用 set() 函数创建集合。
>>> s = {1,2,3,4,5}
>>> print(s)
{1, 2, 3, 4, 5}
>>> st = set()
>>> print(st)
set()
>>>
>>>
>>> {[1,2,3,4]}
Traceback (most recent call last):
File "<pyshell#18>", line 1, in <module>
{[1,2,3,4]}
TypeError: unhashable type: 'list'
对于空集合,在Python中的表示为set(),并不是{}。
添加元素
| 名字 | 说明 |
|---|---|
add | 向集合中添加新的元素 |
update | 更新集合,添加的元素来自其它的other对象 |
add(elem)
add函数用于向集合中添加新的元素,elem必须是不可变的对象。
>>> s = {1,2,3,4,5}
>>> s.add(6)
>>> s.add((1,2,3))
>>> print(s)
{1, 2, 3, 4, 5, 6, (1, 2, 3)}
update(other)
update函数可以更新集合,添加的元素来自其它的other对象。
>>> s = {'A', 'B'}
>>> s.update('abcdefg')
>>> print(s)
{'c', 'a', 'f', 'B', 'A', 'd', 'g', 'e', 'b'}
移除元素
| 名字 | 说明 |
|---|---|
remove | 移除一个元素,如果这个元素不在集合里,则报错 |
discard | 移除一个元素,如果这个元素不在集合里,不会报错 |
pop | 移除任意一个元素,并返回这个元素 |
remove(elem)/discard(elem)
remove要求被移除的元素elem必须在集合中,否则会报错。相反,discard不会报错。
>>> s = {1, 2, 3, 4, 5}
>>> s.remove(1)
>>> print(s)
{2, 3, 4, 5}
>>> s.remove(7)
Traceback (most recent call last):
File "<pyshell#31>", line 1, in <module>
s.remove(7)
KeyError: 7
>>>
>>>
>>> s.discard(2)
>>> print(s)
{3, 4, 5}
>>> s.discard(7)
>>>
pop()
pop随机移除集合中的任意一个元素。
>>> s = {'c', 'a', 'f', 'B', 'A', 'd', 'g', 'e', 'b'}
>>> s.pop()
'c'
>>> print(s)
{'a', 'f', 'B', 'A', 'd', 'g', 'e', 'b'}
集合运算
| 名字 | 说明 |
|---|---|
union | 返回集合与另一个数据结构的并集 |
intersaction | 返回集合与另一个数据结构的交集 |
difference | 返回集合与另一个数据结构的差集 |
union(others)
union返回一个新集合,其中包含来自原集合以及others指定的所有集合中的元素,也就是数学中的并集。 这里在的others必须为一个iterable。
>>> s= {1,2,3,4}
>>> s1 = {4,5,6,7}
>>> s.union(s1)
{1, 2, 3, 4, 5, 6, 7}
>>> s.union(['a', 'b'])
{1, 2, 3, 4, 'a', 'b'}
intersection(others)
intersection返回一个新集合,其中包含原集合以及 others 指定的所有集合中共有的元素,也就是数学中的交集。
>>> s= {1,2,3,4}
>>> s1 = {4,5,6,7}
>>> s.intersection(s1)
{4}
difference(others)
intersection返回一个新集合,其中包含原集合中在 others 指定的其他集合中不存在的元素,也就是数学中的差集。
>>> s= {1,2,3,4}
>>> s1 = {4,5,6,7}
>>> s.difference(s1)
{1, 2, 3}
字典
字典是Python中的一种映射类型Mapping Type,是一种无序的、可变的、可迭代的数据类型。它由一系列键-值对组成,其中每个键都是唯一的。与列表List和元组Tuple等序列类型不同,字典是通过键来访问值的,而不是通过索引。字典的基本特性包括:
- 无序性: 字典中的键-值对是无序的,即插入顺序和遍历顺序不一定相同。
- 可变性: 字典是可变的,可以通过增加、删除和修改键值对来改变字典的内容。
- 动态性: 字典的大小是可变的,可以根据需要动态增加或减少键值对。
基本操作
创建字典
Python中可以使用大括号 {}来创建一个字典,在{}内输入key:value,每个键值对之间用逗号,隔开:
>>> my_dict = {'name': 'Alice', 'age': 30, 'city': 'New York'}
由于字典中键是唯一的,所以在用{}直接创建字典时,如果key重复了,那么它对应的value会被最后一次输入的覆盖:
>>> new_dict = {'name': 'Alice', 'age': 30, 'city': 'New York', 'name': 'Chris', 'name': 'Eris'}
>>> print(new_dict)
{'name': 'Eris', 'age': 30, 'city': 'New York'}
访问字典中的值
可以使用键key来访问字典中的值value:
>>> print(my_dict['name'])
'Alice'
>>> print(my_dict['age'])
30
成员运算
可以使用 in 和 not in 运算符执行成员运算,检查键是否存在于字典中:
# 检查键是否存在
if 'name' in my_dict:
print('Name exists in the dictionary')
更新字典中的值
可以直接对指定的键赋新值来更新字典中的值:
>>> my_dict['name'] = 'Bob'
>>> my_dict['age'] += 1
>>> print(my_dict)
{'name': 'Bob', 'age': 31, 'city': 'New York'}
添加新的键值对
可以通过直接赋值来添加新的键值对:
>>> my_dict['gender'] = 'Male'
>>> print(my_dict)
{'name': 'Bob', 'age': 31, 'city': 'New York', 'gender': 'Male'}
删除指定的键值对
可以使用 del 关键字删除指定的键值对:
>>> del my_dict['age']
>>> print(my_dict)
{'name': 'Bob', 'city': 'New York', 'gender': 'Male'}
函数
| 名字 | 说明 |
|---|---|
len | 有返回值,返回字典的长度,即键值对的个数 |
min | 有返回值,返回字典中最小的字符 |
max | 有返回值,返回字典中最大的字符 |
方法
获取字典中的键、值和键值对
| 名字 | 说明 |
|---|---|
get | 根据键获取其对应的值 |
keys | 返回字典中所有键 |
values | 返回字典中所有值 |
items | 返回字典中所有键键对(key, value) |
get(key[, default])
get方法可以通过传入的参数key来获取在字典中它所对应的值,如果key不存在则返回default的值,若未给出default则默认为None。
>>> my_dict.get('name')
'Bob'
>>> my_dict.get('height', 170)
170
>>> my_dict.get('weight')
>>>
keys()/values()/items()
keys、values和items三个方法没有参数,调用之后分别返回字典中所有的键、值和键值对:
>>> my_dict = {'name': 'Bob', 'city': 'New York', 'gender': 'Male'}
>>> keys = my_dict.keys()
>>> print(keys)
dict_keys(['name', 'city', 'gender'])
>>>
>>>
>>> values = my_dict.values()
>>> print(values)
dict_values(['Bob', 'New York', 'Male'])
>>>
>>>
>>> items = my_dict.items()
>>> print(items)
dict_items([('name', 'Bob'), ('city', 'New York'), ('gender', 'Male')])
通过观察上述三个方法的结束可以发现,它们都是可以迭代的对象,所以可以使用 for 循环遍历字典中的所有键、值和键值对:
# 遍历所有键
for key in my_dict:
print(key)
# 遍历所有值
for value in my_dict.values():
print(value)
# 遍历所有键值对
for key, value in my_dict.items():
print(key, value)
更新与删除
| 名字 | 说明 |
|---|---|
update | 使用其它字典更新当前字典 |
pop | 根据键删除字典中的键值对 |
popitem | 根据值删除字典中的键值对 |
update(other)
调用update之后,Python用使用other中的健值对更新当前字典。如果在other中有当前字典中不存在的key,则直接将这个健值对添加到当前字典中,否则用other中的值更新当前字典中键所对应的值。
>>> new_dict = {'name': 'Jacky', 'height': 170, 'weight': 55}
>>> my_dict.update(new_dict)
>>> print(my_dict)
{'name': 'Jacky', 'city': 'New York', 'gender': 'Male', 'height': 170, 'weight': 55}
pop(key[, default])
调用pop后,如果key存在于字典中则将其移除并返回其值,否则返回default。 如果default未给出且key不存在于字典中,则会报错:
>>> my_dict.pop('height')
170
>>> my_dict.pop('grade', 6)
6
>>> my_dict.pop('Address')
Traceback (most recent call last):
File "<pyshell#57>", line 1, in <module>
my_dict.pop('Address')
KeyError: 'Address'
>>>
>>>
>>> print(my_dict)
{'name': 'Jacky', 'city': 'New York', 'gender': 'Male', 'weight': 55}
popitem()
popitem会以后进先出的方式将字典中的键值对弹出并返回:
>>> my_dict.popitem()
('weight', 55)
>>> print(my_dict)
{'name': 'Jacky', 'city': 'New York', 'gender': 'Male'}
复制与清空
| 名字 | 说明 |
|---|---|
copy | 复制并返回字典浅复制的副本 |
clear | 清空字典中所有的键值对 |
copy()
可以使用 copy 方法或者使用字典的构造函数来复制字典:
>>> new_dict = my_dict.copy()
>>> print(new_dict)
{'name': 'Bob', 'city': 'New York', 'gender': 'Male'}
clear()
clear()方法可以清空字典中的所有键值对,将它变成一个空字典:
>>> my_dict.clear()
>>> print(my_dict)
{}
推导式与函数
我们在前面五个章节中对Python中的内置数据结构做了详细的介绍,其中包括最基本的操作、函数和内置方法的调用。这些数据结构都有很强大的功能,用以解决相对较复杂的问题。
除了直接创建各种数据类型之外,Python也提供推导式和函数高效地生成高级数据类型。
推导式
推导式Comprehension是一种在Python中用于创建新的数据结构(例如列表、集合、字典等)的简洁方法。推导式可以将循环和条件语句结合起来,以一种简洁、可读性高的方式生成新的数据结构。
Python中有三种类型的推导式:列表推导式List Comprehension、集合推导式Set Comprehension和字典推导式Dictionary Comprehension。每种推导式都有其特定的语法形式,但它们的基本思想都是类似的。
通过推导式可以生成元素个数较多的数据结构对象。
列表推导式(List Comprehension)
列表推导式是用于生成列表的推导式,其语法形式为:
[expression for item in iterable if condition]
其中:
expression:对每个item计算得到的结果。item:可迭代对象中的每个元素。iterable:可迭代对象,如列表、元组、字符串等。condition(可选):对item的筛选条件。
例如,生成一个由 1 到 10 的平方组成的列表:
>>> squares = [x**2 for x in range(1, 11)]
>>> print(squares)
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
集合推导式(Set Comprehension)
集合推导式用于生成集合,其语法形式为:
{expression for item in iterable if condition}
其中的语法和列表推导式类似,只是使用了大括号 {}。
例如,生成一个由 1 到 10 的平方组成的集合:
>>> squares_set = {x**2 for x in range(1, 11)}
>>> print(squares_set)
{1, 4, 9, 16, 25, 36, 49, 64, 81, 100}
字典推导式(Dictionary Comprehension)
字典推导式用于生成字典,其语法形式为:
{key_expression: value_expression for item in iterable if condition}
其中:
key_expression:对每个item计算得到的键。value_expression:对每个item计算得到的值。
例如,生成一个将名字转换为对应长度的字典:
>>> names = ["Alice", "Bob", "Charlie"]
>>> name_lengths = {name: len(name) for name in names}
>>> print(name_lengths)
{'Alice':5, 'Bob':3, 'Charlie':7}
推导式是 Python 中的一个非常强大和常用的特性,能够以简洁、高效的方式生成新的数据结构,提高了代码的可读性和可维护性。
函数
Python提供丰富的内置函数将传入的参数转换并返回各种高级数据类型, 这里我们用到的词语是“转换”而不是”生成”是因为在Python中有生成器对象(Generator),所以为了避免在未来的学习过程中产生歧义,我们在这里只用“转换”一词:
| 函数名 | 说明 |
|---|---|
str | 将参数转换成字符串并返回 |
list | 将参数转换成列表并返回 |
tuple | 将参数转换成元组并返回 |
set | 将参数转换成集合并返回 |
dict | 将参数转换成字典并返回 |
str(object)
将object转换成字符串文本并返回, 如果没有传参数则返回空字符串""。
这个函数我们并不陌生,在常用内置函数一章中就已经学习过了,它的功能很简单,就是将传入的参数转换成字符串,如:
>>> str(1)
'1'
上面例子中,我们传入的参数只是基本的整型,但是对于更复杂的高级数据类型,它的作用不是将其中的元素进行拼接再转换成字条串,而是在将其所表现的基础上直接加上引号,如str([1,2,3])的结果不是'123', 而是'[1,2,3]'
>>> str([1, 2, 3])
'[1, 2, 3]'
对于str函数的学习还没完结,我们会在后面继续介绍。
list(iterable)
返回将iterable转换之后生成的列表, 如果没有传参数则返回空列表[]。
>>> list("abcdefg")
['a','b','c','d','e','f','g']
>>> list(1)
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
list(1)
TypeError: 'int' object is not iterable
>>> list()
[]
>>> list({1:2,3:4,5:6})
[1, 3, 5]
tuple(iterable)
返回将iterable转换之后生成的元组,如果没有传参数则返回空元组()。
>>> tuple([1,2,3,4,5,6,7])
(1, 2, 3, 4, 5, 6, 7)
>>> tuple("abcdefg")
('a', 'b', 'c', 'd', 'e', 'f', 'g')
>>> tuple()
()
set(iterable)
返回将iterable转换之后生成的集合,如果没有传参数则返回空集合set()。
>>> set([1,2,3,4,5,5,6,1,4])
{1, 2, 3, 4, 5, 6}
>>> set()
set()
dict(**kwargs)
返回一个字典,字典内每个键值对由关键字参数中一对参数名=值组成,无参数则返回一个空字典{}。
>>> dict(one=1, two=2, three=3, F=1111)
{'one': 1, 'two': 2, 'three': 3, 'F': 1111}
内置函数
数学运算
| 函数 | 功能 |
|---|---|
abs(x) | 求x的绝对值 |
divmod(x, y) | 求两个数的整除和求余结果(x//y, x%y) |
| round(a, b) | 对a进行四舍五入操作,进位到b |
| pow(x, y) | 求x的y次幂的结果 |
| sum(x, start=b) | 对x中所有元素求和, x必须是可迭代的,如列表 |
| min/max | 求最小/最大值 |
>>> abs(-4)
4
>>> divmod(10, 3)
(3, 1)
>>> divmod(-10, 3)
(-4, 2)
>>> round(3.1415926,3)
3.142
>>> round(3.1415926) # round(3.1415926, 0)
3
>>> round(12306.78, 1)
12310
>>> pow(2, 4)
16
>>> sum([1,2,3,4])
10
>>> sum([1,2,3,4],start=10)
20
>>> min(1,2,3,4,5)
1
>>> max([3,4,5])
5
进制转换
| 函数 | 功能 |
|---|---|
bin(x) | 将x转换成二进制 |
oct(x) | 将x转换成八进制 |
hex(x) | 将x转换成十六进制 |
int(x,base) | 将x转换成十进制 |
>>> bin(432)
'0b110110000'
>>> oct(432)
'0o660'
>>> hex(432)
'0x1b0'
>>> int('32baf', 16)
207791
>>> int('32bag', 17)
263754
类型转换
| 函数 | 功能 |
|---|---|
bool(x) | 将x转换成布尔型,如果x为真值,则返回True |
str(x) | 将x转换成字符串,可以直接理解为在x左右两边加"或' |
list(iterable) | 将iterable转换成列表 |
tuple(iterable) | 将iterable转换成元组 |
set(iterable) | 将iterable转换成集合 |
dict(**kwargs) | 返回一个字典,字典中的键值对中kwargs里的参数名=值组成 |
假值:0, '', None, 0.000, [], (,), {}, set()
>>> bool(-1)
True
>>> str([1,2,3,4,5])
'[1, 2, 3, 4, 5]'
>>> list("abcde")
['a', 'b', 'c', 'd', 'e']
>>> tuple("abcde")
('a', 'b', 'c', 'd', 'e')
>>> set("aabbccddee")
{'a', 'b', 'c', 'd', 'e'}
>>> dict(one=1, two=2, three=3)
{'one': 1, 'two': 2, 'three': 3}
字符与码位的转换
| 函数 | 功能 |
|---|---|
ord(x) | 返回x在字符集中的位置, x必须为字符 |
chr(x) | 返回字符集中第x位上的字符,x必须为整型 |
>>> ord('陈')
38472
>>> chr(38471)
'陇'
检查空值
| 函数 | 功能 |
|---|---|
all(iterable) | 如果iterable中所有元素都是真值或为空,返回True,否则返回False |
any(iterable) | 如果iterable中任一元素为真值返回True,否则返回False |
def all(iterable):
for element in iterable:
if not element:
return False
return True
def any(iterable):
for element in iterable:
if element:
return True
return False
>>> all([])
True
>>> any([])
False
>>> all([1,2,3,4])
True
>>> all([0,1,2,3])
False
批量处理迭代对象
| 函数 | 功能 |
|---|---|
filter(func, iterable) | 将iterable中所有元素作为参数传值给func函数,如果结果为False,则这个元素会被忽略,没有给Func函数传值时默认调用bool() |
map(func, iterable) | 将iterable中所有元素作为参数传值给func函数,将这些新的值放在一个新的可迭代对象里 |
>>> lst = [0, 1, 2, 3, 4]
>>> f = filter(None, lst)
>>> print(f)
<filter object at 0x00000255BAAF4E20>
>>> list(f)
[1, 2, 3, 4]
>>> m = map(str, lst)
>>> print(m)
<map object at 0x00000255BAAF4EE0>
>>> list(m)
['0', '1', '2', '3', '4']
枚举迭代对象
enumerate(iterable) 枚举iterable中的元素的索引和值,并放在一个新的迭代器中
my_dict = {'A': 1, 'B': 2}
for i in enumerate(my_dict):
print(i)
"""
(0, 'A')
(1, 'B')
"""
lst = ['a', 'b']
for i in enumerate(lst):
print(i)
"""
(0, 'a')
(1, 'b')
"""
执行语句
| 函数 | 功能 |
|---|---|
eval() | 执行一个表达式,并返回表达式的结果 |
exec() | 执行段语句,没有返回值 |
>>> a = 5
>>> eval("a+6")
11
>>> eval("'a'*10")
'aaaaaaaaaa'
cycle = """
import turtle as t
t.circle(100)
"""
exec(cycle)
对象类型
| 函数 | 功能 |
|---|---|
type(obj) | 返回obj的类名 |
isinstance(obj, type) | 查验obj是不是type类型 |
>>> type(1)
<class 'int'>
a = input("input a number:")
if type(a) == int:
print('Yes')
>>> isinstance(1, int)
True
内置函数
数学运算
| 函数 | 功能 |
|---|---|
abs(x) | 求x的绝对值 |
divmod(x, y) | 求两个数的整除和求余结果(x//y, x%y) |
| round(a, b) | 对a进行四舍五入操作,进位到b |
| pow(x, y) | 求x的y次幂的结果 |
| sum(x, start=b) | 对x中所有元素求和, x必须是可迭代的,如列表 |
| min/max | 求最小/最大值 |
>>> abs(-4)
4
>>> divmod(10, 3)
(3, 1)
>>> divmod(-10, 3)
(-4, 2)
>>> round(3.1415926,3)
3.142
>>> round(3.1415926) # round(3.1415926, 0)
3
>>> round(12306.78, 1)
12310
>>> pow(2, 4)
16
>>> sum([1,2,3,4])
10
>>> sum([1,2,3,4],start=10)
20
>>> min(1,2,3,4,5)
1
>>> max([3,4,5])
5
进制转换
| 函数 | 功能 |
|---|---|
bin(x) | 将x转换成二进制 |
oct(x) | 将x转换成八进制 |
hex(x) | 将x转换成十六进制 |
int(x,base) | 将x转换成十进制 |
>>> bin(432)
'0b110110000'
>>> oct(432)
'0o660'
>>> hex(432)
'0x1b0'
>>> int('32baf', 16)
207791
>>> int('32bag', 17)
263754
类型转换
| 函数 | 功能 |
|---|---|
bool(x) | 将x转换成布尔型,如果x为真值,则返回True |
str(x) | 将x转换成字符串,可以直接理解为在x左右两边加"或' |
list(iterable) | 将iterable转换成列表 |
tuple(iterable) | 将iterable转换成元组 |
set(iterable) | 将iterable转换成集合 |
dict(**kwargs) | 返回一个字典,字典中的键值对中kwargs里的参数名=值组成 |
假值:0, '', None, 0.000, [], (,), {}, set()
>>> bool(-1)
True
>>> str([1,2,3,4,5])
'[1, 2, 3, 4, 5]'
>>> list("abcde")
['a', 'b', 'c', 'd', 'e']
>>> tuple("abcde")
('a', 'b', 'c', 'd', 'e')
>>> set("aabbccddee")
{'a', 'b', 'c', 'd', 'e'}
>>> dict(one=1, two=2, three=3)
{'one': 1, 'two': 2, 'three': 3}
字符与码位的转换
| 函数 | 功能 |
|---|---|
ord(x) | 返回x在字符集中的位置, x必须为字符 |
chr(x) | 返回字符集中第x位上的字符,x必须为整型 |
>>> ord('陈')
38472
>>> chr(38471)
'陇'
检查空值
| 函数 | 功能 |
|---|---|
all(iterable) | 如果iterable中所有元素都是真值或为空,返回True,否则返回False |
any(iterable) | 如果iterable中任一元素为真值返回True,否则返回False |
def all(iterable):
for element in iterable:
if not element:
return False
return True
def any(iterable):
for element in iterable:
if element:
return True
return False
>>> all([])
True
>>> any([])
False
>>> all([1,2,3,4])
True
>>> all([0,1,2,3])
False
批量处理迭代对象
| 函数 | 功能 |
|---|---|
filter(func, iterable) | 将iterable中所有元素作为参数传值给func函数,如果结果为False,则这个元素会被忽略,没有给Func函数传值时默认调用bool() |
map(func, iterable) | 将iterable中所有元素作为参数传值给func函数,将这些新的值放在一个新的可迭代对象里 |
>>> lst = [0, 1, 2, 3, 4]
>>> f = filter(None, lst)
>>> print(f)
<filter object at 0x00000255BAAF4E20>
>>> list(f)
[1, 2, 3, 4]
>>> m = map(str, lst)
>>> print(m)
<map object at 0x00000255BAAF4EE0>
>>> list(m)
['0', '1', '2', '3', '4']
枚举迭代对象
enumerate(iterable) 枚举iterable中的元素的索引和值,并放在一个新的迭代器中
my_dict = {'A': 1, 'B': 2}
for i in enumerate(my_dict):
print(i)
"""
(0, 'A')
(1, 'B')
"""
lst = ['a', 'b']
for i in enumerate(lst):
print(i)
"""
(0, 'a')
(1, 'b')
"""
执行语句
| 函数 | 功能 |
|---|---|
eval() | 执行一个表达式,并返回表达式的结果 |
exec() | 执行段语句,没有返回值 |
>>> a = 5
>>> eval("a+6")
11
>>> eval("'a'*10")
'aaaaaaaaaa'
cycle = """
import turtle as t
t.circle(100)
"""
exec(cycle)
对象类型
| 函数 | 功能 |
|---|---|
type(obj) | 返回obj的类名 |
isinstance(obj, type) | 查验obj是不是type类型 |
>>> type(1)
<class 'int'>
a = input("input a number:")
if type(a) == int:
print('Yes')
>>> isinstance(1, int)
True
文件的操作
假设下列文件存放在D:盘,命名为subject.txt
Chinese
Mathematics
English
Chemistry
Physics
打开文件
函数open("filepath/filename","mode",encoding="utf-8")
"""
以只读模式打开文件,文件存储在windows系统中
"""
f = open("d:\\subject.txt","r",encoding="utf-8")
f.close()
假如,文件存储在Linux或者MacOS系统中,正确的代码为
"""
以只读模式打开文件,文件存储在windows系统中
"""
f = open("/path/subject.txt","r",encoding="utf-8")
f.close()
用with关键字打开,不需要调用close()方法,但是打开之后,操作文件的语句要缩进
with open("d://score2.csv", 'r', encoding="utf-8") as f:
print(f.readlines())
模式
| 模式 | 解释 |
|---|---|
r | 只读文件 |
w | 写入文件 |
a | 追加文件 |
+ | 和上三种配合使用,让打开的文件可读可写 |
只读
read()
- 当不输入参数时,读取文件内所有内容;
- 当输入参数时,如read(10),从第一个字节开始,读取后面10个字符。
f = open("/path/subject.txt","r",encoding="utf-8")
print(f.read())
f.close()
"""
输出结果为:
Chinese
Mathematics
English
Chemistry
Physics
"""
f = open("/path/subject.txt","r",encoding="utf-8")
print(f.read(10))
f.close()
"""
输出结果为:
Chinese
Ma
在Chinese后有一个换行符,也是字符。
"""
readline()
- 当不输入参数时,读取数据直到遇到换行或者
EOF; - 当输入参数时,如readline(10),从第一个字节开始,读取后面10个字符,但是遇到换行或者
EOF立即停止。
f = open("/path/subject.txt","r",encoding="utf-8")
print(f.readline())
f.close()
"""
输出结果为:
Chinese
在Chinese后有一个换行符,并且print以换行结束,所以有一空行。
"""
f = open("/path/subject.txt","r",encoding="utf-8")
print(f.readline(5))
print(f.readline())
f.close()
"""
输出结果为:
Chine
se
"""
readlines()
- 没有参数,以文件每一行为元素(包括换行符),返回一个列表。
f = open("/path/subject.txt","r",encoding="utf-8")
print(f.readlines())
f.close()
"""
输出结果为:
['Chinese\n','Mathematics\n','English\n','Chemistry\n','Physics\n']
"""
写入
要写入文件,需要用w或者a两种模式打开文件。两者的区别为:
w是先清除文件所有内容再写入,清除文件的操作在打开时完成;a是在文件现有内容后追加新的内容,打开文件时,游标被移动到最近。
写入的函数是write()
"""
以写入的模式打开文件
"""
f = open("/path/subject.txt",'w',encoding="utf-8")
f.write("Biology\n")
f.write("History\n")
f.close()
"""
以追加的模式打开文件
"""
f = open("/path/subject.txt",'a',encoding="utf-8")
f.write("Biology\n")
f.write("History\n")
f.close()
可读可写
可读可写模式的实现可以将r、w、a三种模式后加上一个+,即r+、w+、a+,三者区别:
r+:打开文件时,游标在文件开头,但是原本内容还在w+:打开文件时,游标在文件开头,原本内容已经被清除a+:打开文件时,游标在文件最后,且原本内容还在
f = open("/path/subject.txt","r+",encoding="utf-8")
f.write("Geography")
print(f.read())
f.close()
"""
输出结果为:
"""
当写入之后,游标的位置位于刚刚写入内容的后面,所以不能读出刚刚写入的内容。
如果要解决这个问题,需要用到seek(0)函数;
seek(0)函数的功能是,将游标移动到指定位置,0即最起始位置。
所以上述代码只需要多加一行,就能读取出写入之后的文件内所有内容,请自行完成代码。
进制转换
在计算机科学中,数值的表示和处理主要使用四种进制:二进制、八进制、十进制和十六进制,这些不同的进制各自有其独特的优势和应用场景。二进制是计算机内部数据存储和处理的基础;八进制和十六进制由于其与二进制的方便转换关系,常用于简化表示和内存地址表示;十进制则是人类最常用的进制系统,方便与计算机进行数据交换和理解。在理解和掌握这些进制系统的转换规则后,可以更高效地进行计算机相关的编程和操作。
介绍
二进制 (Binary)
基数:2
数字:0, 1
二进制是计算机内部使用的基本数制,因为计算机的底层硬件使用高低电压(通常表示为0和1)来存储和处理数据。二进制数的每一位称为位(bit)。
示例:
- 二进制:1011
- 对应的十进制:\[1 \times 2^3 + 0 \times 2^2 + 1 \times 2^1 + 1 \times 2^0 = 8 + 0 + 2 + 1 = 11\]
八进制 (Octal)
基数:8
数字:0, 1, 2, 3, 4, 5, 6, 7
八进制数常用于简化二进制数的表示。因为3位二进制数正好可以表示一个八进制数,因此八进制数比二进制数更紧凑,容易阅读。
示例:
- 八进制:13
- 对应的二进制:001 011(将每个八进制数字转换为3位二进制)
- 对应的十进制:\[1 \times 8^1 + 3 \times 8^0 = 8 + 3 = 11 \]
十进制 (Decimal)
基数:10
数字:0, 1, 2, 3, 4, 5, 6, 7, 8, 9
十进制是我们日常生活中最常使用的数制,基于10个数字。计算机编程中也经常使用十进制数来表示和输入数据。
示例:
- 十进制:11
- 对应的值:\[1 \times 10^1 + 1 \times 10^0 = 10 + 1 = 11\]
十六进制 (Hexadecimal)
基数:16
数字:0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F
十六进制数常用于计算机科学和数字电子学,因为它比二进制和八进制更紧凑且易于转换。每一个十六进制数字可以表示4位二进制数。
示例:
- 十六进制:B
- 对应的二进制:1011(将每个十六进制数字转换为4位二进制)
- 对应的十进制:\[11 \times 16^0 = 11 \]
进制转换
将十进制转换为二进制的方法
将十进制转换为二进制可以通过一种称为“除2取余法”的方法实现。该方法包括以下步骤:
- 除以2:用十进制数除以2,并记录商和余数。
- 记录余数:将得到的余数作为二进制数的一位(从右到左)。
- 更新商:将商作为新的十进制数,重复步骤1和2,直到商为0。
- 排列余数:将记录的余数逆序排列,即从最后一个余数到第一个余数,得到二进制数。
举例说明:
假设将十进制数42转换为二进制。
| 除数 | 商 | 余数 |
|---|---|---|
| 42 ÷ 2 | 21 | 0 |
| 21 ÷ 2 | 10 | 1 |
| 10 ÷ 2 | 5 | 0 |
| 5 ÷ 2 | 2 | 1 |
| 2 ÷ 2 | 1 | 0 |
| 1 ÷ 2 | 0 | 1 |
将余数逆序排列:101010
因此,十进制数42的二进制表示为101010。
通过以上步骤,可以将任何十进制数转换为二进制数。这种方法直观且易于理解,是学习进制转换的基础。
异常处理
在程序运行过程中,出现一些未能避免的错误,通常这些错误会导致程序不能正常结束,所以异常处理是用来处理这些错误。
比如,我们开发一个计算器程序,从键盘输入数值和运算符来计算结果,但是如果错误输入了字符去运算,那么正常在Python中会报错,从而程序中止运行。那么此时就需要异常处理来保证程序能正常结束:想要计算1/2的结果,在输入/之后,输出了0,那么这时,计算的结果肯定是错误。
语法结构
try:
# 可能会发生异常的语句
except:
# 捕获到异常之后要执行的语句
else:
# 没有异常时要执行的语句
finally:
# 不论有无异常,都要执行的语句
在异常处理中,else和finally不是必须的。一旦写了try,那么一定要有except。
尝试运行下列代码:
a = 5
b = 0
c = a / b
"""
执行上述代码后会有下面错误发生:
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
a/b
ZeroDivisionError: division by zero
"""
如果用异常处理,正确的方式为:
a = 5
b = 0
try:
c = a / b
except:
print("有异常")
假如,我要设计的逻辑是有异常就处理,没有异常则打印c的值,则需要在else的下面填写语句:
a = 5
b = 4
try:
c = a / b
except:
print("有异常")
else:
print("c的值为:",c)
如果不管有没有异常,我都需要提醒一句"程序结束",则需要在finally的下面填写语句:
a = 5
b = 4
try:
c = a / b
except:
print("有异常")
else:
print("c的值为:",c)
finally:
print("程序结束!")
处理不同的异常
在捕获异常的过程中,可能捕获到的异常有很多种,那么不同的异常的处理方式也应该有所不同,因为一旦提示的异常处理方式秒妥当,对程序的运行不会有帮助。
在except语句的后面可以加上要处理的异常的名字,如ValueError、ZeroDivisionError等等。
try:
a = "a"
b = 0
if a+b!=100:
raise Exception("a+b is not 100")
c = a / b
except ValueError:
print("赋值错误!")
except ZeroDivisionError:
print("除数不能为零!")
except:
print("其它异常")
排序算法
常见的排序算法有:冒泡排序,选择排序,插入排序,桶排序,快速排序。
数据准备
import random as r
n = int(input("请输入列表元素的个数:"))
lst = []
for i in range(n):
a = r.randint(-200, 200)
while a in lst:
a = r.randint(-200, 200)
lst.append(a)
冒泡排序
冒泡排序(Bubble Sort)是一种简单直观的排序算法。它重复地走访过要排序的列表,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访列表的工作是重复地进行直到没有再需要交换,也就是说该列表已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到列表的顶端。
- 需要比较的过程需要
len(lst) - 1轮 - 每一轮比较,需要从第一位开始,与当前位置的后面一个元素进行比较,如果排序排序错误,则交换
- 每一轮比较需要到哪一位结束? 假设列表中有7个数据
len(lst) = 7
第一轮 i = 0,比较到第6个元素,即最后遍历的索引 j = len(lst) - 1 - 1
第二轮 i = 1,比较到第5个元素,即最后遍历的索引 j = len(lst) - 1 - 2
第三轮 i = 2,比较到第4个元素,即最后遍历的索引 j = len(lst) - 1 - 3
第四轮 i = 3,比较到第3个元素,即最后遍历的索引 j = len(lst) - 1 - 4
第五轮 i = 4,比较到第2个元素,即最后遍历的索引 j = len(lst) - 1 - 5
第六轮 i = 5,比较到第1个元素,即最后遍历的索引 j = len(lst) - 1 - 6
import random as r
n = int(input("请输入列表元素的个数:"))
lst = []
for i in range(n):
a = r.randint(-200, 200)
while a in lst:
a = r.randint(-200, 200)
lst.append(a)
for i in range(len(lst) - 1):
for j in range(len(lst) - 1 - i):
if lst[j] > lst[j+1]:
lst[j], lst[j+1] = lst[j+1], lst[j]
def bubble_sort(ls, reverse=False):
n = len(ls)
for i in range(n-1):
for j in range(n-1-i):
if reverse:
if ls[j] < ls[j+1]:
ls[j], ls[j+1] = ls[j+1], ls[j]
else:
if ls[j] > ls[j+1]:
ls[j], ls[j+1] = ls[j+1], ls[j]
print(ls)
if __name__ == '__main__':
print(lst)
bubble_sort(lst, True)
print(lst)
"""
请输入列表元素的个数:10
[-125, 92, 6, 23, -147, 161, -20, 121, 127, 148]
[161, 148, 127, 121, 92, 23, 6, -20, -125, -147]
"""
选择排序
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
步骤:
- 首先默认第一个位置的值最小(大);
- 再依次和后面的数进行比较,如果有比当前最小值还要小(大)的数,则重新定义最小值的位置,直到最后一个位置判断结束;
- 将最小值位置上的数和第一个位置上的数交换;
- 依次对后面的位置进行上述操作。
for i in range(len(lst) - 1):
minv = i
for j in range(i+1, len(lst)):
if lst[j] < lst[minv]:
minv = j
if minv != i:
lst[minv], lst[i] = lst[i], lst[minv]
def selection_sort(ls, reverse=False):
n = len(ls)
for i in range(n - 1):
flag = i
for j in range(i + 1, n):
if reverse:
if ls[flag] < ls[j]:
flag = j
else:
if ls[flag] > ls[j]:
flag = j
ls[i], ls[flag] = ls[flag], ls[i]
print(ls)
选择排序有另外一种写法,效率会低于上面一种:
def selection_sort(ls, reverse=False):
n = len(ls)
for i in range(n - 1):
for j in range(i + 1, n):
if reverse:
if ls[i] < ls[j]:
ls[i], ls[j] = ls[j], ls[i]
else:
if ls[i] > ls[j]:
ls[i], ls[j] = ls[j], ls[i]
print(ls)
查找
查找要学习的主要内容有两个:顺序查找和二分法查找。
数据准备
import random as r
n = int(input("请输入列表元素的个数:"))
lst = []
for i in range(n):
a = r.randint(-200, 200)
while a in lst:
a = r.randint(-200, 200)
lst.append(a)
顺序查找
顺序查找也叫线性查找, 是指按一定的顺序检查列表中每一个元素,直到找到所要寻找的特定值为止。 这里需要对列表的值进行循环遍历:
def sequence_search(ls, x):
for i in ls:
if i == x:
return True
return False
if sequence_search(lst, 100):
print("100找到了。")
else:
print("没有在列表里找到100")
二分法查找
二分法查找的主要思想就是将列表进行折半查找,通过不断折半的过程来确定要查找的关键字所在的区域。
- 先将列表进行正序排序;
- 设置起始和末尾结点
start、end,然后得到中间结点mid,mid = (start + end) // 2; - 如果中间结点的值大于要查找的关键字
key,则设置end = mid - 1,反之,如果中间结点的值小于要查找的关键字key,则设置start = mid + 1; - 再次计算
mid = (start + end) // 2; - 重复3和4直到找到关键字或者
start和end相遇。
key =
lst.sort()
start = 0
end = len(lst) - 1
flag = False
while start < end:
mid = (start + end) // 2
if lst[mid] > key:
end = mid - 1
elif lst[mid] < key:
start = mid + 1
else:
flag = True
break
if flag:
print(key)
else:
print('Not found.')
def binary_search(ls, key):
ls.sort()
start = 0
end = len(ls) - 1
mid = (start + end) // 2
while start < end:
if ls[mid] > key:
end = mid - 1
if ls[mid] < key:
start = mid + 1
if ls[mid] == key:
return True
mid = (start + end) // 2
return False
利用二分法查找求平方根
要利用二分法的算法求平方根,需要注意的是一个正数的平方根是一定存在的,假设求一个有两位小数的平方根,大致的步骤如下 :
- 设置起始和末尾节点
start、end,如果这个数key大于1, 则start = 1,end = key; 如果key小于1,则start = key,end = 1; - 计算
mid = (start + end) / 2 - 如果
mid * mid的结果与key的差值的绝对值小于0.0001,则确定mid为key的平方根; - 如果
mid * mid大于key, 则设置end = mid,反之设置start = mid; - 再次计算
mid = (start + end) / 2; - 重复4和5直到找到平方根为止。
key = float(input("请输出一个有两位小数的浮点数:"))
if key > 1:
start = 1
end = key
else:
start = key
end = 1
mid = (start + end) / 2
while abs(mid * mid - key) > 0.0001:
if mid * mid > key:
end = mid
if mid * mid < key:
start = mid
mid = (start + end) / 2
print(round(mid, 2))
内建模块
在 Python 中,模块(Module)是一个包含 Python 代码的文件,它提供了许多有用的函数、类、变量和可执行代码,使得我们能够更高效地进行编程。模块的作用是组织代码,将功能封装起来,便于代码复用和管理。
模块简介
- 定义:模块是一个包含 Python 代码的文件,通常以
.py为文件扩展名。 - 作用:模块使得程序更加简洁、可维护和高效。通过模块,可以将不同的功能组织到不同的文件中,从而使代码更加模块化,避免重复代码,并提高可读性。
- 示例:
math、os、sys、datetime、random等都是 Python 中的标准库模块。
Python提供了大量的内建模块供开发者们使用,每一个模块都能在特定的方向上发挥很大的作用。在初级学习阶段,可以先对下面几个相对简单的模块进行学习。
- math 模块提供了很多数学函数,比如计算平方根、指数、对数、三角函数等,可以帮助我们做各种数学运算。
- random 模块可以生成随机数,帮助我们在编程中模拟随机事件,比如随机选择一个数字或者打乱一个列表中的元素。
- time 模块帮助我们处理时间相关的操作,比如暂停程序一段时间(
sleep()),或者获取当前的时间。 - datetime 模块则更强大一些,它可以让我们处理日期和时间,像是计算两个日期之间的差距,或者格式化显示时间。
- csv 模块用来读写 CSV 文件,这是一种简单的表格数据格式,我们可以通过它来导入和导出数据。
模块的导入
在本教程的初期,我们在学习海龟画图模块turtle过程中,在海龟画图一对模块的导入作了介绍。这里以math模块为例,再次回顾一下导入模块的方式。
- 最基本的导入及调用其中的函数或者对象的方式:
import math
print(math.sqrt(100))
- 带别名
alias的导入及调用其中的函数或者对象的方式:
import math as m
print(m.sqrt(100))
- 从模块中导入特定的函数或者对象:
from math import sqrt
print(sqrt(100))
这里我们再次建议用第二种方式;不建议用第一种方式的原因是有些模块的名字会很长,在编写代码时应用起来不太方便;而对于第三种方式而言,需要特别注意不要从不同模块导入有相同名字的对象或函数,也不要编写同名的自定义函数,所以在初期学习阶段并不建议。
内建模块
在 Python 中,模块(Module)是一个包含 Python 代码的文件,它提供了许多有用的函数、类、变量和可执行代码,使得我们能够更高效地进行编程。模块的作用是组织代码,将功能封装起来,便于代码复用和管理。
模块简介
- 定义:模块是一个包含 Python 代码的文件,通常以
.py为文件扩展名。 - 作用:模块使得程序更加简洁、可维护和高效。通过模块,可以将不同的功能组织到不同的文件中,从而使代码更加模块化,避免重复代码,并提高可读性。
- 示例:
math、os、sys、datetime、random等都是 Python 中的标准库模块。
Python提供了大量的内建模块供开发者们使用,每一个模块都能在特定的方向上发挥很大的作用。在初级学习阶段,可以先对下面几个相对简单的模块进行学习。
- math 模块提供了很多数学函数,比如计算平方根、指数、对数、三角函数等,可以帮助我们做各种数学运算。
- random 模块可以生成随机数,帮助我们在编程中模拟随机事件,比如随机选择一个数字或者打乱一个列表中的元素。
- time 模块帮助我们处理时间相关的操作,比如暂停程序一段时间(
sleep()),或者获取当前的时间。 - datetime 模块则更强大一些,它可以让我们处理日期和时间,像是计算两个日期之间的差距,或者格式化显示时间。
- csv 模块用来读写 CSV 文件,这是一种简单的表格数据格式,我们可以通过它来导入和导出数据。
模块的导入
在本教程的初期,我们在学习海龟画图模块turtle过程中,在海龟画图一对模块的导入作了介绍。这里以math模块为例,再次回顾一下导入模块的方式。
- 最基本的导入及调用其中的函数或者对象的方式:
import math
print(math.sqrt(100))
- 带别名
alias的导入及调用其中的函数或者对象的方式:
import math as m
print(m.sqrt(100))
- 从模块中导入特定的函数或者对象:
from math import sqrt
print(sqrt(100))
这里我们再次建议用第二种方式;不建议用第一种方式的原因是有些模块的名字会很长,在编写代码时应用起来不太方便;而对于第三种方式而言,需要特别注意不要从不同模块导入有相同名字的对象或函数,也不要编写同名的自定义函数,所以在初期学习阶段并不建议。
math
Python 的 math 模块是一个提供数学运算函数和常量的标准库。它提供了广泛的数学功能,从基本的算术运算到更复杂的高级数学函数,如三角函数、对数函数、复数运算等。对于需要进行数值计算的程序来说,math 模块是一个非常有用的工具。
本教程面向的年龄段偏低,所以这里只介绍一些简单的函数和常量。
常量
math.pi: 圆周率,值约为3.141592653589793math.e: 自然对数的底数,也叫自然常数,值约为2.718281828459045math.inf:表示无穷大math.nan: 表示不是一个数字(NAN)
基本算术运算
在下面介绍的math模块中的函数,基本的算术运算都是在实数范围内的,即所有的数 x都属于 R.
$$ x \in \mathbb{R} $$
| 函数名 | 说明 | 返回值 |
|---|---|---|
sqrt(x) | 返回x的平方根,如果x是负数,会抛出 ValueError | 浮点型 |
pow(x, y) | 返回x的y次方。 | 浮点型 |
fmod(x, y) | 返回x除以y的余数。 | 浮点型 |
ceil(x) | 返回大于等于x的最小整数,向上取整 | 整型 |
floor(x) | 返回小于等于x的最大整数,向下取整 | 整型 |
trunc(x) | 返回x的整数部分,去掉小数部分 | 整型 |
sqrt
上面已经提到过了,math模块只针对实数范围内的数,所以sqrt的参数x必须为正数才可以得出一个返回值。
>>> import math as m
>>> print(m.sqrt(100))
10.0
pow
pow的功能与运算符**相同,但是它只会返回浮点数。
>>> import math as m
>>> print(m.pow(10, 2))
100.0
>>> print(10**2)
100
fmod
fmod的功能与%相同,但是它也只会返回浮点数。
>>> import math as m
>>> print(m.fmod(10, 4))
2.0
>>> print(10%4)
2
另外,运算符%的结果符号是要与除数保持一致的,但fmod则正好相反,返回值的符号与被除数一致。
>>> print(m.fmod(10, -3))
1.0
>>> print(m.fmod(-10, 3))
-1.0
>>> print(10 % (-3))
-2
>>> print(-10 % 3)
2
取整函数 ceil / floor / trunc
需要特别注意的是,这几个对数值取整的函数并不是进行四舍五入,所以不要与内置函数round混淆。
>>> import math as m
>>> print(m.ceil(4.3))
5
>>> print(m.floor(4.7))
4
>>> print(m.trunc(4.22))
4
三角函数
在math模块的三角函数中,参数x以弧度为单位。
常量math.pi代表了数学中的π,一个π 表示角度中的180度。
| 函数名 | 说明 | 返回值 |
|---|---|---|
sin(x) | 返回x的正弦值 | 浮点型 |
cos(x) | 返回x的余弦值 | 浮点型 |
tan(x) | 返回x的正切值 | 浮点型 |
degrees(x) | 将弧度x转换为角度 | 浮点型 |
radians(x) | 将角度x转换为弧度 | 浮点数 |
>>> import math as m
>>> print(m.sin(m.pi / 6)) # 30度角的正弦
0.49999999999999994
>>> print(m.cos(m.pi / 3)) # 60度角的余弦
0.5000000000000001
>>> print(m.tan(m.pi / 4)) # 45度角的正切
0.9999999999999999
>>> print(m.degrees(m.pi))
180.0
>>> print(m.radians(180))
3.141592653589793
time
time模块提供了一些与系统时间、操作系统和时间相关的函数,主要用于执行低级别的时间操作,比如等待或者暂停。
主要函数
time()
返回当前时间的时间戳(以秒为单位)。表示从1970年1月1日以来的秒数。具体的起始小时以时区为主.
import time as t
print(t.time())
sleep(seconds)
使程序暂停指定的秒数。在编写程序时常用于模拟延时、等待某些操作。这个函数没有返回值。
import time as t
print("Start")
t.sleep(2)
print("End")
localtime([seconds])
返回当前本地时间的struct_time对象。如果给定了seconds参数,则将其转换为本地时间,否则返回当前时间。
import time as t
local_time = t.localtime()
print(local_time)
ca_time = t.localtime(1734689541.446833)
print(ca_time)
os模块提供了与操作系统交互的功能,能够处理文件和目录的创建、删除、路径操作等。
常用功能
- os.name: 获取操作系统的名称。
posix表示类Unix系统,nt表示Windows系统。
>>> import os
>>> print(os.name)
- os.getcwd():获取当前工作目录。
>>> print(os.getcwd())
- os.chdir(path):改变当前的工作目录,
chdir即change directory.
>>> os.chdir('/Users/chris/Downloads')
- os.listdir(path):列出指定路径下的文件和目录。
>>> print(os.listdir('/Users/chris/Downloads'))
- os.mkdir(path)和 os.makedirs(path):创建单个目录和创建级联目录(递归创建)
>>> os.mkdir("ABC")
>>> os.makedirs("A/B/C")
- os.remove(path)和os.rmdir(path):
os.remove用于删除文件,os.rmdir用于删除空目录
>>> os.remove('C/testing.txt')
>>> os.rmdir('C')
- os.rename(old_name, new_name):重命名文件或目录
>>> os.rename('ABC', 'DEF')
- os.system(command):执行操作系统的命令。返回值是命令的退出状态码。
>>> os.system("shutdown -h")
>>> os.system("echo Hello World")
>>> os.system("mkdir HIJ")
- os.path 模块
os.path模块是os模块的子模块,提供了处理路径的函数。 -os.path.join(): 拼接路径。 -os.path.exists():检查路径是否存在。 -os.path.isdir():检查路径是否为目录。 -os.path.isfile():检查路径是否为文件。 -os.path.abspath():获取绝对路径。
Python 中的面向对象编程(Object-Oriented Programming, OOP)是一种编程范式(paradigm),它通过类和对象的概念来组织代码,使代码更具模块化、可重用性和可扩展性。
比如:一只小猫就是一个对象
- 属性:毛色、名字、年龄
- 行为:喵喵叫、跳跃、吃饭
1. 面向对象编程的核心概念
面向对象编程的核心概念在于类和对象
类:模具的说明书,比如汽车类、动物类、学生类
对象:就像通过模具的说明书制造的实际汽车,每一辆车都是一个对象。
类 Class
- 类是创建对象的模板或蓝图,用来定义对象的属性和行为
- 使用关键字
class定义类
对象 object
- 对象是类的实例或实体,是类实际创建出来的实体。
- 对象包含了属性和方法
2. 创建第一个类:人物类
定义类
class Person:
pass
创建对象
person1 = Person()
person2 = Person()
类就是模板Model, person1和 person2是由这个Model 创建的对象
为类添加属性
类的属性(Class Attributes) 是指类内部定义的变量,它可以被类的所有对象(object<实例instance>)共享。对于一个Person来说,它需要有的具体属性有名字、年龄等。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
__init__是类的构造方法(constrctor), 用于在类的对象被创建时自动调用,完成对象的初始化操作。init是initialize的缩写。self表示这个对象本身, 主要作用是允许类的对象访问和修改对象的属性。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def greet(self):
print(f"Nice to meet you. My name is {self.name} and I'm {self.age} years old.")
示例
题目 1:计算圆的属性
要求:
创建一个类 Circle,用来表示一个圆。该类应包含以下功能:
- 初始化方法,接受半径作为参数。
- 一个方法
area(),返回圆的面积(用math.pi)。 - 一个方法
circumference(),返回圆的周长。
提示:
使用 random.randint() 生成随机数。
from math import pi
class Circle:
def __init__(self, radius):
self._radius_ = radius
def area(self):
a = pi * self._radius_ * self._radius_
return a
def circumference(self):
return 2 * pi * self._radius_
题目 2:计时器类
要求:
创建一个类 Timer,实现以下功能:
- 初始化方法,不需要参数。
- 一个方法
start(),记录当前时间为开始时间。 - 一个方法
stop(),记录当前时间为结束时间,并计算间隔时间。 - 一个方法
elapsed(),返回计时器运行的总时长,单位为秒。
提示:
使用 time.time() 获取当前时间戳。
import time
class Timer:
def __init__(self):
self.stime = 0
self.etime = 0
self.duration = 0
def start(self):
self.stime = time.time()
def stop(self):
self.etime = time.time()
self.duration = self.etime - self.stime
def elapsed(self):
return self.duration
t = Timer()
t.start()
time.sleep(2)
t.stop()
print(t.elapsed())
题目 3:倒计时工具
要求:
创建一个类 Countdown,实现一个简单的倒计时功能:
- 初始化方法,接受倒计时的秒数作为参数。
- 一个方法
start(),从指定的秒数开始倒计时到 0,每秒打印当前剩余秒数(用time.sleep(1))。 - 倒计时结束后打印
"Time's up!"。
提示:
使用 time.sleep() 来暂停 1 秒。
import time
class Countdown:
def __init__(self, sec):
self.second = sec
def start(self):
for i in range(self.second, -1, -1):
print(i)
time.sleep(1)
print("Time's up!")
Python 中的面向对象编程(Object-Oriented Programming, OOP)是一种编程范式(paradigm),它通过类和对象的概念来组织代码,使代码更具模块化、可重用性和可扩展性。
比如:一只小猫就是一个对象
- 属性:毛色、名字、年龄
- 行为:喵喵叫、跳跃、吃饭
1. 面向对象编程的核心概念
面向对象编程的核心概念在于类和对象
类:模具的说明书,比如汽车类、动物类、学生类
对象:就像通过模具的说明书制造的实际汽车,每一辆车都是一个对象。
类 Class
- 类是创建对象的模板或蓝图,用来定义对象的属性和行为
- 使用关键字
class定义类
对象 object
- 对象是类的实例或实体,是类实际创建出来的实体。
- 对象包含了属性和方法
2. 创建第一个类:人物类
定义类
class Person:
pass
创建对象
person1 = Person()
person2 = Person()
类就是模板Model, person1和 person2是由这个Model 创建的对象
为类添加属性
类的属性(Class Attributes) 是指类内部定义的变量,它可以被类的所有对象(object<实例instance>)共享。对于一个Person来说,它需要有的具体属性有名字、年龄等。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
__init__是类的构造方法(constrctor), 用于在类的对象被创建时自动调用,完成对象的初始化操作。init是initialize的缩写。self表示这个对象本身, 主要作用是允许类的对象访问和修改对象的属性。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def greet(self):
print(f"Nice to meet you. My name is {self.name} and I'm {self.age} years old.")
示例
题目 1:计算圆的属性
要求:
创建一个类 Circle,用来表示一个圆。该类应包含以下功能:
- 初始化方法,接受半径作为参数。
- 一个方法
area(),返回圆的面积(用math.pi)。 - 一个方法
circumference(),返回圆的周长。
提示:
使用 random.randint() 生成随机数。
from math import pi
class Circle:
def __init__(self, radius):
self._radius_ = radius
def area(self):
a = pi * self._radius_ * self._radius_
return a
def circumference(self):
return 2 * pi * self._radius_
题目 2:计时器类
要求:
创建一个类 Timer,实现以下功能:
- 初始化方法,不需要参数。
- 一个方法
start(),记录当前时间为开始时间。 - 一个方法
stop(),记录当前时间为结束时间,并计算间隔时间。 - 一个方法
elapsed(),返回计时器运行的总时长,单位为秒。
提示:
使用 time.time() 获取当前时间戳。
import time
class Timer:
def __init__(self):
self.stime = 0
self.etime = 0
self.duration = 0
def start(self):
self.stime = time.time()
def stop(self):
self.etime = time.time()
self.duration = self.etime - self.stime
def elapsed(self):
return self.duration
t = Timer()
t.start()
time.sleep(2)
t.stop()
print(t.elapsed())
题目 3:倒计时工具
要求:
创建一个类 Countdown,实现一个简单的倒计时功能:
- 初始化方法,接受倒计时的秒数作为参数。
- 一个方法
start(),从指定的秒数开始倒计时到 0,每秒打印当前剩余秒数(用time.sleep(1))。 - 倒计时结束后打印
"Time's up!"。
提示:
使用 time.sleep() 来暂停 1 秒。
import time
class Countdown:
def __init__(self, sec):
self.second = sec
def start(self):
for i in range(self.second, -1, -1):
print(i)
time.sleep(1)
print("Time's up!")
Python 中的面向对象编程(Object-Oriented Programming, OOP)是一种编程范式(paradigm),它通过类和对象的概念来组织代码,使代码更具模块化、可重用性和可扩展性。
比如:一只小猫就是一个对象
- 属性:毛色、名字、年龄
- 行为:喵喵叫、跳跃、吃饭
1. 面向对象编程的核心概念
面向对象编程的核心概念在于类和对象
类:模具的说明书,比如汽车类、动物类、学生类
对象:就像通过模具的说明书制造的实际汽车,每一辆车都是一个对象。
类 Class
- 类是创建对象的模板或蓝图,用来定义对象的属性和行为
- 使用关键字
class定义类
对象 object
- 对象是类的实例或实体,是类实际创建出来的实体。
- 对象包含了属性和方法
2. 创建第一个类:人物类
定义类
class Person:
pass
创建对象
person1 = Person()
person2 = Person()
类就是模板Model, person1和 person2是由这个Model 创建的对象
为类添加属性
类的属性(Class Attributes) 是指类内部定义的变量,它可以被类的所有对象(object<实例instance>)共享。对于一个Person来说,它需要有的具体属性有名字、年龄等。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
__init__是类的构造方法(constrctor), 用于在类的对象被创建时自动调用,完成对象的初始化操作。init是initialize的缩写。self表示这个对象本身, 主要作用是允许类的对象访问和修改对象的属性。
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def greet(self):
print(f"Nice to meet you. My name is {self.name} and I'm {self.age} years old.")
示例
题目 1:计算圆的属性
要求:
创建一个类 Circle,用来表示一个圆。该类应包含以下功能:
- 初始化方法,接受半径作为参数。
- 一个方法
area(),返回圆的面积(用math.pi)。 - 一个方法
circumference(),返回圆的周长。
提示:
使用 random.randint() 生成随机数。
from math import pi
class Circle:
def __init__(self, radius):
self._radius_ = radius
def area(self):
a = pi * self._radius_ * self._radius_
return a
def circumference(self):
return 2 * pi * self._radius_
题目 2:计时器类
要求:
创建一个类 Timer,实现以下功能:
- 初始化方法,不需要参数。
- 一个方法
start(),记录当前时间为开始时间。 - 一个方法
stop(),记录当前时间为结束时间,并计算间隔时间。 - 一个方法
elapsed(),返回计时器运行的总时长,单位为秒。
提示:
使用 time.time() 获取当前时间戳。
import time
class Timer:
def __init__(self):
self.stime = 0
self.etime = 0
self.duration = 0
def start(self):
self.stime = time.time()
def stop(self):
self.etime = time.time()
self.duration = self.etime - self.stime
def elapsed(self):
return self.duration
t = Timer()
t.start()
time.sleep(2)
t.stop()
print(t.elapsed())
题目 3:倒计时工具
要求:
创建一个类 Countdown,实现一个简单的倒计时功能:
- 初始化方法,接受倒计时的秒数作为参数。
- 一个方法
start(),从指定的秒数开始倒计时到 0,每秒打印当前剩余秒数(用time.sleep(1))。 - 倒计时结束后打印
"Time's up!"。
提示:
使用 time.sleep() 来暂停 1 秒。
import time
class Countdown:
def __init__(self, sec):
self.second = sec
def start(self):
for i in range(self.second, -1, -1):
print(i)
time.sleep(1)
print("Time's up!")
继承inherit是对现有的类的扩展(extension),实现对代码的重用和重写。
被继承的类叫作父类(Super Class 或 Parent Class), 继承的类叫子类(Subclass 或 Child).
- 父类就像是一个
基础模板 base model或者蓝图 blue print,比如动物类 - 子类继承父类后,它自动拥有了父类的特性,但是可以添加更多的特性,或者修改父类的特性。例如
动物类的子类可以猫类或狗类,它们都继承了动物类的行为,但是也有自己独特的行为。
对于已经创建好的并开始被使用的类 ClassA 来说,有了新的要求需要做更改,但是对于ClassA来说,已经有对象创建了,并且这些对象并不需要新加的功能,所以需要用到继承来解决问题。
继承动物类
在继承动物类之前,首先要有一个动物类才可以继承:
class Animal:
def __init__(self, name, sound):
self.name = name
self.sound = sound
def speak(self):
print(f"{self.name} makes a {self.sound} sound.")
animal = Animal('Tony', 'roar')
animal.speak()
有了动物类之后,就可以实现继承了,下面用小狗类举例
class Dog(Animal):
pass
dog = Dog('Odie', 'bark')
dog.speak()
子类对父类的扩展
在上面的例子中,Dog类完全继承了父类的属性和方法,在这个基础上, Dog也可以对父类进行扩展,比如新一个功能catch。
class Dog(Animal):
def catch(self, obj):
print(f"I caught a {obj} that thrown by my master.")
dog = Dog('Odie', 'bark')
dog.speak()
``
方法的重写
有时候,子类需要对父类的行为(方法)进行修改,这叫做重写(Override)。
class Cat(Animal):
def speak(self):
print(f"{self.sound}, {self.sound}")
重写之后,Cat的speak方法与父类已经完全不一样了
cat = Cat("Garfield", 'Meow~')
cat.speak()
# 打印结果为:Meow~, Meow~
重写可以针对父类的所有资源:
class Cat(Animal):
def __init__(self, color):
self.color = color
def speak(self):
print(f"{self.sound}, {self.sound}")
对于上面的继承方式,Cat类放弃了父类的两个属性name和sound, 这样一来,Cat类里的speak方法就不能被成功调用。
如果在重写时想要保留父类原有的功能或属性,需要用到super关键字。
class Cat(Animal):
def __init__(self, name, sound, color):
super().__init__(name, sound)
self.color = color
def speak(self):
super().speak()
print(f"{self.sound}, {self.sound}")
方法的重写需要特别注意两个点:
- 重写时,需要完全继承父类方法,super()的
.之后的名字要写正确。 - 不要忘记需要带入的参数,以及传值顺序。
完整的例子如下:
class Animal:
def __init__(self, name, sound):
self.name = name
self.sound = sound
def speak(self):
print(f"{self.name} makes a {self.sound} sound.")
def run(self):
print("I am running.")
def eat(self, food):
print(f"I am eating {food}.")
class Cat(Animal):
def __init__(self, name, sound, color):
super().__init__(name, sound)
self.color = color
def speak(self):
super().speak()
print(f"{self.sound}, {self.sound}")
def eat(self, food):
super().run()
print("Clean my face and hand")
super().eat(food)
print("Drink water.")
多继承
多继承指的是一个类可以从多个父类继承属性和方法。
多继承的语法为:
class ChildClass(ParentClass1, ParentClass2, ...):
pass
下面是一个全新的动物类
class Animal:
def alive(self):
print("I am alive")
def eat(self, food):
print("I must eat to be alive.")
然后创建一个鸟类:
class Bird:
def __init__(self):
self.wings = 2
self.legs = 2
def fly(self):
print("I can fly.")
对于小鸡,它既是动物又是鸟类,所以它可以多继承上面两个父类
class Chicken(Animal, Bird):
pass
在多继承的过程中,如果需要在重写或者扩展函数时,需要用super关键字来调用父类的方法,与单继承类似,但是需要特别注意,如果两个父类有同名方法,要掌握 MRO 的查找逻辑。
MRO(Method Resolution Order)
当子类调用方法时,Python 会按照MRO中的顺序去查找方法,这样可以保证类的层次结构的正确性。
MRO的规则:
- 深度优先: Python 首先会从左到右查找父类
- 从子类开始:搜索是从当前类开始的,如果当前类没有该方法或属性,就查找父类
在实例应用中,如果对这个顺序不清楚,可以调用mro()或 __mro__查看 MRO顺序
print(Chicken.__mro__)
# 打印结果为: (<class '__main__.Chicken'>, <class '__main__.Animal'>, <class '__main__.Bird'>, <class 'object'>)
如果多继承中的多个父类有同名方法的情况,就需要MRO机制来确定最终执行的是哪个类里的方法:
class A:
def speak(self):
print('A is speaking.')
class B:
def speak(self):
print('B is speaking.')
class C(A, B):
pass
c = C()
c.speak()
#打印结果: A is speaking.
如果需要手动改变顺序,也就是说需要强制让子类重写父类里的重名方法,并且不按照MRO规则调用,需要特别写明父类的名字的调用,并且要传递参数self, 这种调用叫做显式Explicit调用:
class C(A, B):
def speak(self):
B.speak(self)
A.speak(self)
钻石继承问题(Diamond Problem)
在多继承中,如果一个类继承了两个父类,而这个父类又继承自同一个祖先类,可能会遇到所谓的钻石继承问题:
# 祖先类 A
class A:
def speak(self):
print('A is speaking.')
# 父类 B
class B(A):
def speak(self):
super().speak()
print('B is speaking.')
# 父类 C
class C(A):
def speak(self):
super().speak()
print('C is speaking.')
# 子类 D
class D(B, C):
def speak(self):
super().speak()
print('D is speaking.')
print(D.__mro__)
d = D()
d.speak()
"""
执行结果为:
A is speaking.
C is speaking.
B is speaking.
D is speaking.
"""
练习

class Student:
def __init__(self, name, scores):
self.name = name
self.scores = scores
class Scholar(Student):
def average_score(self):
return sum(self.scores)/len(self.scores)
scholar = Scholar('Jack', [100, 98, 92, 97, 99])
print(scholar.average_score())

class Student:
def __init__(self, name, scores):
self.name = name
self.scores = scores
class AdvancedStudent(Student):
def average_score(self):
return sum(self.scores)/len(self.scores)
class Scholar(AdvancedStudent):
def average_score(self):
return (sum(self.scores)-min(self.scores))/(len(self.scores)-1)
scholar = Scholar('Jack', [100, 98, 92, 97, 99])
print(scholar.average_score())
在Python中,自定义异常是指用户根据需求创建的异常类。通常自定义异常会继承自Exception类或其子类。
语法结构 syntax
- 直接抛出异常, 这种方式针对异常一种简单处理,不需要过于复杂地对错误进行处理和提醒。
raise Exception("description")
try:
a = "a"
b = 0
if a+b!=100:
raise Exception("a+b is not 100")
c = a / b
except ValueError:
print("赋值错误!")
except ZeroDivisionError:
print("除数不能为零!")
except:
print("其它异常")
- 继承
Exception类,还是上面的例子,对于两个数的异常提醒要求比较详细,可以通过继承类来解决
# 示例
class ValidationError(Exception):
def __init__(self, message, value):
self.message = message
self.value = value
super().__init__(self.message)
def __str__(self):
return f"{self.message}: {self.value}"
class SummaryError(Exception):
def __init__(self, message, a, b):
self.message = message
self.a = a
self.b = b
super().__init__(self.message)
def __str__(self):
return f"The summary must be 100, but {a}+{b} = {a+b}"
try:
a = int(input('Input a:'))
b = int(input('Input b:'))
if a+b!=100:
raise SummaryError('a+b must be 100',a, b)
c = a / b
except TypeError:
print("You assigned a wrong type.")
except ZeroDivisionError:
print("Divisor is zero.")
except Exception as e:
print(e)
else:
print("c的值为:",c)
finally:
print("程序结束!")
模块
模块(module) 是一个Python文件(扩展名为.py),它包含了函数、类、变量以及可执行的代码。模块的作用是代码复用、结构化管理和减少重复代码。
创建模块
要创建一个模块的过程就是写 Python程序的过程。比如,将下面代码保存成文件名为MyModule.py,那么这个文件就是一个模块:
print("hello, world")
对于上面的模块来讲,它的内容很简单,并且是可以立即执行的一行代码,这意味着,这个模块在被导入时就会执行。
尝试创建另外一个Python文件Testing.py,将这个模块导入:
import MyModule
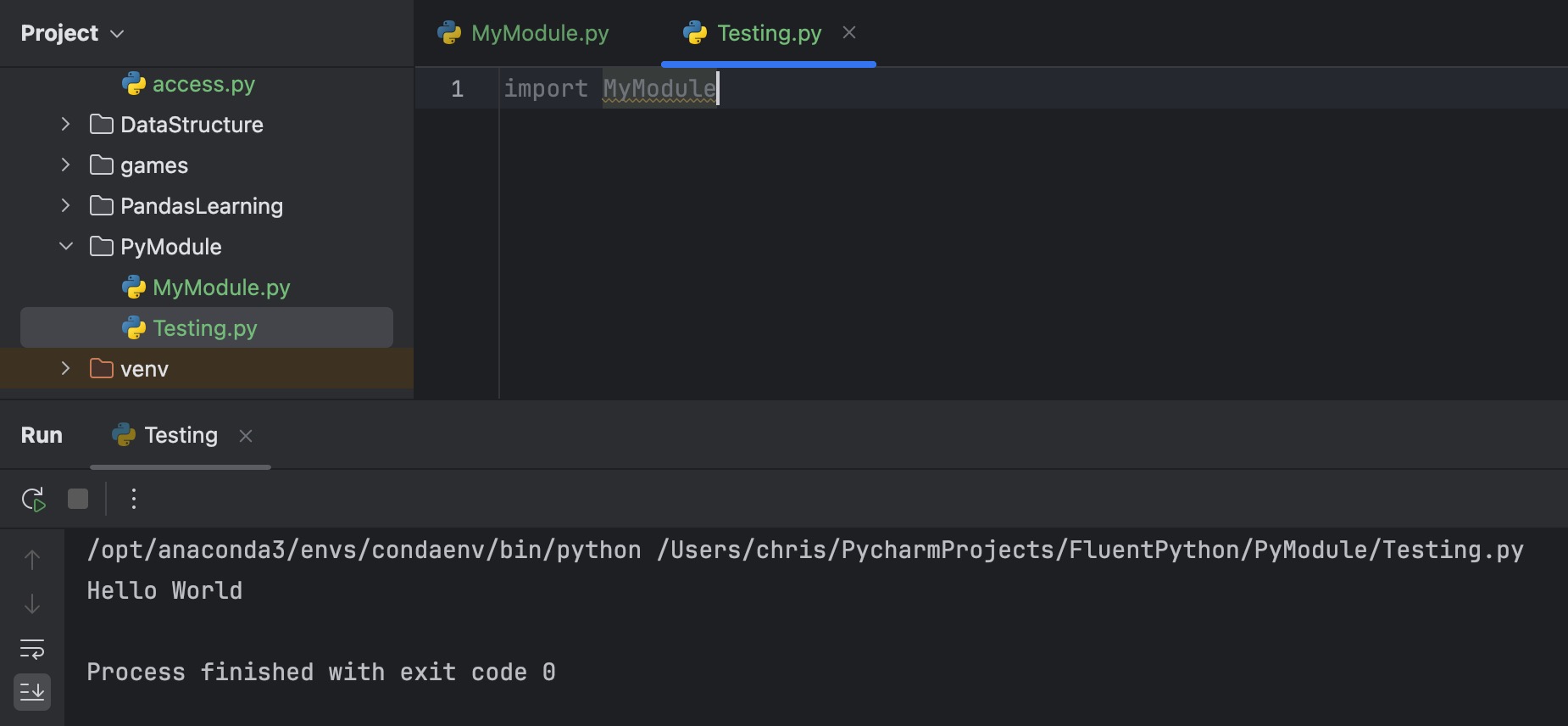
导入模块
在上一个部分,已经对导入模块有了认识,但是导入模块的方式主要有四种:
import module
import math
print(math.sqrt(16)) # 4.0
from module import item(不推荐)
from math import sqrt
print(sqrt(16))
这种方式在调用时不需要通过.去调用。
from module import *(强烈不推荐)
from math import *
print(sqrt(16))
print(pi)
print(sin(1))
⚠️ 注意:不推荐使用 import *,因为可能会导致名称冲突。
import module as alias(重命名模块)
import math as m
from math import sqrt as s
print(m.sqrt(16))
print(s(16))
如何避免模块导入后,执行不必要的代码。
- 第一种方式就是,在编写可能被导入的模块时,不要写那些可以直接被执行的代码,只写需要被调用的函数、类、变量。
"""
模块名为 MyModule.py
"""
pi = 3.14
def area(r):
return r*r*pi
class Shape:
def __init__(self, type):
self.type = type
def myname(self):
return self.type
"""
模块名为 Testing.py
"""
import MyModule as m
"""
如果这个文件到些结束,那么不会执行任何导入模块之外的代码,如果要执行模块中的代码,要在下面调用
"""
print(m.pi)
print(m.area(10))
s = m.Shape("Circle")
print(s.myname())
- 通过
if __name__ == '__main__':方式将被导入模块内可立即执行的代码限制为只在本模块下执行:
"""
模块名为 MyModule.py
"""
pi = 3.14
def area(r):
return r*r*pi
class Shape:
def __init__(self, type):
self.type = type
def myname(self):
return self.type
if __name__ == '__main__':
print(pi)
print(area(10))
s = Shape("Circle")
print(s.myname())
模块
模块(module) 是一个Python文件(扩展名为.py),它包含了函数、类、变量以及可执行的代码。模块的作用是代码复用、结构化管理和减少重复代码。
创建模块
要创建一个模块的过程就是写 Python程序的过程。比如,将下面代码保存成文件名为MyModule.py,那么这个文件就是一个模块:
print("hello, world")
对于上面的模块来讲,它的内容很简单,并且是可以立即执行的一行代码,这意味着,这个模块在被导入时就会执行。
尝试创建另外一个Python文件Testing.py,将这个模块导入:
import MyModule
导入模块
在上一个部分,已经对导入模块有了认识,但是导入模块的方式主要有四种:
import module
import math
print(math.sqrt(16)) # 4.0
from module import item(不推荐)
from math import sqrt
print(sqrt(16))
这种方式在调用时不需要通过.去调用。
from module import *(强烈不推荐)
from math import *
print(sqrt(16))
print(pi)
print(sin(1))
⚠️ 注意:不推荐使用 import *,因为可能会导致名称冲突。
import module as alias(重命名模块)
import math as m
from math import sqrt as s
print(m.sqrt(16))
print(s(16))
如何避免模块导入后,执行不必要的代码。
- 第一种方式就是,在编写可能被导入的模块时,不要写那些可以直接被执行的代码,只写需要被调用的函数、类、变量。
"""
模块名为 MyModule.py
"""
pi = 3.14
def area(r):
return r*r*pi
class Shape:
def __init__(self, type):
self.type = type
def myname(self):
return self.type
"""
模块名为 Testing.py
"""
import MyModule as m
"""
如果这个文件到些结束,那么不会执行任何导入模块之外的代码,如果要执行模块中的代码,要在下面调用
"""
print(m.pi)
print(m.area(10))
s = m.Shape("Circle")
print(s.myname())
- 通过
if __name__ == '__main__':方式将被导入模块内可立即执行的代码限制为只在本模块下执行:
"""
模块名为 MyModule.py
"""
pi = 3.14
def area(r):
return r*r*pi
class Shape:
def __init__(self, type):
self.type = type
def myname(self):
return self.type
if __name__ == '__main__':
print(pi)
print(area(10))
s = Shape("Circle")
print(s.myname())
包
包(Package) 是Python组织模块的方式。简单来说,包就是一个包含多个模块的文件夹,并且这个文件夹中必须包含一下__init__.py文件(Python 3.3之前是必须required/mandatory,后面版本变为可选optional)
优点:
- 避免模块命名冲突:不同的包可以有相同名字的模块
- 模块组织更清晰:便于管理大型项目
- 支持层次结构:可以创建子包
创建包 Package
一个包的架构大致如下:
mypackage /
|-- __init__.py
|-- module1.py
|-- module2.py
|-- subpackage
|-- __init__.py
|-- submodule.py
__init__.py 的作用
- 使
Python识别 identifyMyPackage目录为包 - 可以用于执行初始化代码,例如导入包内的特定模块
如上图,MyModule.py在MyPackage包内:
# __init__.py
print('MyPackage is imported.')
- 控制
from MyPackage import *的行为
如何在一个包中导入另一个包的模块
需要借助sys和os两个模块
import sys
import os
sys.path.append(os.path.dirname(os.path.dirname(__file__)))
import MyPackage.MyModule as m
print(m.__name__)
print(__name__)
print(m.pi)
print(m.area(10))
s = m.Shape("Circle")
print(s.myname())
安装pip
- 安装第三方包,第三方是指除了开发人员本身和已经下载的
Python之外的人提供的包
pip install requests
一、填空题(Fill in the Blanks)
- 在 Python 中,
print(10 // 3)的结果是__3__。 list.append(x)方法的作用是将x添加到列表的__末尾(tail)__。- 在 Python 中,
__def__关键字用 append于定义一个函数。 lambda x: x * 2定义了一个__函数(function)__。my_dict = {}创建的是一个__字典(dict/dictionary)__类型的数据结构。try-except结构用于__异常(exception)__处理。- Python 的
for循环可以用于__可迭代(iterable)__数据结构,如列表、字符串等。 my_tuple = (1, 2, 3),my_tuple[0] = 10会__失败__(成功 / 失败)。is运算符用于比较两个对象的__identity__,而==运算符用于比较两个对象的__值(value)__。import random用于导入__随机(random)__模块,该模块提供随机数生成功能。
1. 考核运算符的应用;
对于除法运算的结果都是浮点数,只有一种例外,就是参与整除运算的两个都是 int 类型的数据,结果一定是 int 类型。
2. 考核的是列表的方法
3. 关键字
4. 匿名函数
5. 考核的点为空字典与空集合的区别;
空字典的表示方式为`{}`,而空集合的表式方式为`set()`
6. 异常
7. 对于可迭代对象的理解
8. 对于元组的理解,是否改更新
9. is 比较两个对象的身份,或者直接理解的话,就是检验两个对象是不是使用了同一块内存
但是Python 有一个特殊的机制,叫小整数池 (small integer pool),范围在`-5 ~256`之间的整数会被认为成小整数,它们的取值都是从缓存里取的。
也就是说,对于1来讲,假设它在缓存的地址为 `0xabcd`,那么当有变量被赋值为1时,都是将这个1从小整数池里取出来赋值,再将1赋值给后来的变量时,会将新的变量指向缓存中的1。
10. 模块的导入。
二、选择题(Multiple Choice Questions)
-
以下哪个 Python 代码会导致 SyntaxError? B A)
print("Hello, World!")
B)x = 5 +
C)if x == 10:
D)list.append(10) -
在 Python 中,哪种数据结构是不可变的? B A)
list
B)tuple
C)set
D)dictionary -
以下代码的输出是什么? B
x = [1, 2, 3] y = x y.append(4) print(x)A)
[1, 2, 3]
B)[1, 2, 3, 4]
C)Error
D)[1, 2] -
下面哪个方法用于从字典
my_dict中安全地获取键key的值,如果键不存在,则返回None? B A)my_dict[key]
B)my_dict.get(key)
C)my_dict.fetch(key)
D)my_dict.retrieve(key) -
bool([])的值是什么? B A)True
B)False
C)None
D)ErrorPython中所有的假值: a).Noneb).Falsec).0-- 所有数值类型的0(包括int、float) d). 空的序列:""、[]、()e). 空的集合:{}、set()、dict()f). 空的range,如range(0),range(10, 0)g).bytes和bytearry的空对象b""和bytearry(b"") -
哪条语句用于创建一个继承自
Person类的新类Student? B A)class Student inherits Person:
B)class Student(Person):
C)Student = class(Person):
D)def Student(Person): -
以下代码的输出是什么? B
def func(a, b=2, c=3): return a + b + c print(func(1, c=4))A)
6
B)7
C)8
D)Error -
Python 中的
with open('file.txt', 'r') as f:语句的作用是? C A) 打开文件并锁定,直到程序结束
B) 读取整个文件内容到变量f
C) 确保文件在with代码块执行完后自动关闭
D) 以二进制模式打开文件
三、编程题(Coding Questions)
1. 交换两个变量的值(PCEP 级别)
问题:
编写一个 Python 程序,在不使用第三个变量的情况下交换两个变量的值。
示例输入:
a = 5
b = 10
a = a+b # 15
b = a-b # 5
a = a-b # 10
print(a,b)
示例输出:
a = 10, b = 5
2. 计算 Fibonacci 数列(PCEP 级别)
问题:
编写一个函数 fibonacci(n),返回第 n 个 Fibonacci 数。
示例输入:
print(fibonacci(6))
示例输出:
8
3. 统计字符串中字母出现的次数(PCAP 级别)
问题:
编写一个 Python 程序,统计用户输入的字符串中每个字母出现的次数,并按字母顺序输出。
示例输入:
"hello world"
示例输出:
d: 1
e: 1
h: 1
l: 3
o: 2
r: 1
w: 1
4. 解析 JSON 并提取数据(PCAP 级别)
问题:
Python 提供了 json 模块用于解析 JSON 数据。请编写一个程序,从以下 JSON 数据中提取 name 和 age 信息,并打印出来。
示例 JSON 数据:
{
"name": "Alice",
"age": 25,
"city": "New York"
}
示例输出:
Name: Alice, Age: 25
5. 继承与方法重写(PCAP 级别)
问题:
创建一个 Animal 类,它有一个 speak 方法,默认返回 "Some sound"。然后创建一个 Dog 类,继承 Animal,并重写 speak 方法,使其返回 "Bark!"。
示例输入:
a = Animal()
d = Dog()
print(a.speak())
print(d.speak())
示例输出:
Some sound
Bark!
一、填空题(Fill in the Blanks)
- 在 Python 中,
print(10 // 3)的结果是__3__。 list.append(x)方法的作用是将x添加到列表的__末尾(tail)__。- 在 Python 中,
__def__关键字用 append于定义一个函数。 lambda x: x * 2定义了一个__函数(function)__。my_dict = {}创建的是一个__字典(dict/dictionary)__类型的数据结构。try-except结构用于__异常(exception)__处理。- Python 的
for循环可以用于__可迭代(iterable)__数据结构,如列表、字符串等。 my_tuple = (1, 2, 3),my_tuple[0] = 10会__失败__(成功 / 失败)。is运算符用于比较两个对象的__identity__,而==运算符用于比较两个对象的__值(value)__。import random用于导入__随机(random)__模块,该模块提供随机数生成功能。
1. 考核运算符的应用;
对于除法运算的结果都是浮点数,只有一种例外,就是参与整除运算的两个都是 int 类型的数据,结果一定是 int 类型。
2. 考核的是列表的方法
3. 关键字
4. 匿名函数
5. 考核的点为空字典与空集合的区别;
空字典的表示方式为`{}`,而空集合的表式方式为`set()`
6. 异常
7. 对于可迭代对象的理解
8. 对于元组的理解,是否改更新
9. is 比较两个对象的身份,或者直接理解的话,就是检验两个对象是不是使用了同一块内存
但是Python 有一个特殊的机制,叫小整数池 (small integer pool),范围在`-5 ~256`之间的整数会被认为成小整数,它们的取值都是从缓存里取的。
也就是说,对于1来讲,假设它在缓存的地址为 `0xabcd`,那么当有变量被赋值为1时,都是将这个1从小整数池里取出来赋值,再将1赋值给后来的变量时,会将新的变量指向缓存中的1。
10. 模块的导入。
二、选择题(Multiple Choice Questions)
-
以下哪个 Python 代码会导致 SyntaxError? B A)
print("Hello, World!")
B)x = 5 +
C)if x == 10:
D)list.append(10) -
在 Python 中,哪种数据结构是不可变的? B A)
list
B)tuple
C)set
D)dictionary -
以下代码的输出是什么? B
x = [1, 2, 3] y = x y.append(4) print(x)A)
[1, 2, 3]
B)[1, 2, 3, 4]
C)Error
D)[1, 2] -
下面哪个方法用于从字典
my_dict中安全地获取键key的值,如果键不存在,则返回None? B A)my_dict[key]
B)my_dict.get(key)
C)my_dict.fetch(key)
D)my_dict.retrieve(key) -
bool([])的值是什么? B A)True
B)False
C)None
D)ErrorPython中所有的假值: a).Noneb).Falsec).0-- 所有数值类型的0(包括int、float) d). 空的序列:""、[]、()e). 空的集合:{}、set()、dict()f). 空的range,如range(0),range(10, 0)g).bytes和bytearry的空对象b""和bytearry(b"") -
哪条语句用于创建一个继承自
Person类的新类Student? B A)class Student inherits Person:
B)class Student(Person):
C)Student = class(Person):
D)def Student(Person): -
以下代码的输出是什么? B
def func(a, b=2, c=3): return a + b + c print(func(1, c=4))A)
6
B)7
C)8
D)Error -
Python 中的
with open('file.txt', 'r') as f:语句的作用是? C A) 打开文件并锁定,直到程序结束
B) 读取整个文件内容到变量f
C) 确保文件在with代码块执行完后自动关闭
D) 以二进制模式打开文件
三、编程题(Coding Questions)
1. 交换两个变量的值(PCEP 级别)
问题:
编写一个 Python 程序,在不使用第三个变量的情况下交换两个变量的值。
示例输入:
a = 5
b = 10
a = a+b # 15
b = a-b # 5
a = a-b # 10
print(a,b)
示例输出:
a = 10, b = 5
2. 计算 Fibonacci 数列(PCEP 级别)
问题:
编写一个函数 fibonacci(n),返回第 n 个 Fibonacci 数。
示例输入:
print(fibonacci(6))
示例输出:
8
3. 统计字符串中字母出现的次数(PCAP 级别)
问题:
编写一个 Python 程序,统计用户输入的字符串中每个字母出现的次数,并按字母顺序输出。
示例输入:
"hello world"
示例输出:
d: 1
e: 1
h: 1
l: 3
o: 2
r: 1
w: 1
4. 解析 JSON 并提取数据(PCAP 级别)
问题:
Python 提供了 json 模块用于解析 JSON 数据。请编写一个程序,从以下 JSON 数据中提取 name 和 age 信息,并打印出来。
示例 JSON 数据:
{
"name": "Alice",
"age": 25,
"city": "New York"
}
示例输出:
Name: Alice, Age: 25
5. 继承与方法重写(PCAP 级别)
问题:
创建一个 Animal 类,它有一个 speak 方法,默认返回 "Some sound"。然后创建一个 Dog 类,继承 Animal,并重写 speak 方法,使其返回 "Bark!"。
示例输入:
a = Animal()
d = Dog()
print(a.speak())
print(d.speak())
示例输出:
Some sound
Bark!
PCEP & PCAP 认证相关 Python 题目(中等难度)
填空题(5 题)
- 在 Python 中,
def my_func(*args):语法表示args是一个__可变__类型的参数,用于接收多个位置参数。 - 在 Python 中,
break语句用于__结束/跳出(exit/terminate)__循环,而continue语句用于__跳过(skip)__当前循环的一次执行。 open('data.txt', 'w')以__写入(write)__模式打开文件,如果文件已存在,它会__清空(clear)__之前的内容。- 在
for循环中,如果没有使用break退出循环,则__else__代码块将执行。 - 使用
import math导入math模块后,可以使用__sqrt__计算平方根,例如math.sqrt(9)返回__3.0__。
选择题(5 题)
-
以下哪一项不是 Python 中的合法变量名? B A)
_my_var
B)3variable
C)myVar3
D)var_3 -
在 Python 中,
x = [1, 2, 3]和y = x,执行y.append(4)后,x变成了什么? B A)[1, 2, 3]
B)[1, 2, 3, 4]
C)[1, 2, 3](但y变成[1, 2, 3, 4])
D) 代码报错 -
关于 Python 的
range(5),以下说法正确的是? D A)range(5)生成[0, 1, 2, 3, 4]
B)range(5)生成[1, 2, 3, 4, 5]
C)range(5)生成[0, 1, 2, 3, 4, 5]
D)range(5)生成(0, 1, 2, 3, 4) -
以下 Python 代码的输出是什么? A
def test(a, b=2, c=3): return a + b + c print(test(1, c=4))A)
7
B)8
C)9
D) 代码报错 -
在 Python 中,以下哪种方式可以正确读取
data.txt文件的所有内容? D A)content = open('data.txt').read()
B)with open('data.txt') as f: content = f.read()
C)with open('data.txt', 'r') as f: content = f.read()
D) 以上都正确A选项相当于: f = open('data.txt') content = f.read()
编程题(3 题)
-
请编写一个 Python 函数
count_vowels(s),计算字符串s中的元音字母(a, e, i, o, u)的数量,忽略大小写。
示例输入:"Hello World"
示例输出:3 -
请编写一个 Python 函数
factorial(n),计算正整数n的阶乘(n!)。
示例输入:factorial(5)
示例输出:120 -
请编写一个 Python 代码,使用
while循环打印 1 到 10 的所有奇数。
示例输出:
1
3
5
7
9
这套题目比上一套难度稍低,涵盖了基本数据类型、循环、函数、默认参数、文件操作等核心知识点,适合 PCEP 和 PCAP 学习者练习!🚀
填空题(10 题)
- Python 中,
input()函数用于接收用户的__键盘(keyboard)__输入,返回的是一个__字符串(str)__类型的数据。 - 在 Python 中,
//运算符用于执行__整除(floor division)__除法,返回一个整数结果。 - 在 Python 中,
is运算符用于比较两个对象的__身份(identity)__,而==运算符用于比较对象的__值(value)__。 - Python 中,
None是一个特殊的常量,表示__空值(no value)__。 - Python 中,
__init__()是__构造(Constructor)__方法,在创建对象时会自动调用。 - 在 Python 中,
len()函数用于返回对象的__长度(length)__,例如字符串的长度或列表的元素数量。 - Python 中,
range(1, 5)生成的序列为__1,2,3,4__,包含数字 1 到 4。 - Python 中,
str()函数可以将其他数据类型转换为__字符串(str)__类型。 - Python 中,
del关键字用于删除对象或变量,删除的对象会__被回收(garbage collected)__。 - Python 中,
import语句用于__加载(load)__模块或包。
选择题(10 题)
-
以下哪项是 Python 中的合法标识符? C A)
1variable
B)my_var!
C)_myVar
D)my-var -
在 Python 中,
range(2, 10, 2)生成的序列是? A A)[2, 4, 6, 8]
B)[2, 4, 6, 8, 10]
C)[0, 2, 4, 6, 8]
D)[1, 3, 5, 7, 9] -
以下哪个是 Python 中的布尔值类型? A A)
True
B)Yes
C)1
D)Boolean -
在 Python 中,
x = 5和y = 5,执行x == y时,结果是? A A)True
B)False
C)Error
D)None -
在 Python 中,如何定义一个空集合? B
A){}
B)set()
C)[]
D)None -
在 Python 中,以下哪项会返回
True? D A)bool(0)
B)bool([])
C)bool(None)
D)bool("True") -
以下代码的输出是什么? C
x = "Python" print(x[2:])A)
Pyt
B)Py
C)thon
D)Python -
以下代码中,
append()函数的作用是? Blist = [1, 2, 3] list.append(4)A) 将数字 4 添加到列表的开头
B) 将数字 4 添加到列表的末尾
C) 删除列表中的数字 4
D) 将数字 4 替换列表中的最后一个元素 -
在 Python 中,
is运算符检查两个对象是否具有相同的__B__。
A) 值
B) 地址
C) 类型
D) 长度 -
以下哪一项是 Python 中的内建函数? B A)
add()
B)list()
C)print_all()
D)sum_all()
编程题(10 题)
- 编写一个 Python 函数
reverse_string(s),返回字符串s的反转结果。
示例输入:"hello"
示例输出:"olleh"
def reverse_string(s):
return s[::-1]
- 编写一个 Python 函数
is_prime(n),判断给定整数n是否为质数。
示例输入:5
示例输出:True
def is_prime(n):
if n<2:
return False
for i in range(2,n):
if n % i == 0:
return False
return True
num = int(input("Input a number:"))
if is_prime(num):
print("Yes")
else:
print("No")
flag = True
if n<2:
flag = False
else:
for i in range(2,n):
if n % i == 0:
flag = False
break
if flag:
print("Yes")
else:
print("No")
- 编写一个 Python 函数
sum_of_digits(n),计算一个正整数n的各个数字的和。
示例输入:123
示例输出:6
def sum_of_digits(n):
total = 0
for i in str(n):
total = total + int(i)
return total
-
编写一个 Python 函数
fibonacci(n),返回 Fibonacci 序列中第n个数字。
示例输入:fibonacci(6)
示例输出:8 -
编写一个 Python 函数
find_max(nums),返回给定数字列表nums中的最大值。
示例输入:[3, 5, 2, 8, 6]
示例输出:8
def find_max(nums):
return max(nums)
- 编写一个 Python 函数
even_numbers(nums),返回一个列表,包含列表nums中的所有偶数。
示例输入:[1, 2, 3, 4, 5, 6]
示例输出:[2, 4, 6]
def even_numbers(nums):
lst = []
for i in nums:
if i % 2 == 0:
lst.append(i)
return lst
- 编写一个 Python 函数
remove_duplicates(nums),去除列表nums中的重复元素并返回新的列表。
示例输入:[1, 2, 2, 3, 4, 4, 5]
示例输出:[1, 2, 3, 4, 5]
def remove_duplicates(nums):
return list(set(nums))
-
编写一个 Python 函数
count_occurrences(lst, item),返回item在列表lst中出现的次数。
示例输入:[1, 2, 2, 3, 4, 2],2
示例输出:3 -
编写一个 Python 函数
remove_vowels(s),返回一个删除了所有元音字母的字符串。
示例输入:"hello world"
示例输出:"hll wrld" -
编写一个 Python 函数
factorial(n),计算n!的阶乘。
示例输入:factorial(4)
示例输出:24
综合题(5 题)
-
编写一个 Python 函数
max_diff(nums),返回给定数字列表中最大和最小值的差值。
示例输入:[10, 2, 8, 5, 7]
示例输出:8 -
编写一个 Python 函数
merge_lists(list1, list2),将两个列表合并为一个并返回。
示例输入:[1, 2, 3],[4, 5, 6]
示例输出:[1, 2, 3, 4, 5, 6] -
编写一个 Python 函数
is_palindrome(s),判断一个字符串是否是回文。
示例输入:"racecar"
示例输出:True -
编写一个 Python 函数
common_elements(list1, list2),返回两个列表中共同的元素。
示例输入:[1, 2, 3],[3, 4, 5]
示例输出:[3] -
编写一个 Python 函数
sort_list(nums),返回一个升序排列的数字列表。
示例输入:[3, 1, 2, 5, 4]
示例输出:[1, 2, 3, 4, 5]
PCEP & PCAP Certification Practice Questions
一、单选题(共20题,每题仅一个正确答案)
-
哪一选项可以正确输出字符串的长度?
- A.
len["hello"] - B.
size("hello") - C.
length("hello") - D.
len("hello")✅
- A.
-
以下哪一项是合法的变量名?
- A.
2value - B.
value_2✅ - C.
value-2 - D.
@value
- A.
-
运行以下代码的结果是什么?
print(2 ** 3)- A. 5
- B. 6
- C. 8 ✅
- D. 9
-
以下哪个关键字用于定义函数?
- A.
func - B.
def✅ - C.
function - D.
define
- A.
-
若
x = 5,以下哪条语句可判断 x 是否等于 5?- A.
if x = 5: - B.
if x == 5:✅ - C.
if x === 5: - D.
if x => 5:
- A.
-
哪个不是 Python 的逻辑运算符?
- A.
and - B.
or - C.
not - D.
nor✅
- A.
-
list.append(x)方法的作用是?- A. 返回新的列表
- B. 删除 x
- C. 在末尾添加 x ✅
- D. 在开头插入 x
-
以下哪项不是 Python 的数据类型?
- A.
tuple - B.
list - C.
map✅ - D.
set
- A.
-
以下哪个语句用于捕获异常?
- A.
handle - B.
try-except✅ - C.
error-catch - D.
check
- A.
-
若有字符串
s = "Python",执行s[0]得到?- A.
"P"✅ - B.
"y" - C.
"n" - D. 报错
- A.
-
Python 中,哪个是浮点除法?
- A.
// - B.
/✅ - C.
% - D.
*
- A.
-
以下哪个模块用于生成随机数?
- A.
math - B.
sys - C.
random✅ - D.
os
- A.
-
在函数内部修改全局变量,应使用哪个关键字?
- A.
local - B.
static - C.
global✅ - D.
public
- A.
-
如何定义一个字典?
- A.
[] - B.
() - C.
{}✅ - D.
<>
- A.
-
x = [1, 2, 3],哪条语句可以删除最后一个元素?- A.
x.remove() - B.
x.pop()✅ - C.
del x[0] - D.
x.delete()
- A.
-
如果一个模块名为
math,正确的导入方式是?- A.
import math✅ - B.
load math - C.
using math - D.
require math
- A.
-
类的构造函数方法名是?
- A.
__build__ - B.
__init__✅ - C.
__new__ - D.
__create__
- A.
-
哪个语句用于退出循环?
- A.
exit - B.
stop - C.
break✅ - D.
return
- A.
-
在类中定义方法时,第一个参数通常是?
- A.
this - B.
self✅ - C.
cls - D.
obj
- A.
-
若想让某模块只在直接运行时执行某段代码,正确做法是?
- A.
if __main__ == "__name__": - B.
if __name__ == "__main__":✅ - C.
if name == "main": - D.
if run == True:
- A.
二、多选题(共10题,至少两个选项正确)
-
以下哪些是合法的数据结构?
- A.
list✅ - B.
set✅ - C.
dict✅ - D.
int
- A.
-
以下哪些是 Python 的关键字?
- A.
def✅ - B.
class✅ - C.
import✅ - D.
define
- A.
-
关于字符串的方法,以下哪些是正确的?
- A.
"abc".upper()✅ - B.
"abc".append("d") - C.
"abc".replace("a", "x")✅ - D.
"abc".split()✅
- A.
-
以下哪些属于布尔值操作?
- A.
not✅ - B.
and✅ - C.
or✅ - D.
xor
- A.
-
以下哪些语句会引发异常?
- A.
int("abc")✅ - B.
1 / 0✅ - C.
open("nofile.txt")✅ - D.
print("hello")
- A.
-
以下哪些函数属于内置函数?
- A.
len()✅ - B.
input()✅ - C.
sum()✅ - D.
main()
- A.
-
关于
for循环,以下哪些语法是正确的?- A.
for i in range(5):✅ - B.
for i from 1 to 10: - C.
for item in my_list:✅ - D.
foreach item in my_list:
- A.
-
关于异常处理,以下哪些写法是合法的?
- A.
try: ... except: ... ``` ✅ - B.
try: ... catch: ... - C.
try: ... except ValueError: ... ``` ✅ - D.
raise Exception("Error")✅
- A.
-
以下关于类的说法正确的是?
- A. 类可以有多个方法 ✅
- B. 类可以继承 ✅
- C. 类必须有构造方法
- D. 类是一种对象模板 ✅
-
关于模块的使用,以下哪些是正确的?
- A.
import math✅ - B.
from math import sqrt✅ - C.
require(math) - D.
math.sqrt(4)✅
- A.
进制转换
完整运算符
| 运算符 | 描述 |
|---|---|
[] [:] | 下标,切片 |
** | 指数 |
~ + - | 按位取反, 正负号 |
* / % // | 乘,除,模,整除 |
+ - | 加,减 |
>> << | 右移,左移 |
& | 按位与 |
^ \| | 按位异或,按位或 |
<= < > >= | 小于等于,小于,大于,大于等于 |
== != | 等于,不等于 |
is is not | 身份运算符 |
in not in | 成员运算符 |
not or and | 逻辑运算符 |
= += -= *= /= %= //= **= &= ` | = ^= >>= <<=` |
字面量
字面量是用于表达源码中一个固定值的表示法,整数、浮点数和字符串等等都是字符串。比如在下面声名变量语句中:
a = 1
a是声明的变量,那赋值符=后面的1就是字面量。总之,字面量就是没有用标识符封装起来的量,是“值”的原始状态。
按位取反
在学习按位取反之前,我们要先了解原码、反码和补码。
前面提到过,数值在计算机中的以二进制的方式存储的,但是真正在存储时用的都是二进制补码,且在存储之前先要经过原码->反码->补码的转换过程:
对于一个有符号数(即正、负),它的最高位永远是符号位,0为正数,1为负数。假设我们的一台简易计算机只用一个字节(byte,即8位)来存储数值,那么对于5和-5来说:
原码:
5: 0000 0101
-5: 1000 0101
反码(正数反码即自身,负数则除符号位之外其它各位取反):
5: 0000 0101
-5: 1111 1010
补码(正数补码还是自身,负数则是在反码基础上加1):
5: 0000 0101
-5: 1111 1011
这样设计能够解决加减法不正确的问题
首先,计算十进制的表达式: 1-1=0,看一下原码的计算:
# 原码计算:
0000 0001 + 1000 0001 = 1000 0010
1000 0010转换成十进制之后为-2,这个结果显然是错误的,所以不能直接用原码进行运算。
那么反码会怎样:
# 原码计算:
0000 0001 + 1000 0001
# 反码计算:
0000 0001 + 1111 1110 = 1111 1111
# 转换回原码结果为
1000 0000
1000 0000转换成十进制之后为-0,结果是正确了,但是这个-0看起来又很奇怪,虽然人们可以理解+0和-0是一样的,然而带符号的0并没有什么意义。
使用补码就可以解决上述问题:
# 原码计算:
0000 0001 + 1000 0001
# 反码计算:
0000 0001 + 1111 1110
# 补码计算:
0000 0001 + 1111 1111 = 0000 0000
# 转换回原码结果为
0000 0000
这里有些同学会问,结果不应该是1 0000 0000吗?这里是因为我们假设计算机是用一个字节来存储数值的,一个字节是只有8位的,所以多出的1会被移掉。
现在我们来看一下按位取反是怎么实现的:
-5: 原码:1000 0101 反码:1111 1010: 补码:1111 1011
# 按位取反发生在补码上:
0000 0100
# 由于是正数的补码,和原码是一样的,那么结果就是:
0000 0100 即十进制的4
5: 原码、反码、补码: 0000 0101
# 按位取反后:
1111 1010
# 由于是补码,要先减1得到反码
1111 1001
# 再取反得到原码
1000 0110 即十进制-6
海龟的绝对零度
海龟的方向有两个模式:
| standard模式 | logo模式 |
|---|---|
0 - 东 | 0 - 北 |
90 - 北 | 90 - 东 |
180 - 西 | 180 - 南 |
270 - 南 | 270 - 西 |
海龟模块中的mode()函数可以设置海龟模式 (standard 或 logo) 并执行重置。
import turtle as t
t.seth(45)
t.mode('logo')